3月27日凌晨,阿里通义千问团队正式扔出了一枚重磅冲击波——Qwen2.5-Omni,一个全新的旗舰级多模态大模型。
简单来说,这个模型专为全面感知多种信息而设计,能无缝处理文本、图片、音频、视频等各类输入,同时还支持边接收边生成文本和语音。
那么,它到底能干些什么?最直观的感受是,以后你可以像打电话或视频聊天一样跟AI对话了。相当于同时实现了“语音聊天”和“视频聊天”功能——这在以往的模型中,并不多见。
比产品体验更值得关注的是,团队把支撑这一切的Qwen2.5-Omni-7B模型给开源了。采用的Apache 2.0许可证,意味着开发者、企业可以直接拿去免费商用,连部署到手机这类终端智能硬件上都行。背后的技术细节,也都写进了发布的技术报告里,敞开了分享。

这种级别的开放,引来不少网友感慨:这才是真正的“Open AI”。
具体表现如何,大家可以去官方Demo里亲自体验一番。
Qwen2.5-Omni 模型架构
这次Qwen2.5-Omni的几个特点很值得深挖一下。
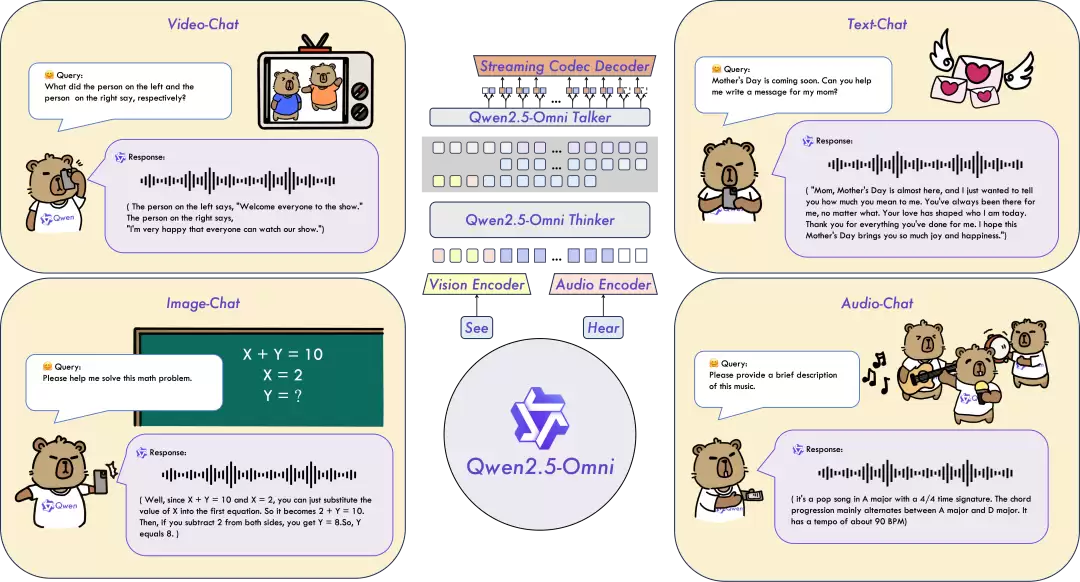
全模态融合与创新架构:团队提出了Thinker-Talker架构,这是一种端到端的多模态模型,核心能力是感知包括文本、图像、音频、视频在内的多种模态数据,同时能以流式的形式生成文本和语音响应。一个亮点是配套的TMRoPE(Time-aligned Multimodal RoPE)位置嵌入方案,专门用于对齐视频输入与音频的时间戳。
实时语音与视频聊天:架构专为真正的实时交互优化,支持分块输入并即时输出,响应速度很快。
自然且稳定的语音生成:在语音生成这块,模型的表现也很有趣——它超越了不少现有的流式甚至非流式方案,质量上的稳健性和自然度都比较突出。
极强多模态性能:在与同体量的单模态模型对比时,Qwen2.5-Omni在各个模态上的表现都相当亮眼。它的音频能力超越了同样大小的Qwen2-Audio,同时图像和视频理解能力也达到了与Qwen2.5-VL-7B相当的水平。
端到端语音指令遵循:模型在端到端的语音指令遵循上,表现几乎可以媲美文本输入。在MMLU和GSM8K这类基准上,数据给出了有力的证明。
前文提到,架构的关键在于Thinker-Talker。顾名思义,Thinker相当于大脑,负责处理理解文本、音频、视频等输入,生成高级表征和文本;而Talker则像嘴巴,以流式方式接收Thinker的这些表征,并顺畅地输出离散的语音token。
具体实现上,Thinker是一个配备音频和图像编码器的Transformer解码器。Talker则被设计成一种双轨自回归Transformer解码器架构。训练和推理时,Talker直接接收来自Thinker的高维表征,并共享所有历史上下文。所以,整体是一个统一的端到端模型,避免了模块间的割裂。
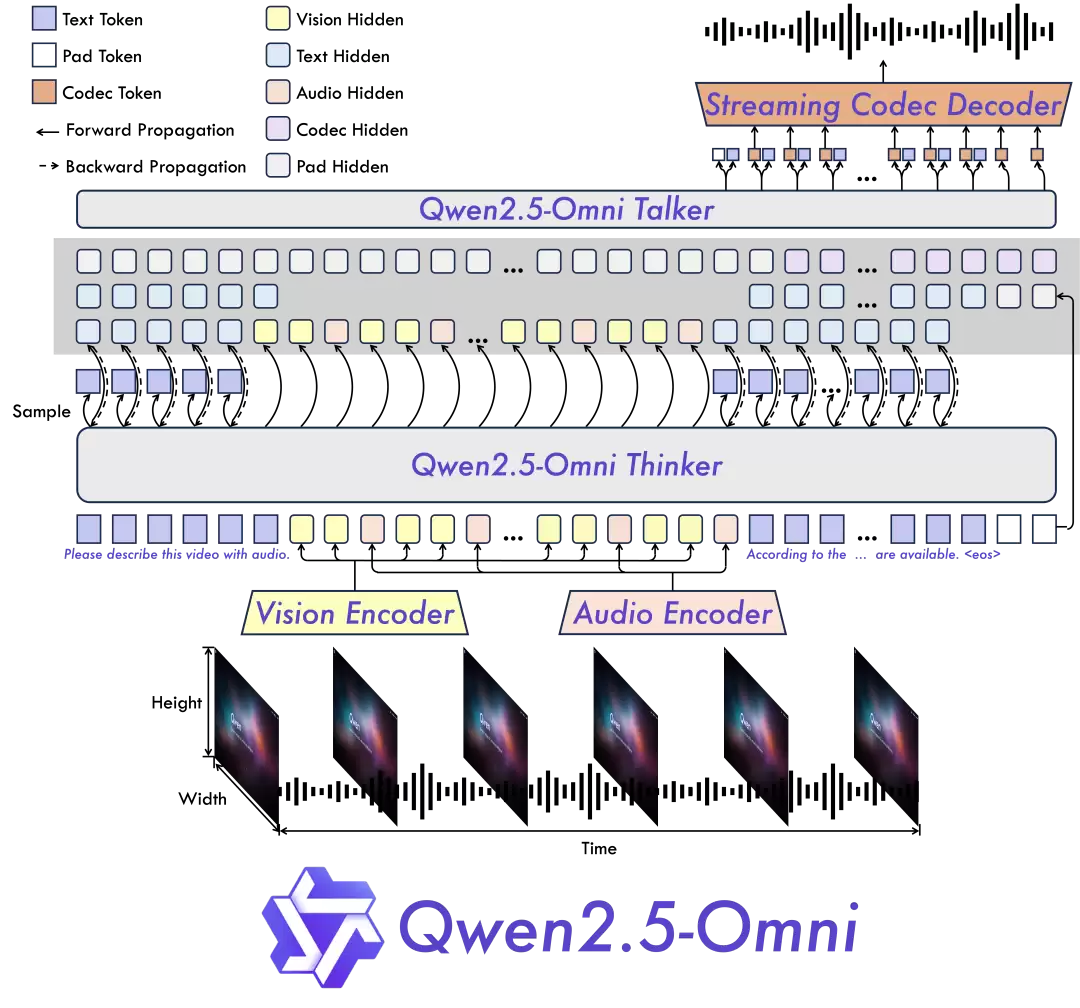 Qwen2.5-Omni 模型架构
Qwen2.5-Omni 模型架构
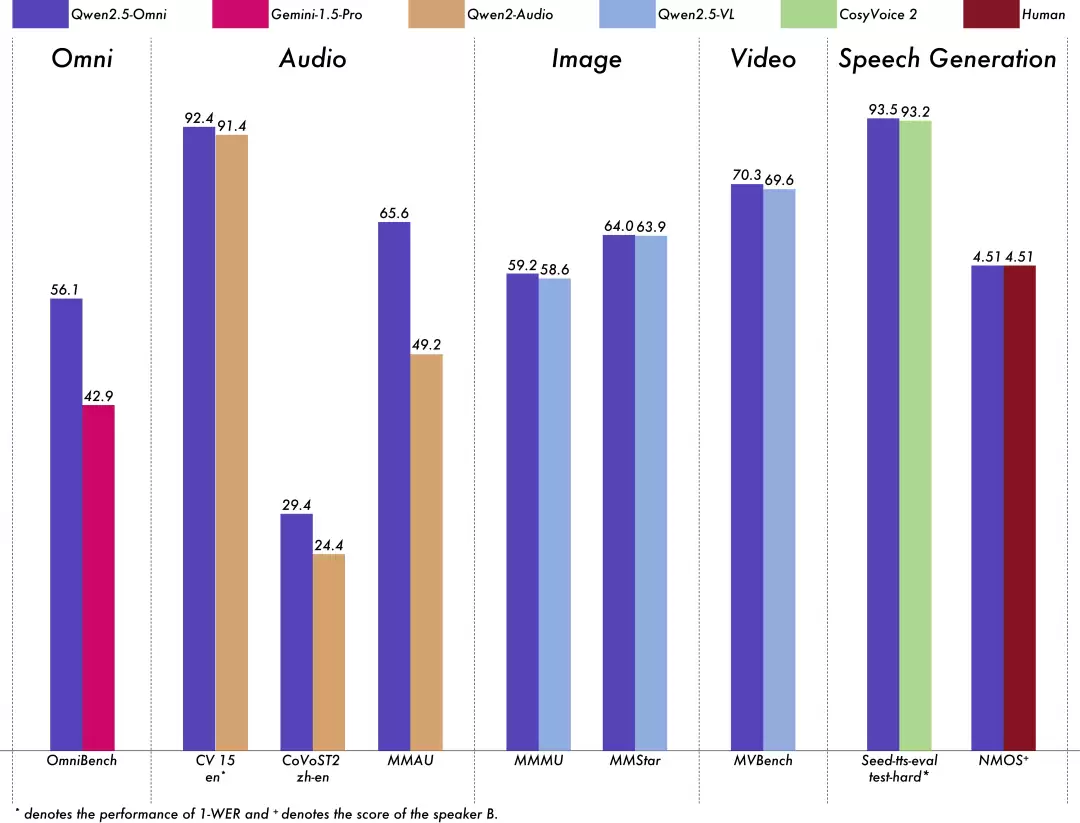
模型性能
团队对Qwen2.5-Omni进行了全面评估,结论是:在所有模态上的表现,都优于同体量的单模态模型,甚至不少闭源模型,比如Gemini-1.5-pro也没能讨到便宜。
特别在需要融合多种模态的综合性任务上,比如OmniBench,模型直接达到了最先进的水平。而在各项单模态任务中,它的表现同样覆盖了多个领域:语音识别(Common Voice)、翻译(CoVoST2)、音频理解(MMAU)、图像推理(MMMU、MMStar)、视频理解(MVBench)以及语音生成(Seed-tts-eval和主观自然度评分等),成绩都相当可观。