人工智能的起源:从围棋对弈到万物互联
2016年3月,谷歌旗下DeepMind的AlphaGo与韩国围棋九段棋手李世石展开世纪对决,最终以4:1的绝对优势锁定胜局。两年后,AlphaStar又在《星际争霸II》中分别以两个5:0横扫多位世界顶级玩家。这些场景至今仍令人印象深刻。但若追溯人工智能的真正起点,其实早在1997年,IBM的“深蓝”就已击败国际象棋特级大师卡斯帕罗夫。不过,国际象棋的复杂度远低于围棋,因此AlphaGo的胜利才被广泛视为“人工智能时代来临”的标志性里程碑。
那么,“人工智能”这个概念究竟由谁提出?时间要回到1955至1956年间,当时达特茅斯学院的助理教授John McCarthy(后来被誉为“人工智能之父”),与哈佛大学的Marvin Minsky、IBM的Claude Shannon以及贝尔实验室的Nathaniel Rochester共同首次定义了“人工智能”:
“如果任何机器能通过某种语言将抽象事务或概念表达出来,并借助这些抽象概念帮助人类解决问题,或者它本身能通过自主学习不断精进,我们就称之为人工智能。”
更直白地说,当机器的行为模式与人类无异时,我们便认为它具备“智能”。
这一定义相当宽泛,也因此催生了极其广阔的应用场景。除了下棋和游戏,自动驾驶领域已有部分地区开放了Level 4级别的测试,真正的Level 5似乎也指日可待。而这一切,除了法律法规的保障,更离不开AI算法的开发者。在物联网领域,传感、智能手机、网络搜索、人脸识别、车牌识别、智能表计、机器视觉、工业控制……AI正变得无处不在,让工作与生活更加便捷和智慧。
市场数据也印证了这一趋势。IDC的统计显示,2020至2021年间,全球AI服务的年复合增长率达到17.4%,预计到2024年将升至18.4%,市场市值接近378亿美元。这其中涵盖定制化应用及相关平台支持与服务,比如深度学习架构、卷积神经网络,以及CPU、GPU、FPGA、TPU、ASIC等AI芯片。
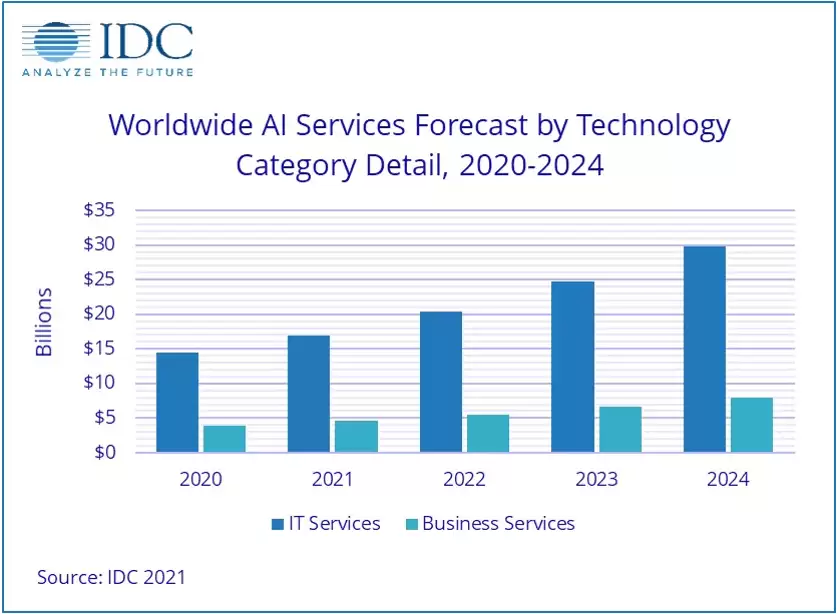
同样来自IDC的数据,全球数据存储量将从2018年的33ZB猛增至2025年的175ZB,其中超过50%来自IoT设备。假如到2025年,全球部署约140亿部IoT设备,我们是否就需要大量增加云端的计算单元和算力,才能应对海量数据增长?
答案是否定的。这种想法忽略了从终端到云端的数据传输链条中带宽和时间延迟等现实挑战。这正是“边缘计算”迅速崛起的原因。最终我们发现,随着IoT设备的激增,单纯增加带宽和服务器数量并非最优解。不少应用完全可以在端侧设备上实现,无需将数据全部上传到云端。例如在工业自动化领域,数据存储距离越近,效率越高。而5G移动设备制造商如果不强化终端侧AI并调整计算-存储架构,将面临严重的电池寿命问题。
隐私安全是另一个不容忽视的环节,尤其是在万物互联的时代,机密资料泄露或黑客入侵的事件屡见不鲜。如果能够将计算置于边缘侧,减少“云-管-端”通路中的数据传递次数,那么,在确保数据与网络安全的同时,也能有效降低功耗和系统总拥有成本。
不同AI芯片对比分析
众所周知,AI技术根据应用分为“训练”和“推理”两大类。训练主要在云端由CPU、GPU、TPU负责执行,目的是不断扩充数据库资源以建立数据模型;推理则更适合边缘装置和特定应用,常由ASIC、FPGA类芯片处理,依托已训练好的模型进行预测。
如前所述,与AI相关的芯片类型包括CPU、GPU、FPGA、TPU、ASIC等。华邦电子闪存产品企划处的黄仲宇从五个维度——算力、软件灵活性、硬件兼容性、功耗和成本——对这些芯片进行了初步比较。
CPU(中央处理器)
CPU发展多年,算力强大,软硬件兼容性首屈一指。但受冯·诺依曼架构限制,数据需要在内存和处理器之间不断往复传输,这限制了处理速度,功耗和成本表现也并非最佳,只能算折中选择。
GPU(图形处理器)
以Nvidia GPU为例,它采用“统一计算设备架构”,拥有大量计算单元,不仅能任意读取内存位置,还能通过虚拟内存的共用加速计算能力。虽然同样受冯·诺依曼架构限制,但其平均算力超过CPU几十倍甚至上千倍。GPU软硬件兼容性好,但功耗和成本仍有改善空间,且需额外硬件投资,例如加装冷却系统。
ASIC芯片
ASIC为特定应用开发,经过验证调整后,在运算能力、功耗和成本方面可达最佳水平。
FPGA
FPGA发展多年,软硬件兼容性值得称赞。整体算力、成本和功耗虽非最优,但也不失为不错的折中方案。对开发者而言,从FPGA入手切入AI芯片开发是一个不错的选择方向。
突破冯·诺依曼架构瓶颈
传统计算设备广泛采用的冯·诺依曼架构,计算和存储功能分离,且更侧重计算。数据在处理器和存储器之间来回传输,消耗了约80%的时间和功耗。学术界为此想出了许多方法,比如通过光互连、2.5D/3D堆叠实现高带宽数据通信,或通过增加缓存级数、利用高密度片上存储的近数据存储技术,来缓解访存延迟和高功耗。
但试想一下,人类大脑有计算和存储的区别吗?我们是用左半球计算、右半球存储的吗?显然不是。人脑的计算和存储发生在同一处,不需要数据迁移。因此,学术界和产业界都希望找到一种类似人脑的创新架构,最好能将存储和计算有机融合,直接利用存储单元进行计算,或将计算单元分类对应不同存储单元,最大程度消除数据迁移带来的功耗开销。“计算存储设备”的概念由此应运而生。
存储业界已有公司提出了值得借鉴的方案。NVM不仅存储经过数模转换器后产生的模拟信号,还能输出算力。输入电压和输出电流在NVM中扮演可变电阻的角色,模拟电流信号经模数转换器变为数字信号,从而完成输入-输出的全过程。这一做法最大的优势是能利用成熟的20/28nm CMOS工艺,无需像CPU/GPU那样追求7nm/5nm的高昂先进制程。伴随成本和功耗的降低,时间延迟特性也显著提升,这对无人机、智能机器人、自动驾驶、安防监控等应用至关重要。
总体来看,终端推理过程计算复杂度低,任务固定,对硬件加速功能的通用性要求不高,无需频繁变动架构,更适合存内计算。相关数据显示,2017年之前,AI的训练和推理基本都在云端完成。但到了2023年,边缘侧设备/芯片上的AI推理将占据市场一半以上份额,总额高达200-300亿美元,这对IC厂商而言是一个庞大的市场。
AI需要怎样的闪存?
高品质、高可靠性和低延迟的闪存对AI芯片与应用的重要性不言而喻。但黄仲宇提醒,面对不同应用,需从性能、功耗、安全、可靠性、高效能等多方面综合考量。成本固然重要,但并非第一优先的考虑因素,不能顾此失彼。
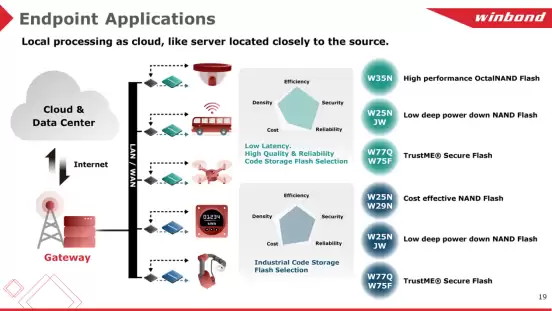
华邦电子的代表性产品包括高性能的OctalNAND Flash W35N、低功耗的W25NJW系列,以及安全闪存W77Q/W75F系列。例如,华邦QspiNAND Flash的数据传输率约为83MB每秒,而OctalNAND系列最快可达240MB每秒,几乎是前者的3倍。在车载应用中,大量AG1 125C NOR系列和AG2+ 115C NAND系列Flash已实现量产。而在智能传感器或产线机器人应用中,华邦则能提供成本与高效能兼备的解决方案,比如W25N/W29N NAND Flash系列。
除了各种Flash产品,华邦的SpiStack(NOR+NAND)也颇具特色。它将NOR芯片和NAND芯片堆叠到同一封装中,例如64MB Serial NOR和1Gb QspiNAND芯片堆叠,让设计人员能灵活地将代码存储在NOR中,数据存储在NAND中。而且,虽然是两颗芯片堆叠,但单一封装的SpiStack仅需6个信号引脚。

“华邦能提供不错的Flash选型来保护客户辛苦开发的代码模型。就像在一场篮球比赛中,芯片厂商扮演中锋或前锋,凭借强大算力不断得分,而华邦就像后卫,在后场提供高品质、高性能的Flash产品,确保用户能在市场上持续得分。”黄仲宇总结道。