2021年10月,Graphcore在英国布里斯托正式发布了两款重磅AI计算产品:IPU-POD128与IPU-POD256。这两款系统分别提供32 petaFLOPS和64 petaFLOPS的AI算力,进一步扩展了Graphcore在超级计算领域的技术版图。简而言之,它们专为需要极致计算性能的应用场景而设计。

从产品线布局来看,Graphcore正在稳步兑现其技术承诺:IPU-POD16继续作为探索平台,适用于前期评估与开发;IPU-POD64则面向已准备建立AI计算能力的客户;而新推出的POD128和POD256直接服务于需要高速增长的头部企业。这些系统能够加速基于Transformer的大语言模型的全系统训练,也可在生产环境中运行大规模商业AI推理应用,或灵活拆分为更小的vPOD,方便更多开发者使用。此外,它们还可用于探索GPT、图神经网络(GNN)等前沿模型,助力科学突破。这些IPU-POD系统专为云超大规模企业、国家科学计算实验室以及金融、制药领域拥有大型AI团队的公司量身定制。
首批采用该系统的客户已出现——韩国科技巨头KT(韩国电信)。KT此前已部署IPU-POD64,目前正与Graphcore合作将其升级至POD128,目标明确:扩大“超大规模AI服务”规模,以满足日益增长的高性能AI HPC需求。KT云/数字体验业务部高级副总裁Mihee Lee表示:“升级后,AI计算规模将提升至32 petaFLOPS,更多类型客户可利用我们的先进AI计算技术进行大规模模型训练和推理。”这一表态充分体现了实际应用价值。
与Graphcore其他IPU-POD系统一样,POD128和POD256采用了“AI计算与服务器解耦”架构。这意味着可根据不同的AI工作负载灵活调整硬件配置,从而实现最优的总体拥有成本(TCO)。举例来说,若主要进行自然语言处理(NLP)任务,可能仅需2台服务器;而若处理计算机视觉等数据密集型任务,则可扩展至8台服务器。存储方面同样灵活,Graphcore近期公布的存储合作伙伴可围绕特定AI工作负载进行优化,真正做到按需配置。
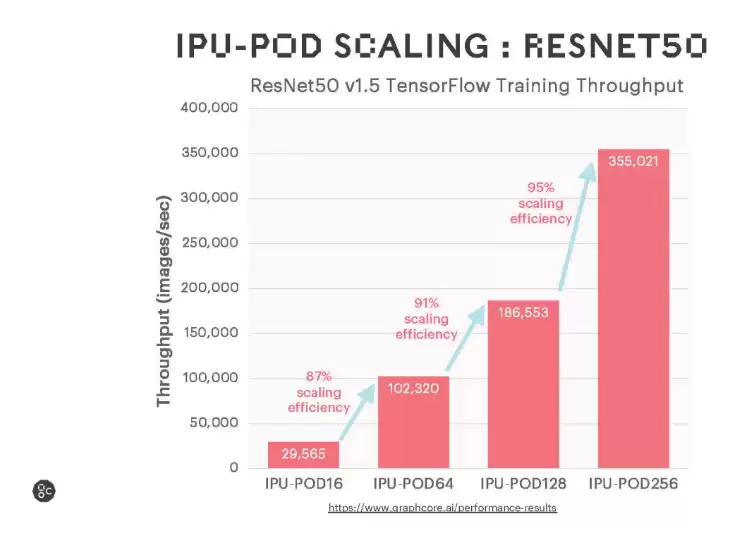
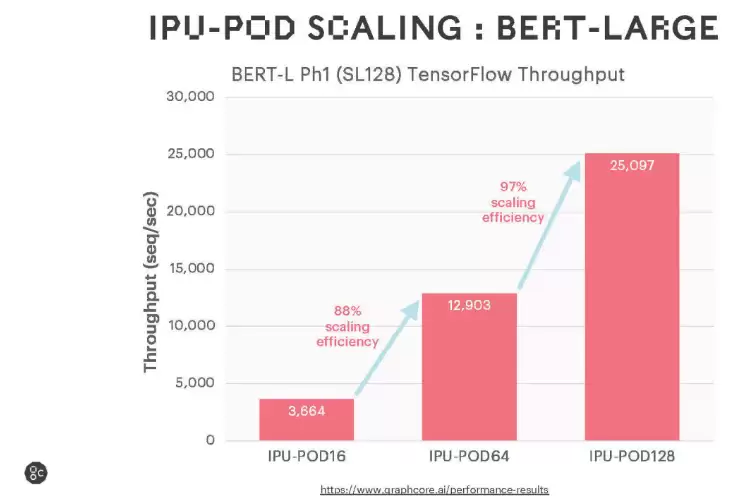
从广泛使用的语言和视觉模型测试结果来看,IPU-POD128和POD256在训练性能和扩展效率方面均表现优异。随着后续软件持续优化,这两款产品的性能还有进一步提升空间——这一点值得持续关注。
要将Graphcore的计算能力扩展到POD128和POD256级别,需要大量使能技术支撑,涵盖硬件与软件层面。Graphcore正携手合作伙伴为全球客户部署这些系统,客户可通过云端直接获取,或通过Atos等合作伙伴进行落地。Atos集团高级副总裁兼HPC与Quantum主管Agnès Boudot表示:“我们非常高兴能将IPU-POD128和POD256加入Atos ThinkAI产品组合,这将使客户能够在更多领域更快地探索和部署更大、更具创新性的AI模型。”这一合作伙伴的反馈也印证了Graphcore方案的生态价值。