首先需要明确一点:如今利用 RAG 技术构建企业级 AI 问答机器人,早已不再是高不可攀的难题。无论你倾向于通过低代码平台进行可视化拖拽,还是希望亲手编写代码实现定制化需求,都有非常灵活的方式可选。整个系统的核心技术栈涵盖了知识库管理、提示词工程、向量数据库、大语言模型、全文检索以及 Query 重写等关键环节。本文将以一个基于 Slack 的 RAG 问答机器人为实例,为你完整拆解背后的技术链路。
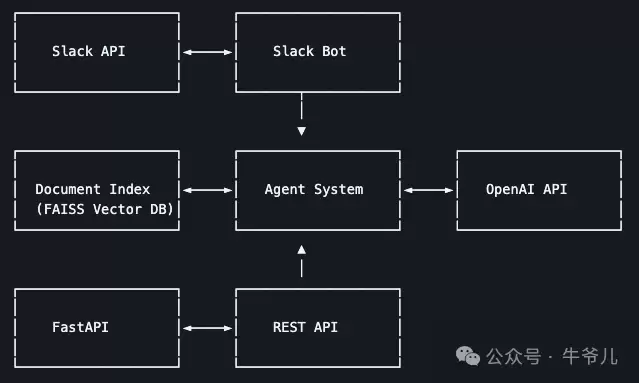
上图展示了系统的整体架构。示例代码可参考 GitHub 仓库。
知识库
当前主流的大语言模型,在零样本(zero-shot)场景下已经能够输出质量相当不错的回答。例如询问“什么是 RAG”,模型可以给出条理清晰的解释。但大模型天然存在一个短板——它的训练语料中并不包含贵公司的内部资料,对你们的业务流程、专有术语毫无了解。因此,在构建企业内部问答工具时,必须引入 RAG 机制:将相关业务文档作为上下文输入给大模型,使其基于特定领域知识进行精准作答。
在搭建知识库的过程中,我们坚持一项核心原则:每篇文章只围绕一个主题,且主题必须明确。同时采用 Markdown 格式编写文档,并在其中嵌入元数据,例如语言类型、背景知识、术语定义等。这样一来,大模型在读取文本时能更准确地把握上下文语境,回答质量自然得到显著提升。
向量数据库
本实例选用 FAISS 作为向量数据库。通过 crontab 定时任务从知识源(知识内容托管于 GitHub)拉取最新数据,随后存入向量库。核心逻辑集中在 index_documents.py 文件中,大致流程如下:
# Read the markdown file
with open(file_path, encoding="utf-8") as file:
content = file.read()
# Convert markdown to HTML and then extract text to remove markdown formatting
html = markdown2.markdown(content)
soup = BeautifulSoup(html, "html.parser")
text = soup.get_text()
# Create a Document object with metadata
relative_path = os.path.relpath(file_path, directory_path)
doc = Document(
page_content=text,
metadata={
"source": file_path,
"filename": os.path.basename(file_path),
"path": relative_path,
},
)
# index document
# Add to vector store
if not self.vector_store:
self.vector_store = FAISS.from_documents(
documents=documents, embedding=self.embeddings
)
else:
self.vector_store.add_documents(documents)
请注意,我们不仅将文档内容进行了向量化处理,还保留了源文件路径、文件名等元数据。这些信息在后续检索以及结果溯源时将发挥重要作用。
Query 重写
在实际应用场景中,用户的提问往往比较粗糙。比如“登录不了”、“咋注册”、“2FA”等简短表述,如果直接拿去知识库检索,很可能无法匹配到理想结果。因此,我们需要对用户的查询语句进行一次改写——既可以通过规则映射实现,也可以借助大模型自动生成多个备选 query。本实例直接使用了 LangChain 的 MultiQueryRetriever,它在获取相关文档时会自动执行 query 重写:
# Initialize MultiQueryRetriever
retriever = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
经过改写后的查询能够检索到更多相关文档,效果可谓立竿见影。
混合检索(EnsembleRetriever)
在 RAG 系统中,不同的检索器各有优势与不足:
- 向量搜索:擅长语义匹配,但有时会遗漏精确的关键词。
- 关键词搜索(BM25 / TF-IDF):精确匹配能力强,但语义理解偏弱。
- 元数据搜索:适合结构化数据,例如按标签或分类进行过滤。
为了取长补短,我们在实现中组合了向量搜索与关键词搜索,具体代码如下:
# Create keyword-based BM25 retriever
self.bm25_retriever = BM25Retriever.from_documents(self.documents)
self.bm25_retriever.k = 3 # 获取 top 3 的文章
# Create semantic retriever
self.semantic_retriever = self.vector_store.as_retriever(
search_kwargs={"k": 5, "search_type": "similarity"}
) # 获取 top 5 的文章
# Create ensemble retriever (combines both approaches)
self.hybrid_retriever = EnsembleRetriever(
retrievers=[self.bm25_retriever, self.semantic_retriever],
weights=[0.3, 0.7], # Weight semantic search higher
) # 关键词搜索占30%,语义搜索占70%
权重的意义在于对检索结果进行加权评分,计算公式如下:

权重的具体分配可以根据实际业务需求进行调节,此处我们更倾向于语义搜索,因为它更擅长处理理解和总结类的问题。
Prompt 优化
最后探讨一个核心问题:大语言模型本质上是一个概率模型,无论你提出什么问题,它都会给出当前概率最高的回复(即 Top N 采样),这很容易引发“幻觉”现象。因此,在向大模型输入提示词时必须施加必要的约束。我们在 prompt 中通常会加入这样一句指令:“如果没有检索到相关的内容,请直接回答不知道”。别小看这一句话,它能极大地抑制模型胡编乱造,显著降低生产环境中的风险。
以上内容基本覆盖了 RAG 机器人的核心实现链路。当然,若想进一步提升系统效果,每一个环节都有丰富的优化空间——从知识库的清洗与分块策略,到检索精度与重排序,再到 prompt 模板的持续迭代,都需要进行细致的测试与评估。希望这篇梳理能为正在开展类似项目的朋友提供一些有价值的参考。