DeepSeek-R1一经发布,AI应用的部署需求就肉眼可见地暴涨。抛开模型效果本身不谈,光说部署这一侧的易用性和灵活性,相比VLLM确实提升了一大截,门槛降低了不少,但坑也跟着来了——而且是连环坑。
下面的部署方案全部基于Docker,因为实在是太方便了。不过方便归方便,坑位也不少,请做好心理准备。喜欢折腾的同学可以按教程一步步来,我也是被逼无奈才把踩过的坑都记了下来。建议手边备好咖啡或茶,找个安静的时间段慢慢搞——不出意外的话,马上就会出意外,一个Bug一根烟。
Xinference部署
Xorbits Inference(简称Xinference)是一个开源的AI模型运行和集成平台。借助它,你可以在云端或本地环境中,轻松运行各种开源LLM、嵌入模型和多模态模型,并搭建强大的AI应用。
部署命令非常简洁,一条docker run就能搞定:
docker run \
--name xinference \
-d \
-p 9997:9997 \
-e XINFERENCE_HOME=/data \
-v $(pwd):/data \
--gpus all \
xprobe/xinference:latest \
xinference-local -H 0.0.0.0参数说明:--name xinference给容器命名,-d后台运行,-p 9997:9997端口映射,-e XINFERENCE_HOME=/data设置主目录,-v $(pwd):/data将当前目录挂载到容器内实现数据持久化,--gpus all启用全部GPU。
部署成功后,直接访问http://localhost:9997就能看到管理界面。
部署一个reranker
建议从ModelScope下载,速度更快。部署成功后的界面如下:
RAGFlow部署
RAGFlow是一款基于深度文档理解的开源RAG引擎,专为各种规模的企业和个人设计,能结合大语言模型处理复杂格式数据,提供可靠的问答与引用。
步骤1:克隆仓库
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow/docker
$ git checkout -f v0.17.2步骤2:使用预构建的Docker镜像并启动服务器
注意:下面的命令会下载v0.17.2-slim版本的RAGFlow镜像。如果你需要其他版本,可以在启动前修改docker/.env中的RAGFLOW_IMAGE变量。
# 使用CPU进行嵌入和DeepDoc任务:
$ docker compose -f docker-compose.yml up -d
# 使用GPU加速嵌入和DeepDoc任务:
# docker compose -f docker-compose-gpu.yml up -d问题3:ragflow-mysql is unhealthy
如果遇到“dependency failed to start: container ragflow-mysql is unhealthy”,依次执行以下命令即可解决:
docker compose down -v
docker compose up不出意外的话,这里就要出意外了。访问http://localhost:81/login#/(81是修改后的默认web端口)。
Dify部署
Dify是一款开源的大语言模型应用开发平台,融合了后端即服务和LLMOps理念,非技术人员也能参与AI应用的定义和运营。
下载对应版本的标签:
访问安装页面:

启动报错pgdata: Operation not permitted
这个错误通常是因为PostgreSQL数据目录权限问题。按照以下步骤修复:
- 确保目录存在:
mkdir -p ./volumes/db/data
- 设置正确的权限:
sudo chown -R 999:999 ./volumes/db/data
- 验证Docker Compose配置:确保volume映射正确。
version: '3'
services:
db:
image: postgres:15-alpine
restart: always
environment:
PGUSER: postgres
POSTGRES_PASSWORD: difyai123456
POSTGRES_DB: dify
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- ./volumes/db/data:/var/lib/postgresql/data
healthcheck:
test: [ "CMD", "pg_isready" ]
interval: 1s
timeout: 3s
retries: 30- 清理现有数据:
sudo rm -rf ./volumes/db/data/*
- 运行Docker Compose:
docker compose up -d
Dify Docker部署后,install界面卡住,step请求报502
这个问题可以参考社区解决方案,通常是nginx或后端服务启动顺序的问题。
Postgres报错

修正后的docker-compose.yaml配置如下:
# PostgreSQL 数据库
db:
image: postgres:15-alpine
restart: always
environment:
PGUSER: xxxx
# 默认 postgres 用户的密码
POSTGRES_PASSWORD: xxxx
# 默认的 postgres 数据库名称
POSTGRES_DB: dify
# PostgreSQL 数据目录
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- db_data:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready"]
interval: 1s
timeout: 3s
retries: 30
# 添加卷名称
volumes:
db_data:核心修复点:将原来的挂载路径改为使用命名卷db_data,并在文件末尾添加卷声明。
Ollama部署
Ollama是一个开源的大语言模型平台,让你能轻松在本地运行、管理各种LLM,支持文本生成、翻译、代码编写等任务。它的亮点是简化工作流程,让机器学习不再是深度技术背景的开发者才能触及的领域。Ollama支持多种硬件加速,包括纯CPU推理和Apple Silicon。
运行模型只需一条命令:
ollama run deepseek-r1:14b
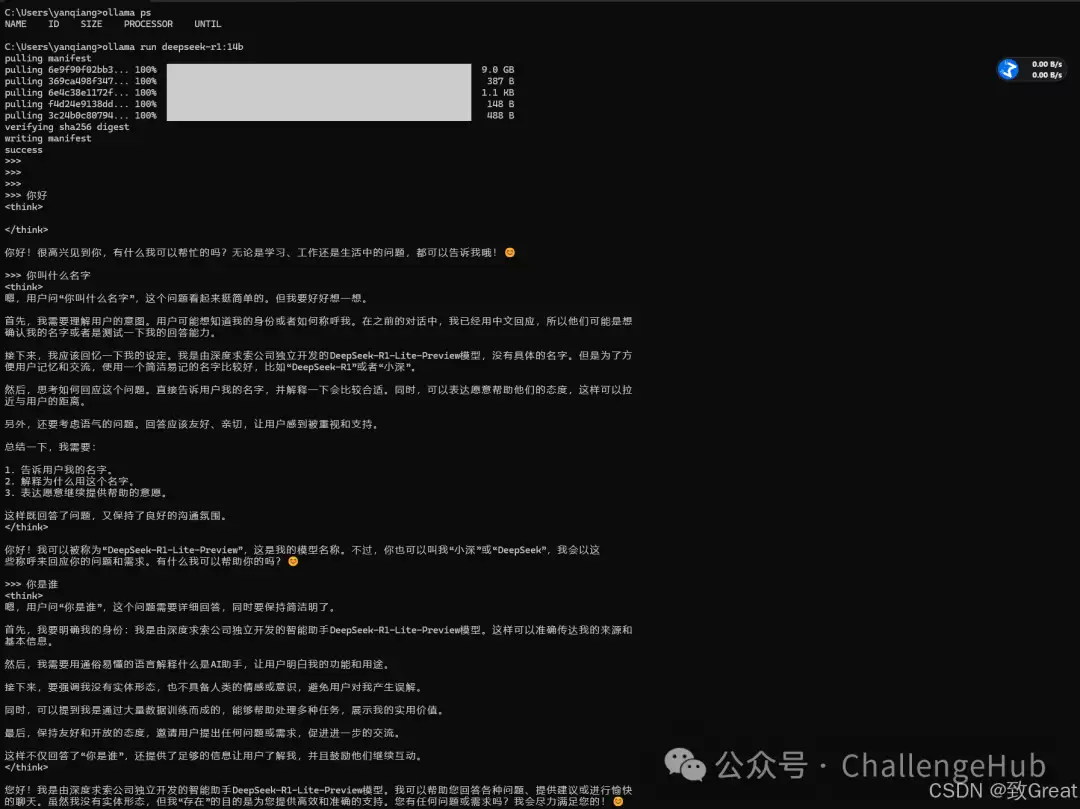
Ollama在Windows中常用的环境变量:
| 环境变量 | 描述 | 默认值 | 示例值 |
|---|---|---|---|
| OLLAMA_HOST | 指定服务器主机地址和端口 | 127.0.0.1:11434 | 0.0.0.0:11434 或 192.168.1.100:11434 |
| OLLAMA_MODELS | 指定模型文件存储位置 | %USERPROFILE%\.ollama\models | D:\ollama\models |
| OLLAMA_KEEP_ALIVE | 模型在内存中保持加载的时间(秒) | 5分钟(300秒) | 1800(30分钟) |
| OLLAMA_VERBOSE | 启用详细日志输出 | 0 | 1 |
| OLLAMA_TIMEOUT | API请求超时时间(秒) | 30 | 60 |
设置这些变量后,记得重启Ollama服务或重新打开命令行窗口。
缝合怪如何集成组件
- RAGFlow集成Ollama
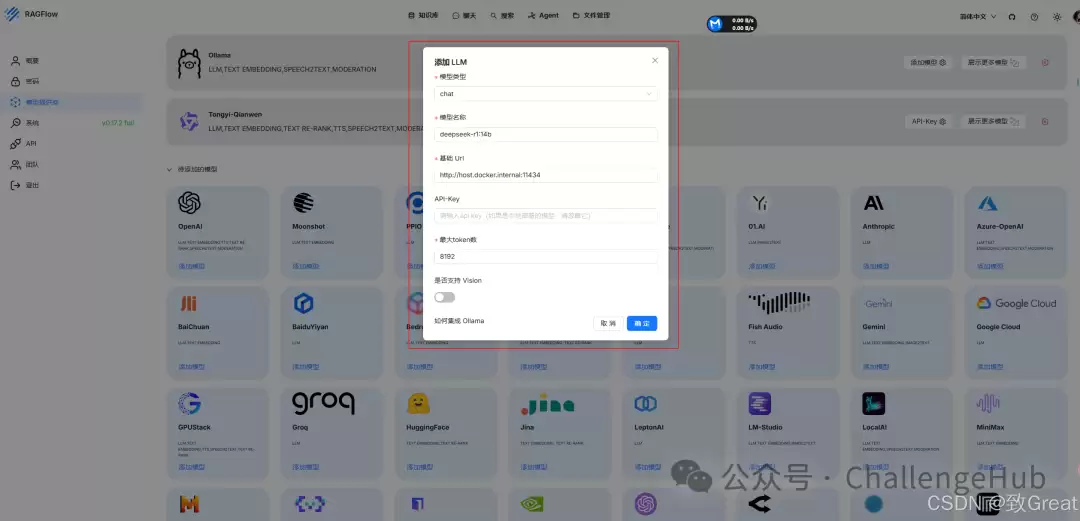
deepseek-r1:14b 基础 Url http://host.docker.internal:11434 API-Key 最大token数 8192
- RAGFlow集成Xinference重排序模型
在Xinference中运行排序模型后,填写本机IP地址即可。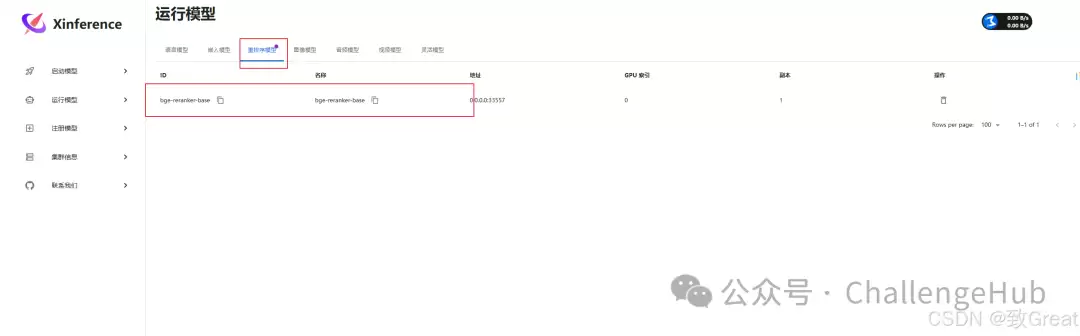
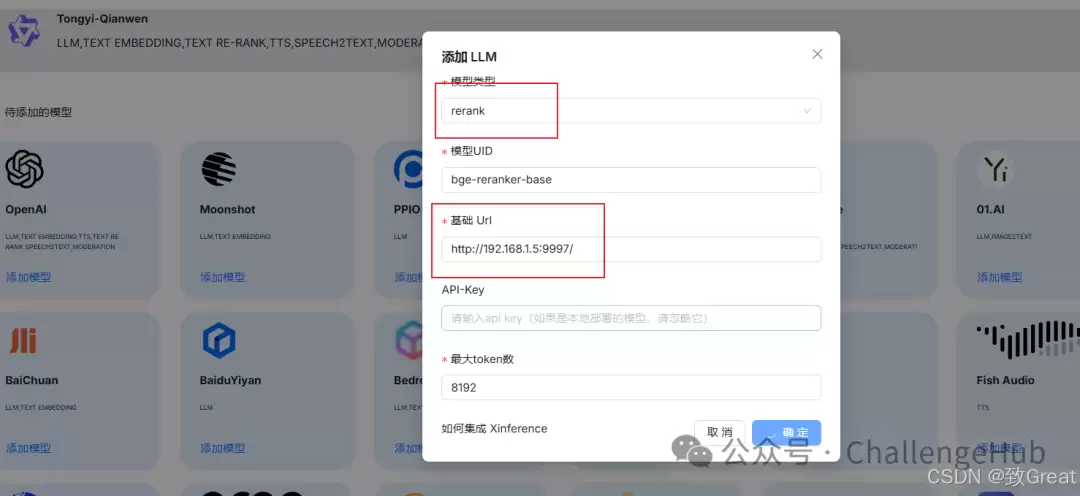
- Dify集成Ollama模型
- Dify集成Xinference排序模型
- Dify集成Xinference向量模型
Dify集成RAGFlow
- 获取RAGFlow知识库ID
- 在Dify中添加外部知识库