CherryStudio搭建本地知识库
先说明核心流程,再逐步详细拆解。整个搭建过程分为几个关键步骤:注册账户、配置Embedding嵌入模型、导入数据,最后是实际应用与优化技巧。
搭建步骤详解
第一步,需要先完成账号注册。前往硅基流动平台注册账号,主要目的是配置Embedding嵌入模型。注册成功后会获得2000万Token的免费额度,用于测试完全足够。
第二步,下载并安装CherryStudio客户端。官方提供了全平台支持,Mac、Windows、Linux均可使用,这一点非常友好。
安装完成后,开始配置API密钥。在硅基流动的API密钥页面新建一个密钥,名称可以自定义。关键操作是点击“API密钥”按钮,系统会自动复制密钥;然后回到CherryStudio客户端,点击左下角的“设置”,将复制的密钥粘贴进去。填写完毕后点击右侧的“检查”按钮,如果提示成功,则说明配置成功。
接下来是添加Embedding嵌入模型。点击底部的“管理”按钮,这里特别提醒:BAAI/bge-m3模型是免费的,而Pro/BAAI/bge-m3模型则是收费的。从官方介绍来看,两者功能没有明显差异,因此直接使用免费的BAAI/bge-m3即可。
模型配置完成后,点击左侧倒数第二个“知识库”按钮(该位置较为隐蔽,首次使用可能需要寻找),然后命名知识库名称,并选择刚才配置的BAAI/bge-m3模型。至此,底层架构基本搭建完成。
数据导入方式
CherryStudio在数据导入方面提供了多种灵活方式:
- 添加文件:点击添加文件按钮,直接上传单个文件。支持PDF、DOCX、PPTX、XLSX、TXT、MD、MDX等多种格式,覆盖面很广。
- 文件夹目录:可添加整个文件夹,系统会自动识别并向量化其中所有支持格式的文件,适合批量处理场景。
- 网址链接:输入网页URL即可自动抓取内容并向量化,比如文档网站、博客文章都可以直接导入。
- 纯文本笔记:支持手动输入自定义内容,适合补充个人总结或注释。
导入完成后,系统会自动进行向量化处理。当文件状态显示绿色“√”时,表示向量化已完成。此时点击“探索知识库”按钮即可开始查询。
测试与应用
数据入库后,可以新建一个“助手”来测试效果。可以选择系统预设的模板助手,或自定义创建一个默认助手。将已有的提示词粘贴进去,点击关闭即可使用。当然,也可以进行进阶的预设置。
在助手的聊天界面底部,记得开启知识库开关。至此,整套流程就打通了。另外还有一个实用技巧:在聊天界面的最顶部或输入框里的@符号处,都可以随时切换其他可用的模型,这一点非常灵活。
从实际运行效果来看,系统在回答问题时不仅会给出结论,还会主动标注引用信息,证明它确实调用了本地知识库的内容。
本地知识库分析APP隐私政策
搭建好本地知识库之后,正好用来检验效果——分析APP中的隐私政策文本,检查是否存在合规问题。有了本地知识库的加持,加上大模型对文本的理解能力,这类分析工作确实变得更加高效。
当然,想要用好这个工具还需要自己反复测试:一方面测试哪个模型回答最符合预期;另一方面测试自己的提示词,不断迭代优化;第三是持续优化本地知识库本身,因为初始上传的文档可能存在识别问题,比如扫描版PDF经常出错。
模型选择
实测下来,不同模型的差异非常明显:
DeepSeek-R1:思考能力强,能帮助用户大幅改进想法和提示词。但它有一个问题——过于发散。即使提示词已经明确要求输出格式,它仍可能偏离预定轨道,让人有些头疼。
DeepSeek-V3:会遵守提示词的约定,但回答内容过于规整,说白了就是不太理解用户的深层需求,表现较为机械。
GPT-4o:响应速度最快,效率很高。不过回答质量仍有差距,感觉处于DeepSeek-R1和DeepSeek-V3之间的摇摆状态。
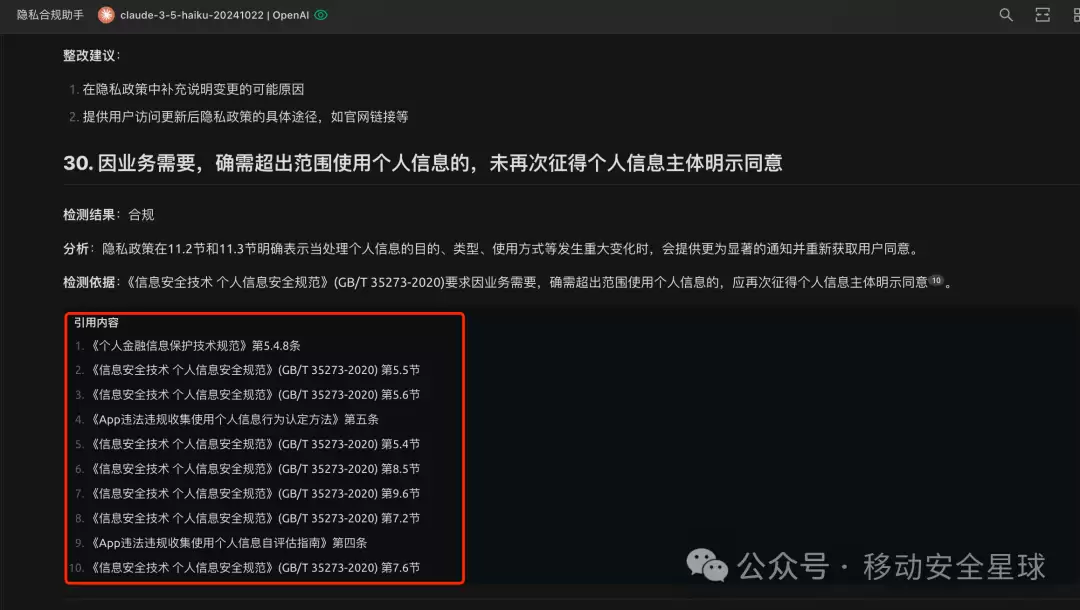
claude-3-5:表现最稳定,完全达到了预期效果。在分析隐私政策时,它能严格按照提示词的要求输出:分析的是哪一段内容、是否符合要求、参考了什么标准、应该如何整改,这些信息都能准确输出,几乎没有错误。
提示词优化
初始的提示词写得非常简单,只告诉模型它是一名隐私合规分析工程师,参考知识库中的标准文档分析不合规之处。结果输出很不稳定——这次分析这几段,下次又分析那几段,完全不固定。
后来开始固定检测项:将标准中与隐私政策相关的检测项全部整理出来,放到提示词中,明确要求逐一分析、不能遗漏。这样确实能覆盖所有检测项,但很多理解仍然不够到位。
改进方法是给每条检测项后面添加注释,将理解该检测项时的思路、定位方法都写清楚。到这一步,模型才开始像样地进行分析。
最后剩下的问题是几乎所有大模型都有的通病——回答长度限制。解决方法也很简单:在它回答暂停后,输入“继续”即可。
知识库优化
知识库的优化是一个持续的过程。初始上传的文档中有些无法识别(例如扫描版PDF),遇到这种情况就需要寻找其他格式的文档进行替换。根据官方建议,优先选择Word文档会更稳妥。不过实际使用下来,很多文档格式都能正常处理。
还有一个技巧:部分官方文档的内容可能比较抽象,可以在知识库中添加一些笔记,对这些内容进行解释说明。当然,将这些解释直接写入提示词也可以,目的都是让大模型提前理解这些内容。