在数据分析与AI需求持续攀升的当下,很多企业都在琢磨如何提升计算基础设施的性能。硬件加速成了最直接的答案。可编程硬件,尤其是GPU和FPGA,是目前的主流选择。这些先进硬件确实能带来计算优势,但编程难度这事儿,始终是个绕不开的坎儿。
图 1:分析/AI 流水线组件
硬件厂商正在把加速思路延伸到计算存储领域——也就是那种内置了计算单元的存储设备。实践证明,这种设计对分析和AI应用效果显著(见图1)。无论是否借助机器学习辅助的分析与验证,计算存储都能加速。它最大的价值在于:把高成本的计算任务从服务器CPU上卸下来,下沉到存储器件里完成。相比传统的存储/CPU方案,优势很清晰:
1. 通过应用专用硬件定制,获得更高性能
2. 释放CPU资源,让服务器更专注
3. 计算与数据放在一起,数据传输量自然降下来
这个新方向前景不错,但关键还是要结合具体场景来评估——性能、成本、功耗、易用性,一个都不能少。性价比和单位功耗性能,往往是衡量加速硬件的核心指标。这次我们先聚焦单位功耗性能(性价比另外再聊)。
计算存储功耗比较:三种系统
我们用CSV数据读取这个典型场景来比比看。参与测试的有三套方案:英伟达GPUDirect Storage配合RAPIDS,以及基于赛灵思技术打造的三星SmartSSD。CSV读取在计算密集型流水线中占据重要位置(见图1),它的处理速率(也就是“带宽”)直接反映了性能。
先快速回顾一下每种系统是怎么工作的。
英伟达 GPUDirect Storage
• 端到端满足分析与AI需求
• 把GPU作为计算单元,紧贴NVMe存储器件布局(GPUDirect)
• 用CUDA编程(RAPIDS)
英伟达拿自家CSV读取技术与标准SSD对比,结果如图1所示。使用1到8个翻跟斗时,吞吐量范围在4到23GB/s之间。
三星 SmartSSD 驱动器
• 把赛灵思FPGA作为计算单元
• 内嵌在存储逻辑中,与存储共享同一个PCIe互联
• 直接在存储平台上编程运算
赛灵思的数据分析合作伙伴Bigstream与三星合作,为Apache Spark设计了包括CSV和Parquet处理在内的加速IP。SmartSSD的测试采用单机CSV解析引擎,结果见图2。使用1到12个翻跟斗时,吞吐量同样在4到23GB/s区间,图表中也并列给出了英伟达的结果(1到8个翻跟斗)。需要留意的是,所有结果都按翻跟斗数量做了参数化处理。
结果确实让人振奋,但选方案时一定别忘了把功耗算进去。

图 2:SmartSSD 驱动器的 CSV 解析性能结果
单位功耗性能比较
图3显示了考虑功耗之后的分析结果。它代表“每瓦性能”,数据基于以下假设:
• Tesla V100 GPU:最大功耗200瓦
• SmartSSD 驱动器 FPGA:最大功耗30瓦
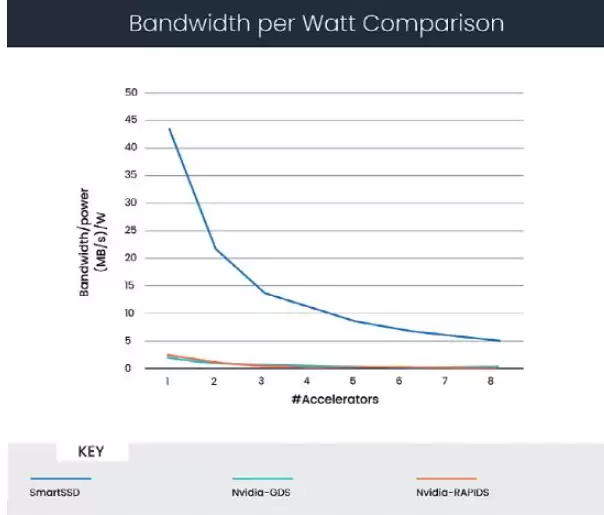
图 3:CSV 解析的每瓦功耗带宽比较
在这个场景下,计算显示:同样是8个翻跟斗,SmartSSD的单位功耗性能比GPUDirect Storage高出25倍。
FPGA 与 GPU 对比:有关单位功耗性能的最终思考
计算存储的价值在于提升数据分析和AI应用性能。但要想让这条路真正落地,评估时一定不能忽略功耗。针对CSV数据解析这个典型任务,我们给出了两种计算存储方案按功耗参数化之后的吞吐量曲线。结果表明,在翻跟斗数量相近的条件下,SmartSSD驱动器的单位功耗表现要优于GPUDirect Storage方案。
顺便提一句:GPUDirect是英伟达通过DGX-2应用平台提供的研究系统,而三星SmartSSD驱动器是一款已经量产、可部署的PCIe插拔平台,目前通过赛灵思及分销商渠道供货。