今天要介绍的,是Dify v1.1.0版本中一项真正能够“提效”的强大功能——元数据过滤。简单来说,这次更新大幅提升了知识库的检索效率,尤其在RAG场景下对海量信息的管理,实用价值非常显著。
过去,用户只能在未经整理的庞大数据池中搜索,如同大海捞针,既无法按特定需求筛选,也难以控制谁能查看哪些内容。而现在,元数据相当于为每条数据打上标签、做好分类,检索的精准度和响应速度自然得到显著提升。
元数据过滤是什么?
元数据本质上是“关于数据的数据”。它为原始数据附加额外的背景信息或属性标签,使搜索和检索能够更精确地命中目标。例如,在文档管理系统中,元数据可以包含文档名称、作者、创建日期等。借助这些结构化信息,系统就能基于特定条件进行筛选,快速锁定相关内容。
元数据过滤:让RAG应用如虎添翼
这项功能最直接的价值,在于显著提升RAG应用的搜索准确度。用户能够快速定位所需文档,同时大幅减少无关结果的干扰。更重要的是,通过“访问控制”可以强化数据安全——只有具备相应权限的用户才能查看敏感信息。此外,精确限定查询范围还能优化搜索性能,节省计算资源。在企业内部,这种定制化功能尤为实用:用户体验得到提升,操作也更加直观。
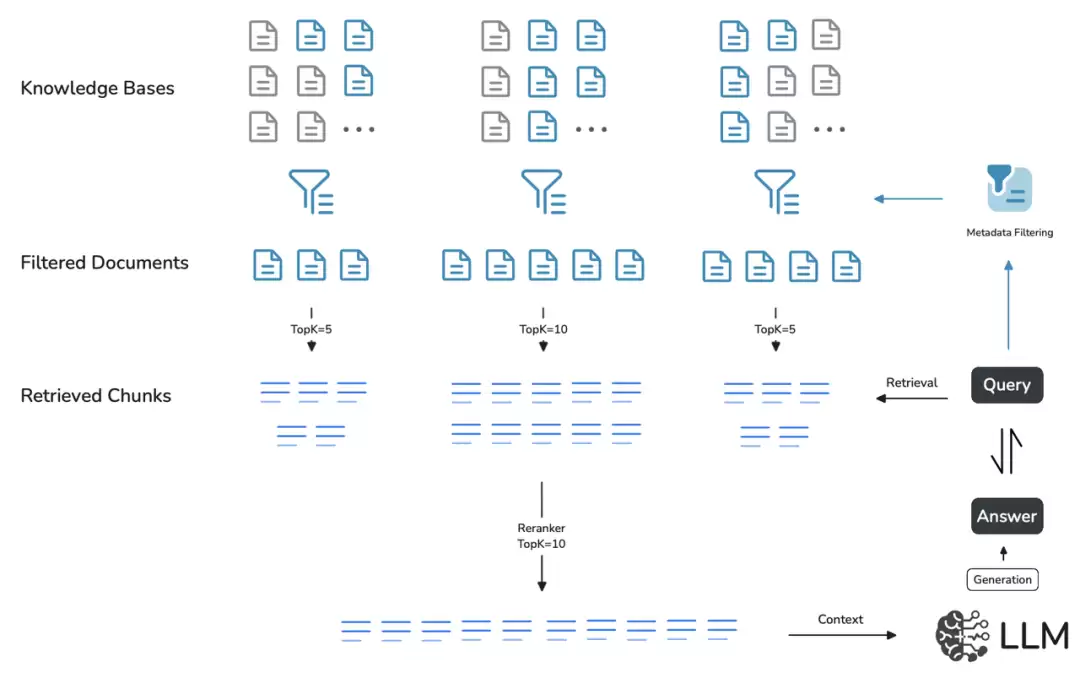
下面这张示意图展示了不同访问控制的对比,说明元数据过滤如何实现更细粒度的管理。示例中使用了三个过滤条件:privacylevel、uploader和update_date。通过调整privacylevel,即可控制用户对特定文档(例如RAG 2.0路线图)的访问权限。管理员能够精准决定哪些用户可以检索或查看某些信息,安全与效率兼得。
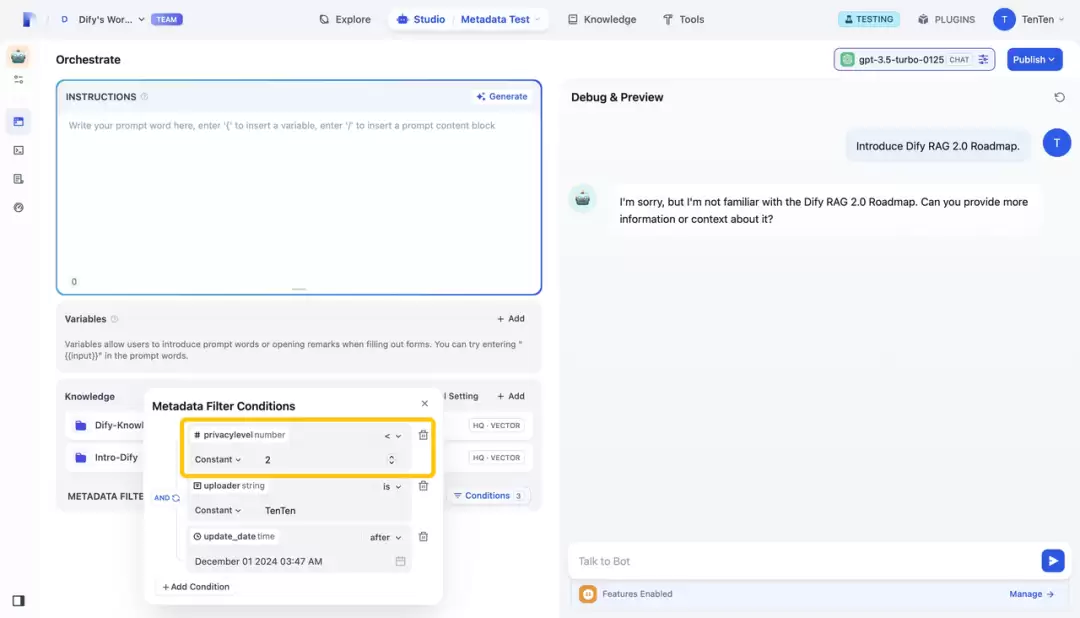
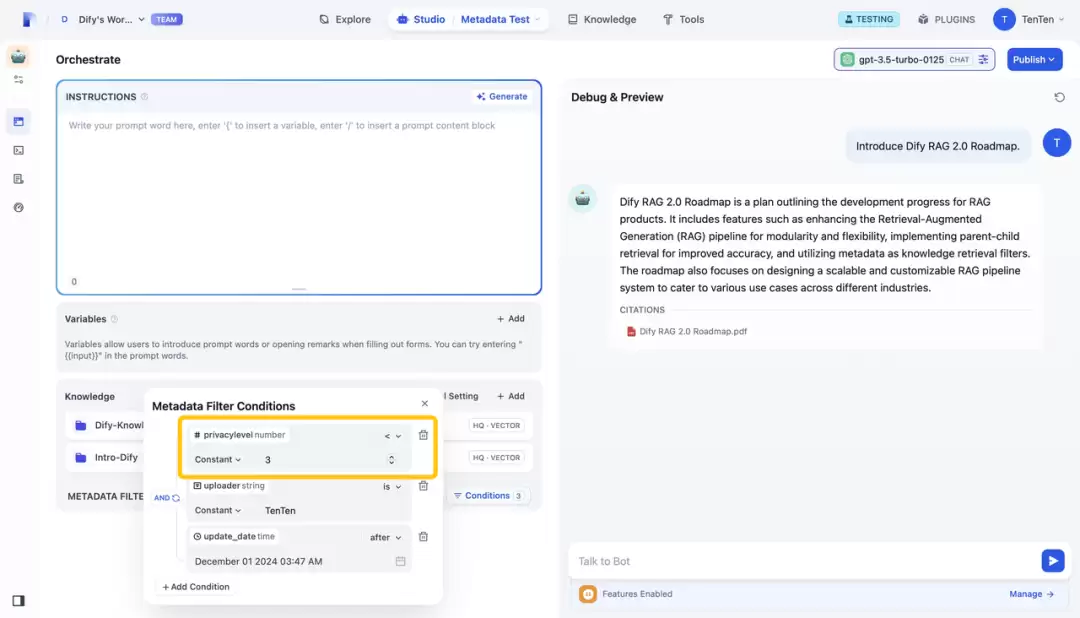
简而言之,元数据就像一个智能的知识过滤器——通过增添上下文属性和访问控制,让信息检索变得更智能、更安全、更高效。尤其是在需要兼顾知识隐私和检索相关性的RAG系统中,元数据的重要性不言而喻。
如何用元数据过滤,让知识检索更精准?
第一步:在知识库中为文档添加元数据
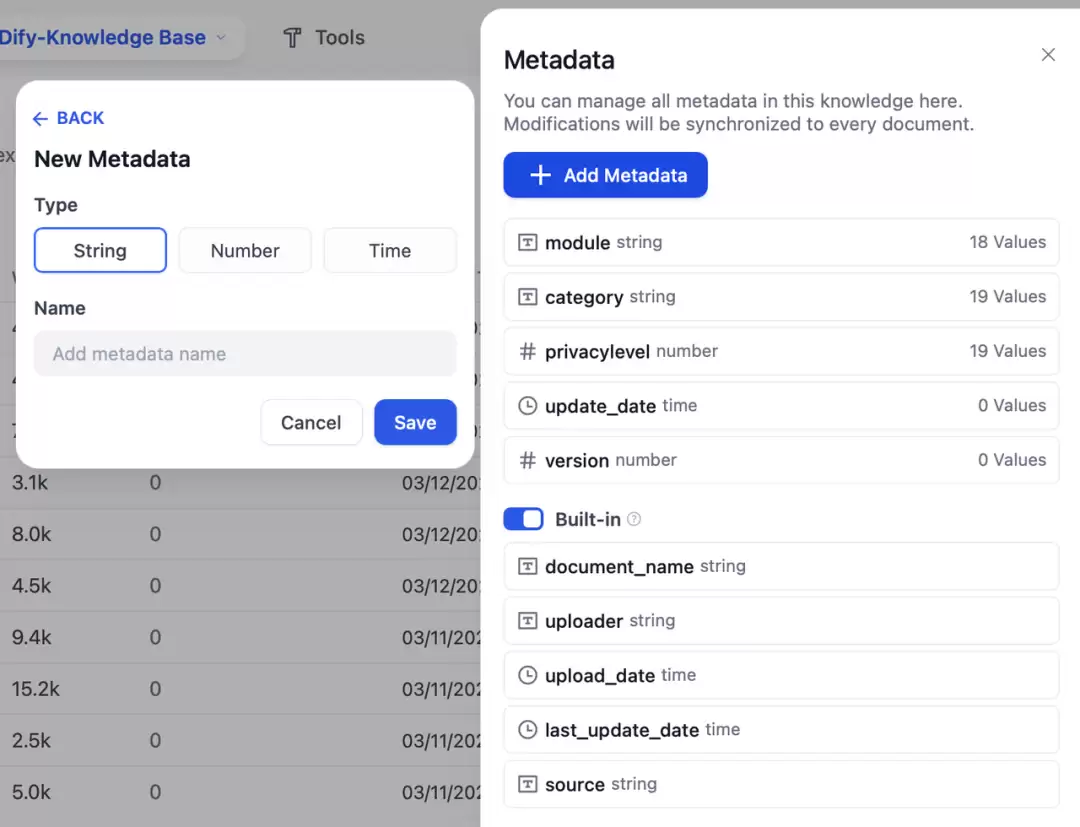
在知识库里,用户可以为文档添加并管理元数据。每个文档创建时都会自动分配一些默认元数据(比如文件名、上传者、上传日期)。用户也可以手动添加新的元数据字段,设置字段名称和数据类型,并对现有文档进行批量编辑。这种“打标签”的方式,能为文档附加更多结构化信息,让后续搜索和管理更高效。
第二步:在应用中配置元数据过滤
在Chatbot的「Context」部分,或者在Chatflow、Workflow中的知识检索节点里,都能找到元数据过滤的配置入口。用户可以基于元数据属性来精准筛选检索内容。目前支持自动和手动两种过滤模式:自动模式下,系统会根据用户查询自动提取并生成过滤条件;手动配置时,用户可以根据元数据字段类型(字符串、数值或时间)设置条件,并将多个条件之间的关系设为AND或OR。
三大元数据类型与应用场景
目前支持三种类型的元数据:字符串、数值和时间,实际场景中可以灵活组合使用。下面是几个示例:
- 字符串元数据 – 提升语境相关性。通过字符串元数据,可以过滤掉大量与查询不相关的信息,让结果更精准。例如用户搜索“项目报告”时,如果文档携带“市场部”或“研发部”等标签,系统就能优先呈现这些相关文档。
- 数值元数据 – 实施访问控制。利用数值元数据,可以根据预设标准限制文档访问权限。例如,用户只能检索隐私级别高于某个阈值的文档,确保数据安全与合规。
- 时间元数据 – 管理文档版本。时间元数据能区分文档的新旧版本。内容更新并重新上传后,通过时间过滤可以优先检索到最新版本。如果上传者设置为同一用户,还能方便地对多批次上传的不同版本进行对比测试,同时保证文档处理的一致性。