近两年,大语言模型的普及速度远超预期,AI推理应用的需求随之呈指数级增长。以DeepSeek为代表的开源模型凭借出色的推理性能与精准度,迅速赢得开发者社区的青睐——从企业级智能对话系统到个人内容生成工具,几乎处处可见其身影。然而,模型规模越大、推理请求越密集,性能瓶颈就越发凸显。官方服务与云厂商推出的推理应用均面临一系列可观测性挑战。
本文核心内容如下:
- AI推理应用性能监控的关键指标与难点
- Prometheus在AI推理监控中的应用场景与优势
- 基于Prometheus构建全链路可观测性方案
接下来,我们将深入剖析如何利用Prometheus这套成熟的指标体系,清晰掌握推理应用的运行状态,从而构建稳定、高效的推理服务。
一、AI推理应用的可观测需求与痛点
以自建DeepSeek应用为例,可观测需求主要集中在以下几个方面:
性能指标监控
性能是推理应用的核心关注点,涵盖请求延迟、吞吐量与并发能力等关键指标。用户期望推理应用能在毫秒级返回结果,但当请求量骤增时,服务可能因资源争抢导致延迟飙升。若缺乏细粒度性能监控,问题定位将异常困难。
资源使用监控
AI推理应用通常依赖GPU、TPU或PPU等高性能计算设备。这些设备的资源利用率监控不仅涉及硬件层面,还需结合模型推理的具体行为进行分析。例如,某些模型因内存分配不合理,导致频繁显存交换,进而拖累整体性能。
模型加载与卸载的开销
DeepSeek模型及推理运行环境基础镜像体积庞大,加载和卸载过程耗时较长。若该环节缺乏可观测性,服务启动时间可能过长,或引发资源竞争。
模型行为监控
推理过程中可能出现异常输出或错误预测,这些问题往往与输入数据质量或模型自身稳定性有关。缺乏有效的模型行为观测,业务风险将随之增加。
分布式架构监控
大规模推理场景下,分布式架构成为必然选择。但分布式系统中的节点通信延迟、负载均衡与服务发现问题,都会影响推理应用的稳定性。
面对上述挑战,传统监控手段显得力不从心——仅依赖日志分析无法实时捕捉性能瓶颈,简单的CPU/GPU使用率监控也难以全面反映推理应用的健康状态。AI推理应用的可观测需求不仅涉及硬件资源和性能指标,还包括模型行为与分布式架构的复杂性。因此,如何借助高效的可观测手段实现全链路可观测,已成为技术团队亟需攻克的难题。
二、基于Prometheus的完整解决方案
Prometheus是一款开源的系统监控与报警工具,以其强大的多维数据模型和灵活的查询语言(PromQL)著称。它特别适配动态云环境和容器化部署,能够轻松融入AI推理服务的可观测体系。
Prometheus的优势包括:
- 多维数据模型:支持通过标签对指标进行分类与过滤,可轻松对不同维度数据进行聚合分析,例如按GPU ID、模型名称或请求类型对性能指标进行分组。
- 高效的拉取机制:采用主动拉取方式收集指标数据,避免传统推送模式可能带来的数据丢失或重复问题。
- 丰富的生态系统:提供广泛的Exporter和客户端库,能与多种框架和工具无缝集成,如Ray Serve、vLLM等推理框架均可通过Exporter暴露指标。
- 强大的告警功能:内置Alertmanager支持基于规则的告警配置,能够及时发现问题并通知相关人员。
- 可视化支持:可与Grafana等可视化工具结合,构建直观的观测大盘,帮助团队快速掌握服务状态。
通过社区与厂商的共同生态建设,目前已形成完善的指标生态:IaaS层智算物理设备(GPU、RDMA网络、CPFS存储、CPU和内存等)的关键利用率监控、Kubernetes编排层的全套指标监控、智能PaaS平台的上下层结合监控体系,以及社区常见训练/推理框架默认支持的Prometheus指标埋点。这些基础让AI推理的指标观测方案站在了很高的起点上。
三、推理应用全链路观测实践
(一)推理框架Ray Serve
Ray Serve的设计目标是解决传统推理框架在灵活性、性能和可扩展性方面的不足。它具备以下特点:
- 动态伸缩能力:支持根据实时流量动态调整模型副本数量,实现资源高效利用,特别适合流量波动较大的在线推理场景。
- 多模型支持:可同时部署多个模型,并通过路由规则将请求分发到不同的模型实例。例如,可将NLP模型与图像分类模型部署在同一服务中,根据请求路径或内容进行区分。
- 批处理优化:针对高吞吐量推理任务,提供内置批处理机制,将多个请求合并为一个批次处理,显著提升GPU利用率。
- 灵活的服务编排:支持将模型推理与其他业务逻辑(如数据预处理、后处理)无缝集成,形成端到端服务流水线,并能在单机或多节点环境中快速部署,与Kubernetes无缝集成实现集群化部署。
正因Ray Serve能力完善,它已成为开源AI推理工具中的明星。推理性能最直接的体现来自推理框架,Ray Serve需要从模型加载、推理副本调度、流量路由、推理请求处理性能、Token输入输出等多个方面建立完善的观测指标。当然,在Ray Serve内置指标集基础上,还可根据推理服务特点选择性自定义性能指标。
Ray Serve内置完善的指标集
在性能观测方面,Ray Serve通过Ray的监控基础设施暴露重要的系统指标,还可利用内置的Ray Serve指标更深入了解应用服务性能,例如成功和失败请求的数量。默认情况下,这些指标以Prometheus格式在每个节点上暴露。
以下是Ray Serve暴露的内置指标列表:
| 名称 | 标签 | 描述 |
| ray_serve_deployment_request_counter_total [**] | deployment, replica, route, application | 此副本已处理的查询数量。 |
| ray_serve_deployment_error_counter_total [**] | deployment, replica, route, application | 部署中发生的异常数量。 |
| ray_serve_deployment_replica_starts_total [**] | deployment, replica, application | 由于故障此副本被重启的次数。 |
要查看这些指标的实际效果,首先运行以下命令启动Ray并设置指标导出端口:
ray start --head --metrics-export-port=8080
假设我们在Kubernetes中通过KubeRay部署RayServe,可以通过配置PodMonitor来采集Head和Worker节点暴露的指标。配置示例如下:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: ray-workers-monitor
namespace: prometheus-system
labels:
release: prometheus
spec:
jobLabel: ray-workers
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
ray.io/node-type: worker
podMetricsEndpoints:
- port: metrics
relabelings:
- sourceLabels: [__meta_kubernetes_pod_label_ray_io_cluster]
targetLabel: ray_io_cluster
---
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
labels:
release: prometheus
name: ray-head-monitor
namespace: prometheus-system
spec:
jobLabel: ray-head
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
ray.io/node-type: head
podMetricsEndpoints:
- port: metrics
relabelings:
- action: replace
sourceLabels:
- __meta_kubernetes_pod_label_ray_io_cluster
targetLabel: ray_io_cluster
- port: as-metrics
relabelings:
- action: replace
sourceLabels:
- __meta_kubernetes_pod_label_ray_io_cluster
targetLabel: ray_io_cluster
- port: dash-metrics
relabelings:
- action: replace
sourceLabels:
- __meta_kubernetes_pod_label_ray_io_cluster
targetLabel: ray_io_cluster
对于PodMonitor配置,在Kubernetes集群中会被Prometheus服务自动采集(如果安装了开源Prometheus Operator组件,配置也会自动生效)。
在RayServe代码中自定义监控指标
框架内置的指标解决了基础监控问题,但如果想根据用户类型、请求内容或优先级来统计请求,按模型版本或输入Token数据来统计响应性能、模型全方位评估、推理结果准确度、输入数据质量等,就需要通过自定义指标埋点。这需要具备Python开发能力并掌握Prometheus指标模型,但能帮你建立最贴近业务的直接监控指标。
下面是一个借助ray.serve.metrics类库实现自定义指标埋点的用例:
from ray import serve
from ray.serve import metrics
import time
import requests
@serve.deployment
class MyDeployment:
def __init__(self):
self.num_requests = 0
self.my_counter = metrics.Counter(
"my_counter",
description=("The number of odd-numbered requests to this deployment."),
tag_keys=("model",),
)
self.my_counter.set_default_tags({"model": "123"})
def __call__(self):
self.num_requests += 1
if self.num_requests % 2 == 1:
self.my_counter.inc()
my_deployment = MyDeployment.bind()
serve.run(my_deployment)
while True:
requests.get("http://localhost:8000/")
time.sleep(1)
KubeRay基础监控
RayCluster基础监控
(二)大模型框架vLLM
vLLM作为专注于大规模语言模型推理的高性能框架,旨在解决大模型推理过程中的性能瓶颈问题,提供高效的批处理机制、显存优化与分布式推理支持,适合处理高并发和长序列输入场景。生产部署基于DeepSeek的推理应用,多半会在选Ray的同时,选择vLLM框架。
vLLM更贴近模型推理过程,通常基于它将大模型切分为多个Block分布式运行,因此vLLM也能提供更细分的推理性能监控指标。
vLLM内置指标说明
1. 系统状态相关指标
| 指标名称 | 默认标签 | 指标说明 |
| vllm:num_requests_running | labelnames | 当前在GPU上运行的请求数量。 |
| vllm:num_requests_waiting | labelnames | 等待处理的请求数量。 |
| vllm:lora_requests_info | [labelname_running_lora_adapters, labelname_max_lora, labelname_waiting_lora_adapters] | LoRA请求的相关统计信息,包括正在运行的LoRA适配器数量、最大LoRA数量和等待中的LoRA适配器数量。 |
| vllm:num_requests_swapped | labelnames | 被交换到CPU的请求数量。 |
| vllm:gpu_cache_usage_perc | labelnames | GPU KV缓存的使用率(1表示100%使用)。 |
| vllm:cpu_cache_usage_perc | labelnames | CPU KV缓存的使用率(1表示100%使用)。 |
| vllm:cpu_prefix_cache_hit_rate | labelnames | CPU前缀缓存的命中率。 |
| vllm:gpu_prefix_cache_hit_rate | labelnames | GPU前缀缓存的命中率。 |
2. 迭代统计相关指标
| 指标名称 | 默认标签 | 指标说明 |
| vllm:num_preemptions_total | labelnames | 引擎中累计的抢占次数。 |
| vllm:prompt_tokens_total | labelnames | 预填充阶段处理的token总数。 |
| vllm:generation_tokens_total | labelnames | 生成阶段处理的token总数。 |
| vllm:tokens_total | labelnames | 预填充阶段与生成阶段处理的token总数之和。 |
| vllm:iteration_tokens_total | labelnames | 每次引擎步长中处理的token数量分布直方图。 |
| vllm:time_to_first_token_seconds | labelnames | 生成第一个token所需时间的分布直方图(单位:秒)。 |
| vllm:time_per_output_token_seconds | labelnames | 每个输出token的生成时间分布直方图(单位:秒)。 |
3. 请求统计相关指标
(1) 延迟相关
| 指标名称 | 默认标签 | 指标说明 |
| vllm:e2e_request_latency_seconds | labelnames | 请求端到端延迟的分布直方图(单位:秒)。 |
| vllm:request_queue_time_seconds | labelnames | 请求在等待队列中的时间分布直方图(单位:秒)。 |
| vllm:request_inference_time_seconds | labelnames | 请求在推理阶段的时间分布直方图(单位:秒)。 |
| vllm:request_prefill_time_seconds | labelnames | 请求在预填充阶段的时间分布直方图(单位:秒)。 |
| vllm:request_decode_time_seconds | labelnames | 请求在解码阶段的时间分布直方图(单位:秒)。 |
| vllm:time_in_queue_requests | labelnames | 请求在队列中花费的时间分布直方图(单位:秒)。 |
(2) 模型执行时间
| 指标名称 | 默认标签 | 指标说明 |
| vllm:model_forward_time_milliseconds | labelnames | 模型前向传播的时间分布直方图(单位:毫秒)。 |
| vllm:model_execute_time_milliseconds | labelnames | 模型执行函数的时间分布直方图(单位:毫秒)。 |
(3) Token处理
| 指标名称 | 默认标签 | 指标说明 |
| vllm:request_prompt_tokens | labelnames | 请求中预填充阶段处理的token数量分布直方图。 |
| vllm:request_generation_tokens | labelnames | 请求中生成阶段处理的token数量分布直方图。 |
| vllm:request_max_num_generation_tokens | labelnames | 请求中最大生成token数量分布直方图。 |
(4) 请求参数
| 指标名称 | 默认标签 | 指标说明 |
| vllm:request_params_n | labelnames | 请求参数n的分布直方图。 |
| vllm:request_params_max_tokens | labelnames | 请求参数max_tokens的分布直方图。 |
(5) 请求成功率
| 指标名称 | 默认标签 | 指标说明 |
| vllm:request_success_total | labelnames + [Metrics.labelname_finish_reason] | 成功处理的请求数量计数器,按完成原因分类。 |
4. 推测解码相关指标
| 指标名称 | 默认标签 | 指标说明 |
| vllm:spec_decode_draft_acceptance_rate | labelnames | 推测解码中草稿token的接受率(Gauge类型)。 |
| vllm:spec_decode_efficiency | labelnames | 推测解码系统的效率(Gauge类型)。 |
| vllm:spec_decode_num_accepted_tokens_total | labelnames | 被接受的推测token总数计数器。 |
| vllm:spec_decode_num_draft_tokens_total | labelnames | 生成的草稿token总数计数器。 |
| vllm:spec_decode_num_emitted_tokens_total | labelnames | 发出的推测token总数计数器。 |
5. 默认标签说明
- labelnames: 动态字段,表示指标的标签维度,例如模型名称、请求路径等。
- Metrics.labelname_finish_reason: 表示请求完成的原因(如成功、失败等)。
- Metrics.labelname_waiting_lora_adapters: 表示等待中的LoRA适配器数量。
- Metrics.labelname_running_lora_adapters: 表示正在运行的LoRA适配器数量。
- Metrics.labelname_max_lora: 表示最大LoRA数量。
采集vLLM服务指标
vLLM通过OpenAI兼容API服务上的 /metrics 指标端点公开指标,下面是一个用例:
$ curl http://0.0.0.0:8000/metrics
# HELP vllm:iteration_tokens_total Histogram of number of tokens per engine_step.
# TYPE vllm:iteration_tokens_total histogram
vllm:iteration_tokens_total_sum{model_name="unsloth/Llama-3.2-1B-Instruct"} 0.0
vllm:iteration_tokens_total_bucket{le="1.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="8.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="16.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="32.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="64.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="128.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="256.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
vllm:iteration_tokens_total_bucket{le="512.0",model_name="unsloth/Llama-3.2-1B-Instruct"} 3.0
...
如果vLLM服务部署到Kubernetes中,同样可以通过PodMonitor配置来采集。下面是一个简单配置用例,要求vLLM的Deployment中给Pod配置标签 app: vllm-server:
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: vllm-monitor
namespace: vllm-demo
labels:
release: prometheus
spec:
jobLabel: vllm-monitor
namespaceSelector:
matchNames:
- default
selector:
matchLabels:
app: vllm-server
自定义指标的实现
自定义指标有两种方案:
- 如果将vLLM结合Ray使用,可以直接使用Ray的相关工具类,例如:
from ray.util import metrics as ray_metrics
- 直接使用Prometheus Python SDK。
# begin-metrics-definitions
class Metrics:
"""
vLLM uses a multiprocessing-based frontend for the OpenAI server.
This means that we need to run prometheus_client in multiprocessing mode.
See https://prometheus.github.io/client_python/multiprocess/ for more
details on limitations.
"""
(三)IaaS计算层监控
GPU设备监控
监控重点:GPU利用率、显存使用情况、GPU温度。GPU利用率直接影响推理性能,显存不足会导致推理失败,过高的温度可能损坏硬件。取决于推理服务部署方式的不同,需要统一将GPU设备的监控指标进行采集。
GPU设备部分监控指标
计算节点监控
- 监控重点:高性能网络、基础网络、CPU使用率、内存使用率、磁盘I/O。这些指标反映计算节点整体性能。
- 难题:计算节点数量众多,且可能存在异构环境,监控数据量大且复杂。
- Prometheus解决方案:利用Prometheus的节点自动发现机制,动态发现新的计算节点并安装全套数据采集探针,采集全套性能指标,通过标签对不同节点进行分类管理。
(四)推理应用编排层监控
Kubernetes容器服务
将Ray Serve和vLLM结合部署在Kubernetes环境中,可以充分发挥两者的技术优势,同时利用Kubernetes的强大编排能力,构建高性能、弹性伸缩且易于管理的AI推理服务架构。这种组合在Kubernetes部署中的主要优势:
- Ray Serve的动态伸缩能力:支持根据实时流量动态调整模型副本数量,避免资源浪费或性能瓶颈;在Kubernetes中可以通过Ray的资源调度器为每个副本分配特定的CPU/GPU资源,确保资源利用率最大化。
- vLLM的高性能推理:批处理机制和显存优化技术能够高效利用GPU资源,在高并发场景下显著降低延迟并提高吞吐量;对于超大规模模型,vLLM可以通过分布式推理切分模型并在多个GPU上运行,而Kubernetes提供了跨节点的GPU资源管理能力。
- Kubernetes的HPA:可以与Ray Serve的动态伸缩功能结合使用,根据请求负载自动扩展或缩减推理服务的实例数量,进一步增强弹性。
对于Kubernetes集群,Prometheus监控方案天然集成,重点监控以下几个维度:
- 集群管控服务能力,包括API Server、Scheduler、Controller等组件的性能和容量。从Node和Pod维度监控弹性响应能力。
- 从节点Node和Container维度监控服务Pod级别的算力、流量带宽消耗、磁盘I/O,包括GPU算力,精确到Pod级别。
- 基于eBPF技术分析Pod之间或节点之间的网络通信,是否存在网络I/O瓶颈、异常网络通信等。通常推理服务加载模型有两种模式——直接容器镜像加载或通过NAS/OSS加载,加载速度跟网络I/O强相关。
(五)PaaS平台层
AI网关监控
监控重点:网关的请求吞吐量、请求延迟、错误率。AI网关作为推理服务入口,其性能直接影响用户体验。AI推理服务目前通常是流式请求,每个推理请求的响应持续时间长,一旦出现大并发访问,容量压力很大,全访问监控对于服务稳定性至关重要。
弹性推理服务监控
很多企业会选择直接使用弹性推理服务来部署推理模型。这类平台可以直接获取服务实例的运行状态、资源利用率、任务队列长度等一系列监控指标,这些指标反映服务的运行健康状况。Prometheus服务与这类平台深度集成,全方位监控数据可以无缝集成到Prometheus服务中。
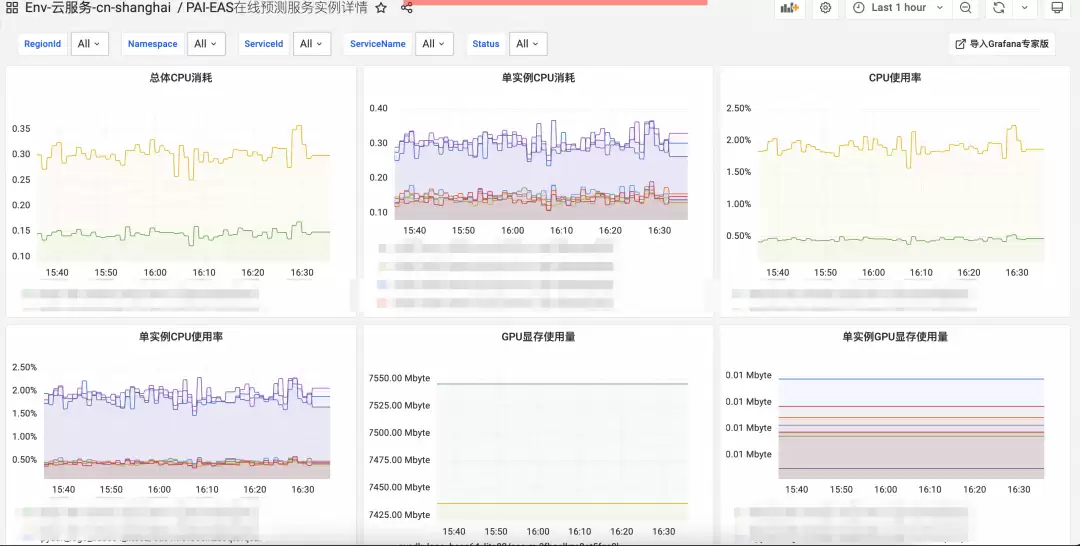
弹性推理服务部分指标监控
四、总结与畅想
AI推理服务的全链路监控需要覆盖从流量入口到算力资源的完整路径,包括防火墙、网关、PaaS平台、中间件服务以及最终核心——GPU算力。Prometheus指标监控方案凭借其灵活的数据采集能力和对多种技术架构的良好适配性,展现出卓越的跨技术栈兼容能力,为全链路监控提供了可靠的基础。基于全套监控数据,在推理服务运行期间可以实现有效监控和对比分析,从而在保障稳定性的同时优化全链路性能。
随着AI推理技术的快速演进,监控方案也需要与时俱进。未来,通过引入AI技术对监控数据流进行智能分析,可以实现性能瓶颈的自动识别与优化策略的自动执行,推动推理服务向自我优化方向迈进。这不仅能够提升系统的稳定性和效率,还将大幅降低运维复杂度,为AI推理服务的规模化部署提供更强有力的支持。