自然语言处理(NLP)中,如何让机器从海量文本里精准捕捉关键信息?一个看似微小却至关重要的步骤,就是停用词处理。不少人认为这不过是筛掉“的、了、是”这类词,但在实际应用中,它直接影响高频词提取的效果、词云图的展示质量乃至整个分析结果的可靠性。本文将从实战角度出发,分享停用词的处理技巧,以及如何快速获取高质量的停用词库。
一、停用词概述
所谓停用词(stopwords),指的是在文本中频繁出现但携带的实际语义较少的词语。它们通常是功能词、虚词,甚至包括标点符号——中文里的“的”“是”“和”“了”“。”,英文里的“the”“is”“and”“...”等。这些词在句子结构中必不可少,但在文本分析时却容易成为噪声:它们会分散统计权重,导致算法将注意力浪费在无意义的词上。通过过滤停用词,既能降低数据复杂度、提升处理效率,也能让分析结果更聚焦于真正的主题词,从而提升文本挖掘的准确度。
二、停用词的典型应用场景
2.1 高频词提取
使用jieba.analyse提取高频词时,可以事先将停用词写入文本文件(例如stopwords.txt),然后通过一行代码挂载:
jieba.analyse.set_stop_words('stopwords.txt')这样一来,“的、了、在”这类词就不会出现在高频词列表中,结果会显得更加干净、聚焦。
2.2 词云图生成
用wordcloud制作词云图时,停用词的作用同样显著。WordCloud对象提供了stopwords参数,只需传入需要屏蔽的词即可。不过在实际操作中,通常需要反复迭代——先加入一批停用词,观察效果,再补充一批,直到词云图真正凸显出有意义的主题词。

▲ 图1:加入停用词后的「淄博烧烤」词云图

▲ 图2:未加入停用词的「淄博烧烤」词云图
对比两图,效果一目了然:图2中混杂了大量“一个”“这个”“就是”“什么”等干扰词,严重影响了主题词的呈现;图1经过停用词过滤后,“淄博烧烤”“美食”“推荐”等核心词变得清晰突出。因此,停用词在文本可视化任务中绝非可有可无的环节,而是决定分析质量的关键步骤。
三、停用词的获取方法
3.1 自定义停用词表
学术界和工业界已公开了不少成熟的停用词表,例如中文停用词表、哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库等。直接选用现成词表,远比从头构建更高效。
以哈工大停用词表为例,读取代码十分简洁:
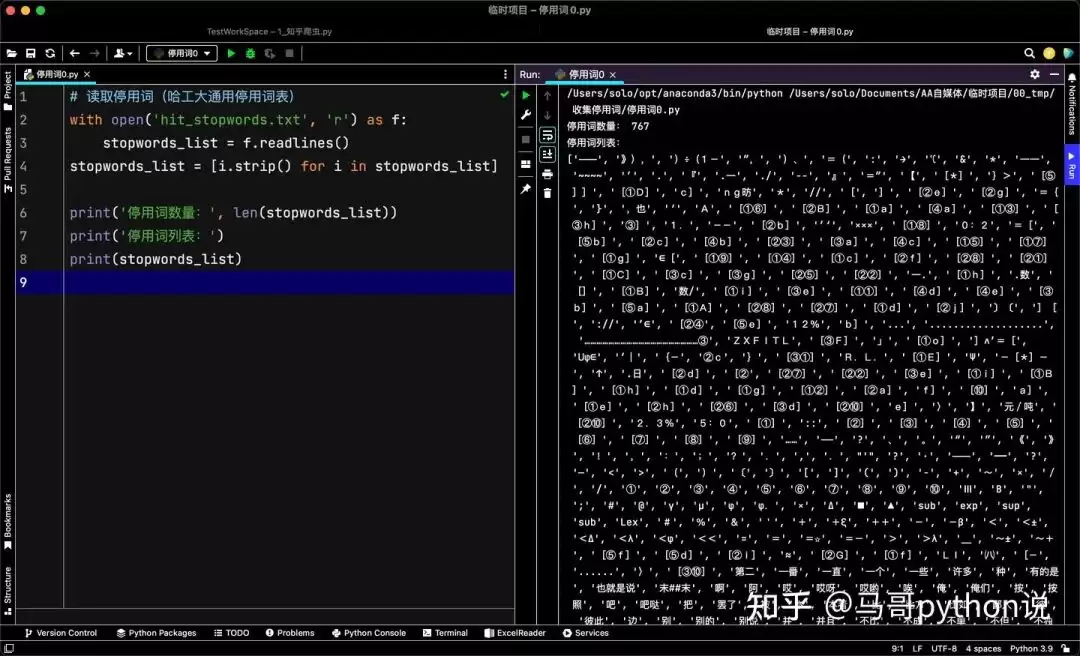
# 读取停用词(哈工大通用停用词表)
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
print('停用词数量:', len(stopwords_list))
print('停用词列表:')
print(stopwords_list)
▲ 自定义停用词表展示
可见,这份中文停用词表覆盖相当全面,共包含767个词。常用的虚词、代词、介词基本都已囊括在内。
(此处删除原文中的公众号推广信息)
3.2 使用wordcloud调用停用词
wordcloud库自带了英文停用词库,通过STOPWORDS变量即可直接引用:
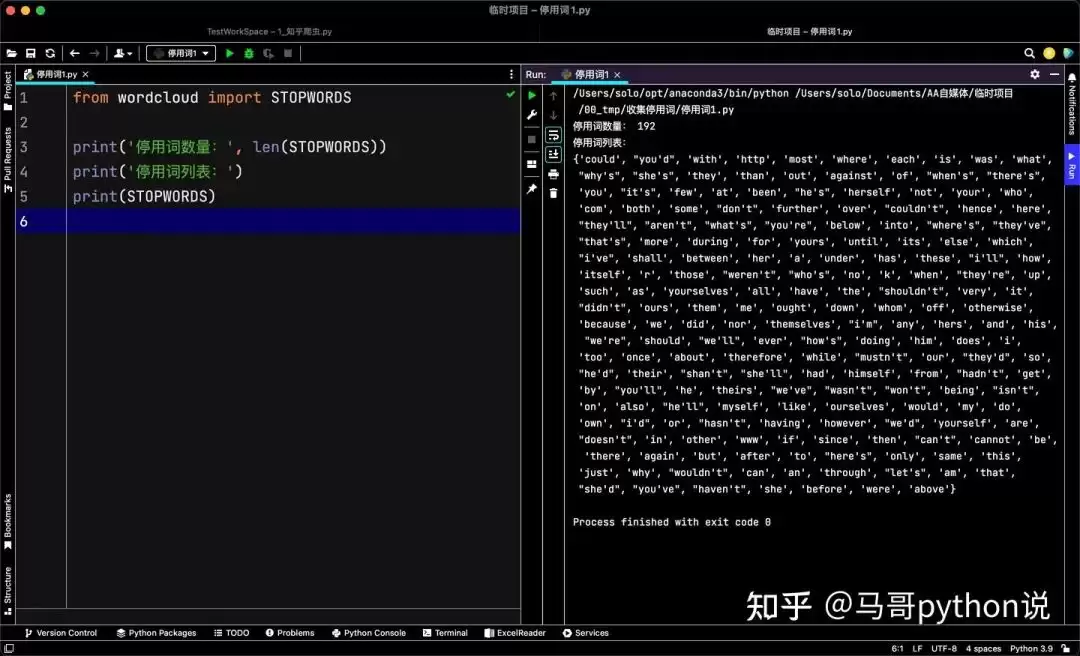
from wordcloud import STOPWORDS
print('停用词数量:', len(STOPWORDS))
print('停用词列表:')
print(STOPWORDS)
▲ 使用wordcloud调用停用词
wordcloud内置了192个常用英文停用词,在绘制英文词云时基本够用。
3.3 使用nltk调用停用词
nltk(Natural Language Toolkit)是NLP领域的老牌工具库,内置了多种语言的停用词表,支持直接下载使用。
3.3.1 nltk中文停用词
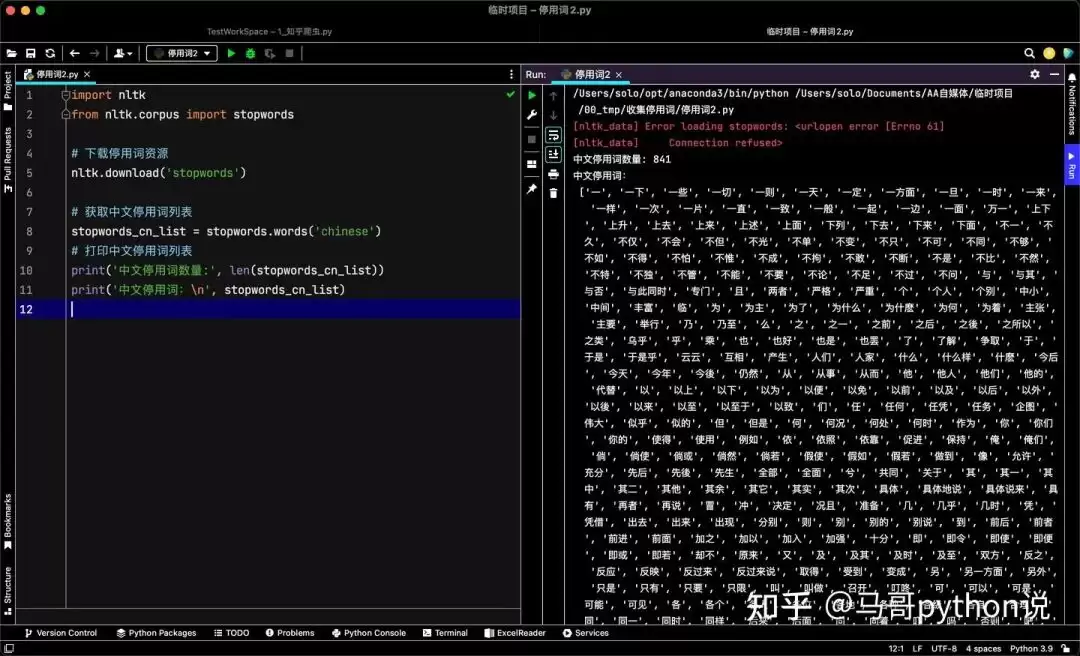
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords_cn_list = stopwords.words('chinese')
print('中文停用词数量:', len(stopwords_cn_list))
print('中文停用词:\n', stopwords_cn_list)
▲ nltk中文停用词展示
结果:共841个中文停用词,比哈工大词表更多,覆盖面更广。
3.3.2 nltk英文停用词
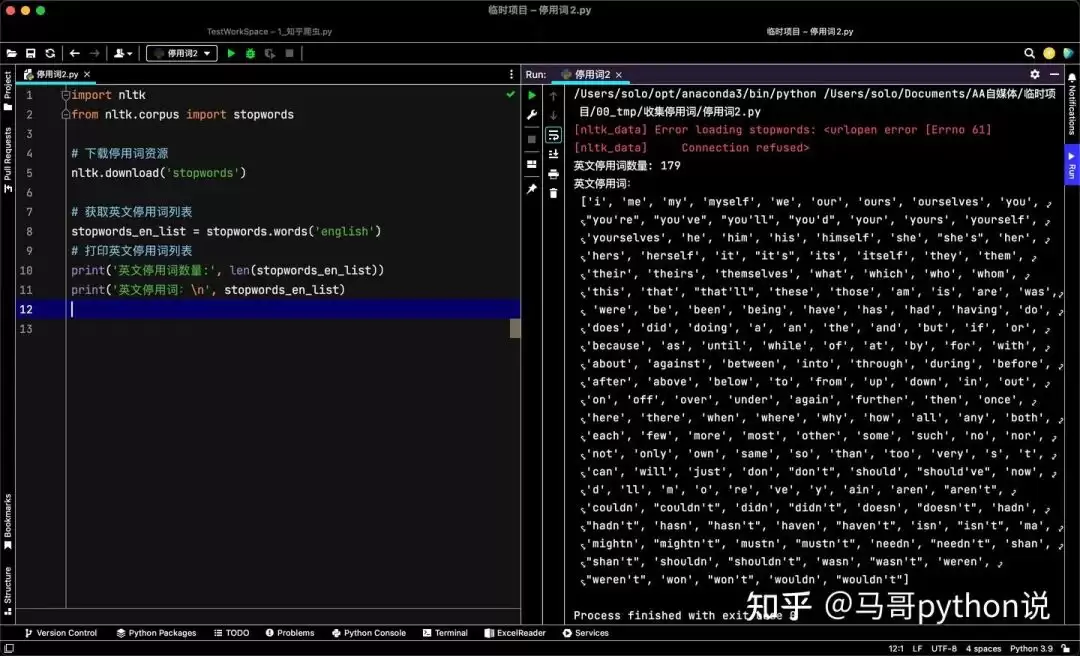
import nltk
from nltk.corpus import stopwords
nltk.download('stopwords')
stopwords_en_list = stopwords.words('english')
print('英文停用词数量:', len(stopwords_en_list))
print('英文停用词:\n', stopwords_en_list)
▲ nltk英文停用词展示
nltk英文停用词共179个,虽然比wordcloud略少,但常见的a、an、the、is等均已包含。
3.4 使用sklearn调用停用词
sklearn主要用于机器学习,但其feature_extraction.text模块也内置了英文停用词表:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
print('停用词数量:', len(ENGLISH_STOP_WORDS))
print('停用词列表:')
print(list(ENGLISH_STOP_WORDS))
▲ sklearn调用停用词展示
sklearn共提供318个英文停用词,比nltk版本更加丰富。
3.5 使用gensim调用停用词
gensim常用于主题建模和文本预处理,其parsing.preprocessing模块也内置了停用词表:
from gensim.parsing.preprocessing import STOPWORDS
print('停用词数量:', len(STOPWORDS))
print('停用词列表:')
print(list(STOPWORDS))
▲ gensim调用停用词展示
gensim共包含337个英文停用词,适合在主题模型等任务中直接使用。
3.6 使用spacy调用停用词
spacy是一款高性能NLP库,其语言模型内置了停用词集,可通过nlp.Defaults.stop_words获取:
import spacy
nlp = spacy.load("en_core_web_sm")
stopwords = nlp.Defaults.stop_words
print('停用词数量:', len(stopwords))
print('停用词列表:')
print(list(stopwords))
▲ spacy调用停用词展示
spacy共包含326个英文停用词,与sklearn数量接近,但具体词表略有差异。
以上列出的6种停用词获取方法,覆盖了中文与英文两种场景。在实际项目中,可以先用这些现成词表作为基础,再根据业务数据手动补充专属停用词——例如,某些领域的专有名词若成为干扰项,也应当加入停用词列表。经过多轮迭代后,文本分析的质量将显著提升。