近年来,机器学习模型算法在工业领域的应用日益广泛。在滴滴出行,大量在线策略正从传统规则算法逐步转向机器学习模型。随之而来的核心挑战是——如何构建有效的质量保障体系?这无疑是一个棘手但必须攻克的问题。本文将系统梳理整体思路,并重点介绍滴滴质量团队在模型效果评估方面的具体实践。
背景
近些年来,技术迭代迅速,机器学习模型算法在众多领域取得了显著成果,尤其是基于深度学习的语音、图像等智能化应用表现突出。在滴滴,拼车排队预估模型、司机调度异常管控模型、取消率预测模型等均收获了良好效果。然而,机器学习与传统软件存在本质差异:传统软件行为可预设,输入与输出关系明确,逻辑可解释;而机器学习模型,特别是分类模型,依赖海量数据训练,输入数据与标签后,训练过程如同黑盒,无法预先确定输出结果。因此,测试面临诸多难点:
(1)样本获取困难,例如安全分单模型数据稀疏;
(2)数据质量难以把控,数据规模巨大,无法做到细粒度验证;
(3)特征质量如何评估,包括有效性与相关性;
(4)模型效果验证,业界普遍依赖业务指标,但业务指标仅能反映宏观趋势,难以精确定位迭代方向。
模型质量保障方案
有观点认为:数据和特征决定了机器学习的上限,模型和算法只是逼近这一上限的工具。因此,测试前需明确几个关键问题:
(1)模型能力达到何种标准方可准出?
(2)怎样的测试数据能有效度量模型能力?
(3)如何评估特征的质量?
(4)如何从用户视角对线上模型效果进行评测?
模型从训练到线上应用的基本流程如下:
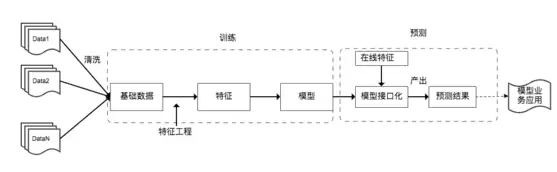
从流程图中可以看出,模型质量保障主要涉及数据质量、特征质量、模型算法质量和模型效果评测几个方面。接口层还需考虑性能与稳定性。此外,线上模型的安全性同样不容忽视,特别是无监督的深度神经网络——攻击者可能精心构造样本来污染训练数据,或通过噪声干扰“欺骗”模型,导致其做出错误判断。
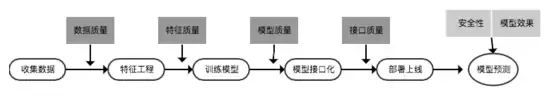
进一步细化,得到如下模型质量保障总体方案:
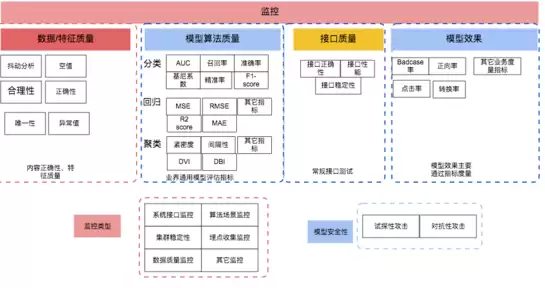
我司模型质量保障现状
目前滴滴在模型质量保障方面的落地,主要集中在数据质量、接口质量、模型监控、模型效果评测四个方向。其中模型监控已在各质量团队广泛部署,成为主要的兜底手段。模型算法质量方面,仍由策略同学自行测算;而用户视角下的特征有效性与特征相关性等度量,尚有较大提升空间。
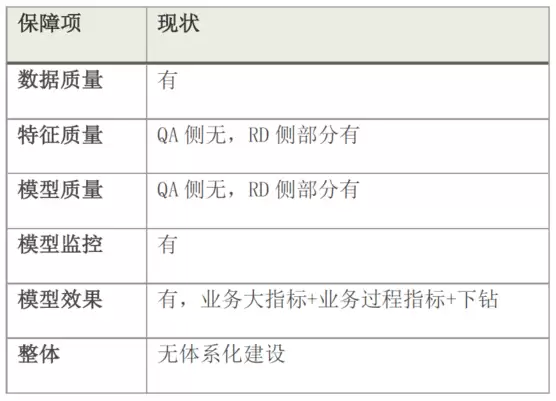
当前突出问题在于:模型从训练到上线所依赖的基础服务分散在各个质量团队,彼此之间存在断层,缺乏体系化平台支持。好消息是,原本分散的机器学习模型训练与部署平台正逐步收敛至统一的策略中台,1.0版本已上线运行。因此,后续工作重心将转向搭建体系化的模型质量保障平台,同时在特征质量和模型效果评测领域持续深耕,将通用能力抽象并落地到平台中。下图归纳了当前现状:
模型效果评测实践
背景
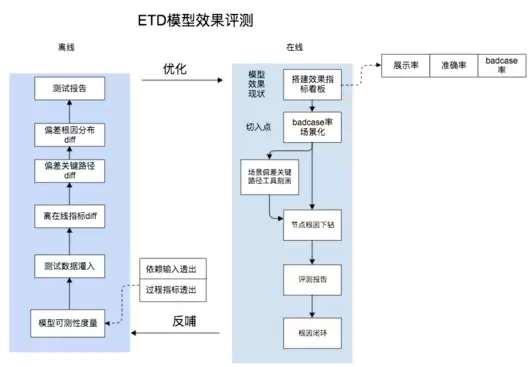
质量团队长期聚焦于线上策略评测与异常样本挖掘,积累了丰富的策略线上效果评估经验。一次偶然的机会,团队开始对拼车ETD模型进行效果评测。演进路线为先线上后离线:线上主要从城市、业务线、场景等多个维度开展模型效果应用指标评估,帮助策略同学更直观地识别主要偏差场景;随后对模型业务链路进行建模,将真实样本数据映射到各节点,度量出关键偏差路径;最后复用既往积累的异常样本下钻能力,对模型业务链路上的关键偏差节点进行根因下钻,发掘出部分影响模型效果的新特征。
方案及落地
具体方案如下:
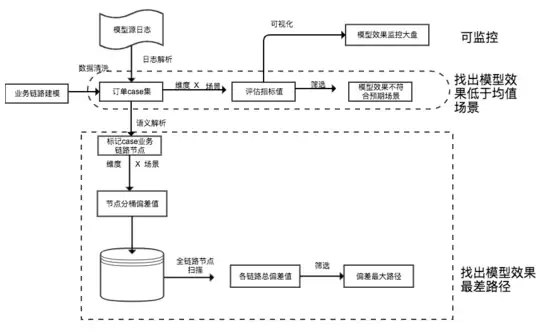
其中模型偏差关键路径核心算法如下:
模型效果评测的价值点
总体而言,在机器学习模型效果评测方面,价值点主要体现在以下几个方面:
(1)场景化模型效果度量
(2)偏差关键路径发现
(3)模型潜在新特征的挖掘
(4)依赖项对模型效果的负向影响度量
总结
当前,模型质量保障在国内外大型互联网公司中仍多处于探索阶段。原因很简单:相比传统质量保障,其难度与技术门槛更高,且模型的应用背景千差万别。在滴滴,整体模型质量保障尚缺乏体系化建设,特征度量方面基本未正式落地。不过,得益于质量团队在线上策略评测与异常样本挖掘方面的长期积累,模型效果评测领域相对业界更为深入,走在了前列。这些工作对实际模型效果的提升起到了良好的辅助作用。但下一步仍需将模型评测的通用能力进行抽象,打造为平台化工具,使策略团队能够更轻量、高效地找到模型效果提升的切入点。