咱们继续扫一眼RAG相关的新进展,重点聊三件事。
一个是用推理模型做翻译这事儿,最近DeepSeek R1这类推理模型热度很高,把它用在翻译上会是什么效果?一个是怎么量化地评估RAG里chunk分得好不好?这个比较关键,直接关系到检索质量。还有一个是GraphRAG里局部信息和全局信息之间存在鸿沟、以及实体相似性不够的问题,有没有什么新解法?
抓住根本问题,做根因,专题化,体系化,才能沉淀出更深的东西。一起进步。
一、推理模型用于机器翻译会成啥样?
最近有篇挺有意思的工作,《New Trends for Modern Machine Translation with Large Reasoning Models》(https://arxiv.org/pdf/2503.10351),里面提出一个核心观点:LRM(大型推理模型)把翻译这件事,从传统的“输入-输出”映射,重新定义成了一个需要上下文支持的动态推理任务。这就碘伏了传统的神经机器翻译(NMT)和基于LLM的MT范式。
具体来说,变革体现在三个方向:第一,语境连贯性——LRM能通过跨句子和复杂语境的显式推理,处理歧义,保留话语结构,甚至在缺乏上下文的时候也能做推断。第二,文化意向性——模型不再是机械地转码,而是能推断说话人的意图、受众的预期以及社会语言规范,调整输出风格。第三,自我反思——LRM可以在推断阶段自我审视,主动纠正翻译中的潜在错误,尤其是在非常嘈杂的场景下,鲁棒性比单纯的X→Y映射要好很多。
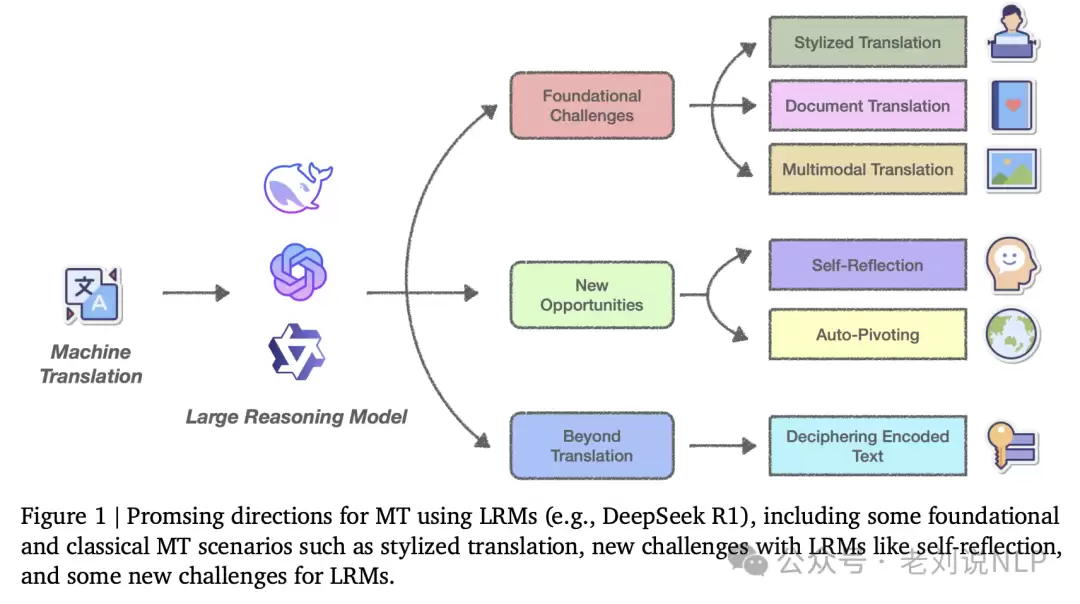
这个思路主要用于三种翻译场景:
风格化翻译
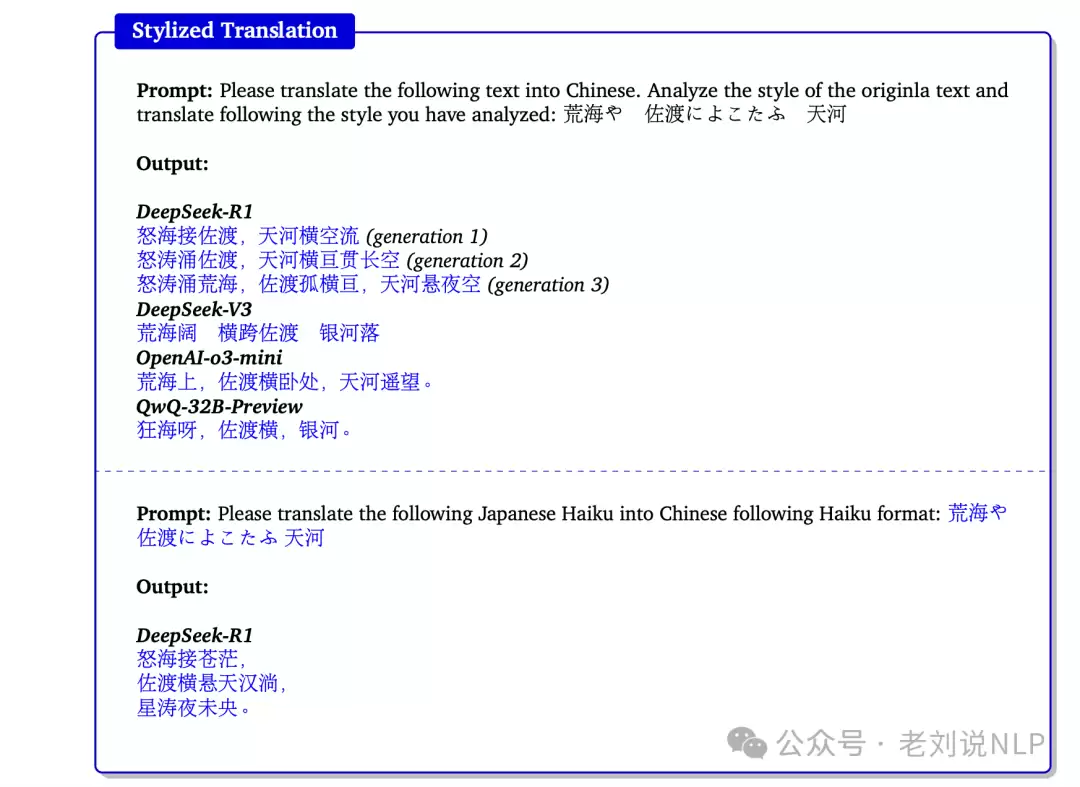
文档级翻译

多模态翻译

二、如何量化RAG中chunk的有效性?
《MoC: Mixtures of Text Chunking Learners for Retrieval-Augmented Generation System》(https://arxiv.org/pdf/2503.09600)这篇工作,尝试回答一个棘手问题:chunk分得好不好,能不能不看下游任务、直接量化评估?
作者引入了两个新指标:边界清晰度(Boundary Clarity, BC)和分块粘性(Chunk Stickiness, CS)。有意思的是,在许多实验里,语义分块并没有表现出显著的性能优势——这个结论本身就很值得思考。
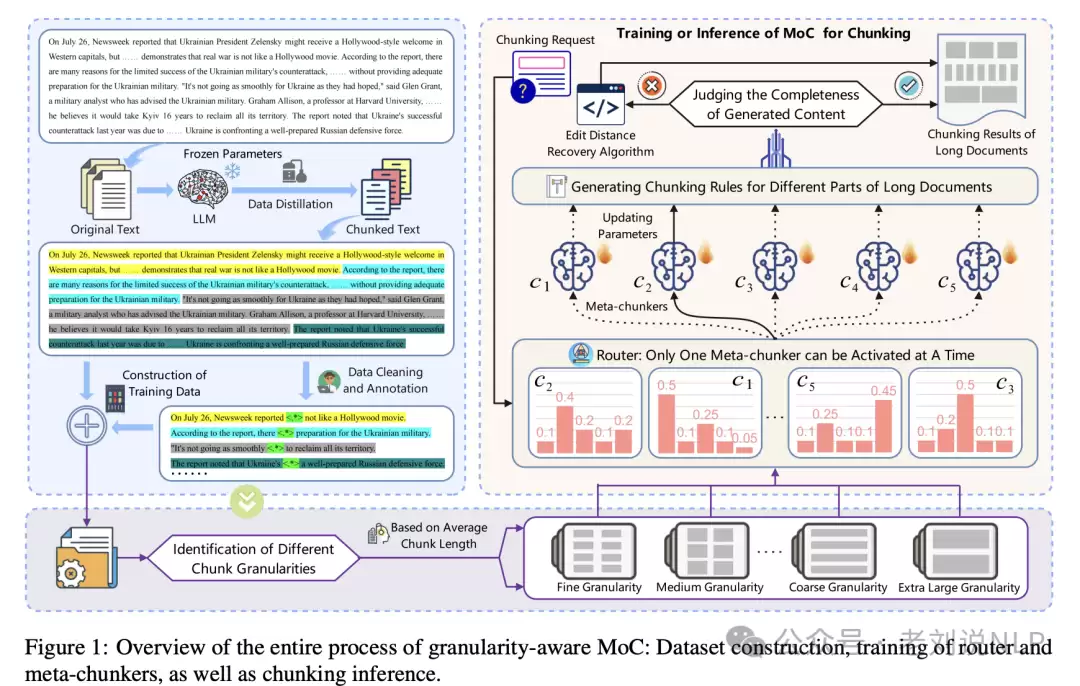
下面分别看一下这两个指标怎么用。
1、边界清晰度(BC)
这个指标用来评估分块在“分隔语义单元”方面的能力。说白了,就是看边界切得准不准。
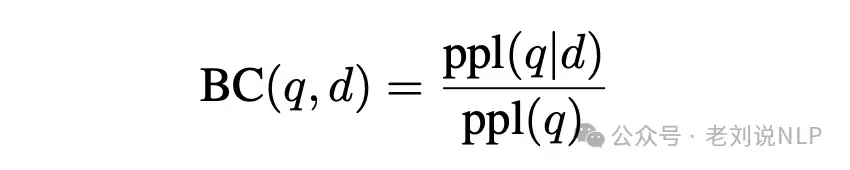
公式里,ppl(q)表示句子序列q的困惑度,ppl(q | d)表示给定上下文d下的对比困惑度。困惑度越低,说明模型对文本理解得越好;困惑度越高,则表明语义层面的不确定性大。边界清晰度的值越接近1,说明分块能有效分离语义单元;值越低,则说明边界模糊,容易造成信息混淆。
2、分块粘性(CS)
这个指标用来衡量文本块之间的紧密性和顺序完整性。具体做法是构建一个语义关联图,量化网络复杂性。边的权重定义为:
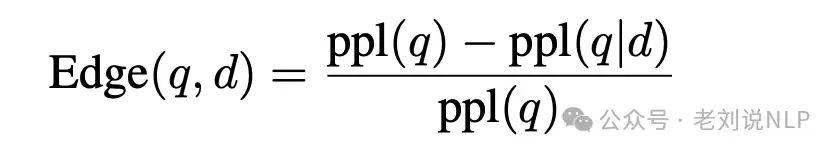
其中权重范围是[0,1]。设定一个阈值K,保留超过该值的边,再计算分块粘性:
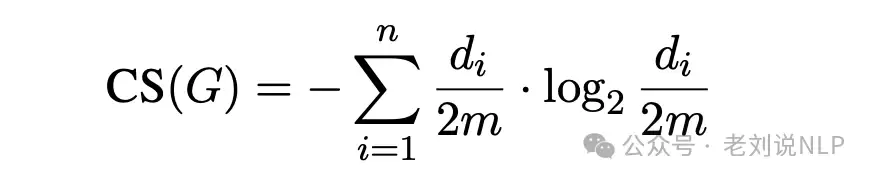
G是构建的语义图,di是节点i的度,m是边的总数。分块粘性值越低,意味着文本块之间语义关系越紧密、更独立;值越高,则说明块与块之间语义关系弱,过于“粘连”。
这两项指标提供了一个相对客观的量化工具,可以在不依赖下游任务的情况下,提前评价chunk策略的质量。
三、HiRAG引入层级结构进行RAG增强?
在RAG系统中,很多方案采用图结构来建模实体之间的关系。但现有方法有一个通病:过度依赖源文档,导致构建的知识图谱里,存在大量“结构上不接近但语义上相似”的实体。此外,在检索上下文时,通常只从全局或局部视角出发,导致局部知识和全局知识之间存在严重的信息断层。怎么搭一座桥,成为关键问题。
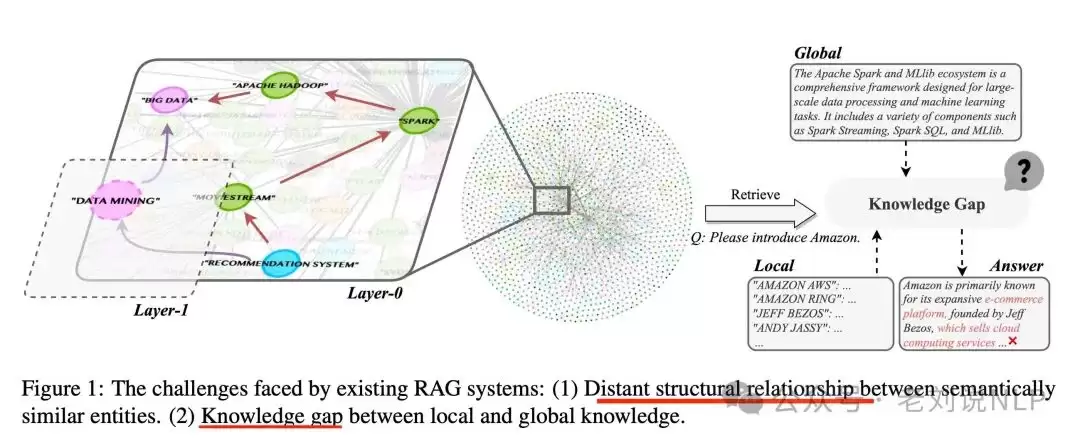
针对这个问题,《Retrieval-Augmented Generation with Hierarchical Knowledge》(https://arxiv.org/pdf/2503.10150)提出了HiRAG,核心是两个模块:分层知识索引(HiIndex)和分层知识检索(HiRetrieval)。
项目代码在:https://github.com/hhy-huang/HiRAG
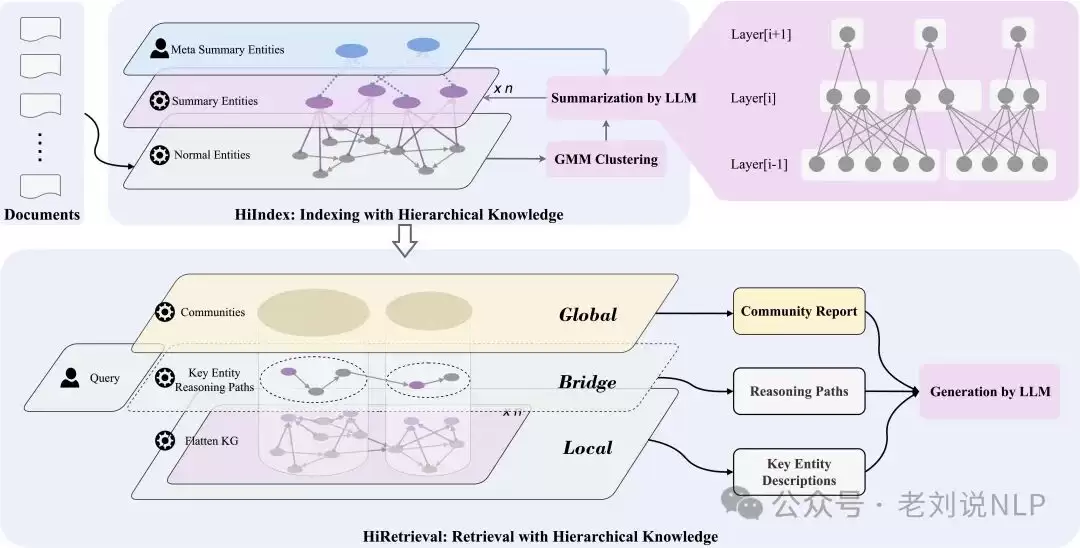
分层知识索引(HiIndex)
这个模块的核心思路,是通过逐层构建层次化的知识图谱,来增强语义相似但结构不接近的实体之间的连接。
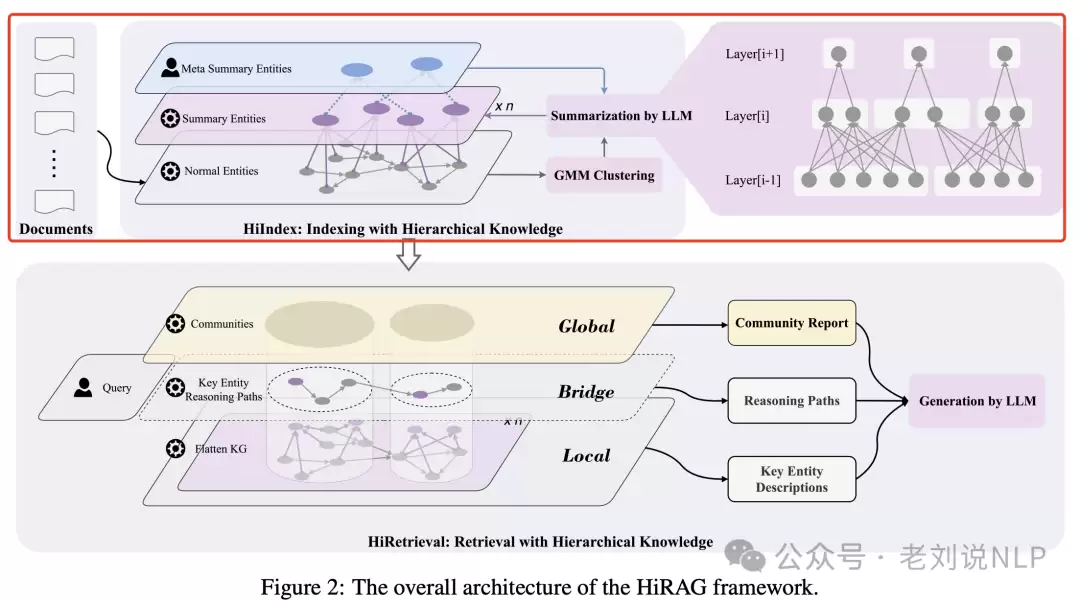
具体步骤包括:
- 基本图谱构建:用实体中心的三元组抽取方法构建基础知识图谱。先把输入文档切成文本块,再用LLM(这里用的是DeepSeek-V3)抽取实体和关系,形成基础图谱。
- 聚类操作:对每一层的实体,用高斯混合模型(GMM)做聚类,生成簇集合——这些簇就代表了同一语义类别下的实体。
- 总结实体生成:用预定义的元总结实体集指导LLM,生成每一层的总结实体,这些实体是对下一层实体的概括。
- 关系更新:在每一层里更新知识图谱,增加层间关系,让高层次的总结实体能连接到低层次的实体。
分层知识检索(HiRetrieval)
这个模块的使命,是把局部知识和全局知识连接起来,解决知识层面的断层问题。
步骤如下:
- 局部知识检索:从层次知识图谱中检索当前层最相关的实体(这里用的嵌入模型是GLM-4-Plus)。
- 全局知识检索:找到与检索到的实体相连的社区集合,并检索这些社区的社区报告——这些报告代表了与查询相关的全局知识。
- 桥接层知识构建:从每个社区中选择与查询最相关的关键实体,找到连接这些实体的最短路径,这就是桥接层知识。这些路径是局部知识和全局知识之间的最短连接。
- 综合上下文输入:把局部层描述、全局层社区报告和桥接层描述,一起喂给LLM(DeepSeek-V3),生成综合答案。
这个工作的价值在于:一方面,层次化的知识图谱在高层次引入摘要实体,相当于给低层中距离较远的实体创建了“快捷方式”,绕开了对细粒度关系的详尽遍历。另一方面,HiRetrieval通过把最相关的顶部n个实体和它们关联的社区链接起来,构建推理路径——这些路径就是局部细节与全局洞察之间的最短连线,让细粒度细节和宽泛的上下文知识都能被有效利用。
当然,这个方案的缺点也很明显:一是构建高质量的分层知识图谱计算需求很大,因为LLM需要在每一层做实体总结;二是检索模块需要更复杂的查询感知排序机制,目前依赖LLM生成的权重做关系排序,可能会影响查询相关性;另外,在HiIndex里,层级数k怎么确定是个棘手的问题,很难拍脑袋定下来。
话说回来,GraphRAG这类方法即使概念上很漂亮,实际落地也一直在打折扣。微软后来出的LazyGraph版本,甚至已经把实体这一步都去掉了——这本身就是对落地压力的妥协。
总结
总体来看,今天聊的三个方向,都是比较有趣的结合点。虽然离真正规模化落地可能还有一段路,但里头“主动评估chunk质量”和“用推理来做翻译”的思路,确实值得借鉴。