一、Mistral OCR 4是什么
Mistral AI这家法国人工智能公司,近期推出了一款专为复杂文档打造的OCR利器——Mistral OCR 4。它不是通用大模型附带的简易扫描功能,而是一个垂直专用的轻量化文档光学字符识别模型,专注于复杂文档的结构化解析。无论是版面、文字、表格、公式、图表还是签名,它都能进行深度识别并分层输出结构化数据,助力企业文档数字化。
别被“轻量”二字误导,它的参数量虽不大,但针对文档识别全链路进行了专项优化。您可以通过API调用、云厂商集成,或直接使用Docker私有化部署。在权威基准测试OmniDocBench上,它斩获93.07分,OlmOCRBench上也达到85.20分。更硬核的是,在600余份混合文档的盲测中,72%的专业评审认为其输出效果更优,连GPT 5.5 Pro、Gemini 3.1 Pro Preview等通用多模态模型的文档识别能力都被它超越。
四、应用场景
这款工具能应用于哪些领域?从企业知识库到医疗档案,覆盖范围非常广泛:
企业RAG智能知识库搭建:它可以自动将文档切分为结构化区块,标题、正文、图表清晰区分,向量检索精度直接拉满,省去额外开发版面解析模块的繁琐工作。
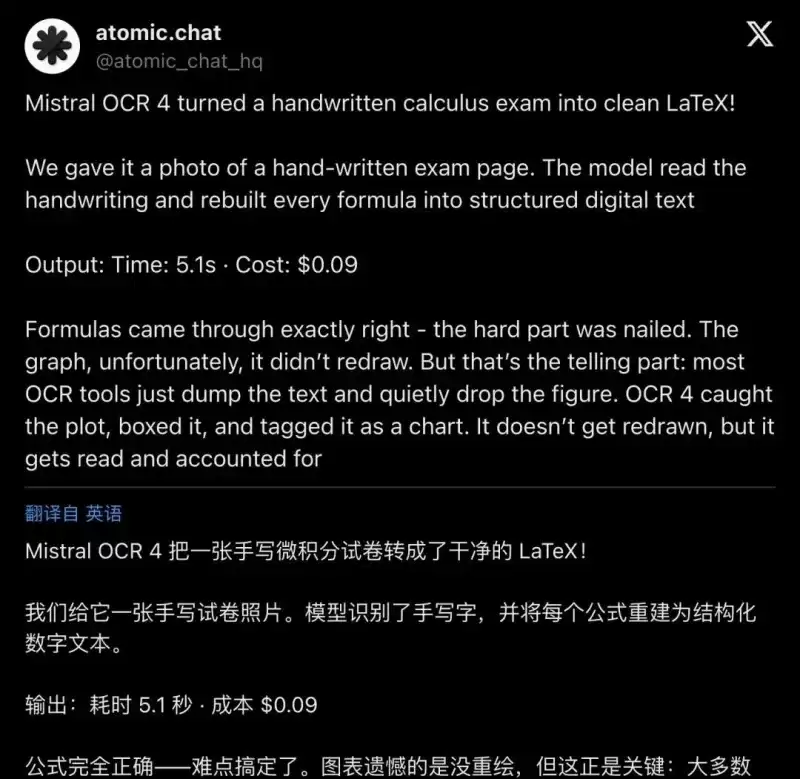
科研/教育数字化:手写试卷、外文论文、实验报告,批量转换为Markdown和LaTeX公式,快速构建线上题库、电子文献库。
金融票据自动化:增值税发票、保单、贷款合同,批量提取金额、编号、客户信息,直接对接财务与风控审批系统,提升办公效率。
跨境法务档案处理:多语种外贸合同、涉外卷宗,批量识别归档,支持双语对照结构化导出,法务人员无需再手动整理。
医疗病历数字化:纸质检验报告、手写病历,扫描识别后结构化入库,轻松对接医院信息系统。
政企档案古籍数字化:历史手写档案、外文地方志,批量扫描识别,完成电子化存储与检索,古籍保护也能借助新技术实现。
五、使用方法
(一)公有云API调用(Python最简示例)
先介绍最直接的API调用方式,用Python几行代码即可上手。
import requests
import os
# 配置官方控制台获取的API密钥
api_key = os.getenv("MISTRAL_API_KEY")
headers = {"Authorization": f"Bearer {api_key}"}
# 1. 本地PDF/图片文件上传
files = {"file": open("business_contract.pdf", "rb")}
params = {"include_blocks": True} # 开启区块、坐标、置信度输出
resp = requests.post("https://api.mistral.ai/v1/ocr", headers=headers, files=files, params=params)
result = resp.json()
# 打印还原排版的Markdown与页面结构化区块
print("文档Markdown内容:", result["markdown"])
print("页面区块结构化数据:", result["pages"][0]["blocks"])(二)私有化Docker部署步骤
如果对数据安全有严格要求,可以选择私有化部署:
登录Mistral企业控制台,下载官方OCR 4标准Docker镜像;
在服务器上拉取镜像,执行容器启动命令,配置好推理资源配额;
本地服务会开放私有API接口,内网业务系统直接调用,所有文档数据保留在企业本地服务器,无需上传公有云。
(三)云厂商托管接入
如果不想自行运维,可以选择云厂商托管。登录Microsoft Azure AI Foundry或Amazon SageMaker控制台,搜索Mistral OCR 4托管模型,一键开通调用权限,云厂商的身份鉴权、流量管控、日志审计均可直接复用。
(四)定价标准
价格方面,非常具有竞争力:
基础纯OCR接口:4美元/千页,批量处理可享五折优惠,仅需2美元/千页;
Document AI自定义字段抽取:5美元/千页;
新注册开发者可获得免费试用额度,方便先测试效果再决定。

六、竞品对比
将Mistral OCR 4与GPT-4o OCR(OpenAI)和Google Document AI进行对比,差异一目了然。
| 对比维度 | Mistral OCR 4 | GPT-4o OCR | Google Document AI |
|---|---|---|---|
| 产品定位 | 独立垂直轻量化专业OCR模型 | 通用多模态模型内嵌附带OCR能力 | 谷歌云专用文档识别工具 |
| 支持语言数量 | 170种(含小众低资源语种) | 约100种主流语种 | 约86种主流语种 |
| 像素级区块坐标输出 | 原生完整支持 | 无原生坐标,仅文本段落分段 | 简易区块标注,无精准像素坐标 |
| 手写公式转LaTeX | 原生高精度支持 | 识别不稳定,公式易丢失 | 仅印刷简单公式识别 |
| 私有化离线部署 | 官方Docker容器一键部署 | 不支持本地私有化 | 仅谷歌云托管,本地部署成本极高 |
| 批量处理速度 | 2000页/分钟 | 数百页/分钟,并发受限 | 约800页/分钟 |
| 企业数据合规 | 公有云/本地离线双方案 | 数据必须上传OpenAI公有云 | 数据留存谷歌云服务器 |
| 批量处理优惠 | 千页原价4美元,批量5折 | 无批量折扣,单价固定 | 批量阶梯小幅降价 |
| 基准OmniDocBench分数 | 93.07 | 低于90分 | 83.52分 |
从表中可以看出,Mistral OCR 4在多个维度上领先对手,尤其在语言覆盖、坐标输出、私有化部署和批量处理速度方面优势明显。
七、常见问题解答(FAQ)
Q1:Mistral OCR 4和通用大模型自带的PDF解析有什么本质区别?
A:通用大模型做文档解析属于副业,优先满足对话问答,版面坐标、表格边界、手写公式细节基本丢失。Mistral OCR 4则是主业,所有算力都用于优化文档版面、区块分类、坐标定位,输出标准化的结构化JSON和Markdown,直接对接RAG、自动化流程、档案数字化,不会为了对话推理牺牲文档细节。
Q2:私有化部署是否会降低识别精度?
A:不会。公有云API和Docker私有化镜像使用完全相同的模型权重和推理逻辑,只是数据传输链路不同。私有化仅改变数据存储位置,识别准确率、公式解析、多语种识别效果与云端完全一致。
Q3:单文件上传大小上限是多少,支持多页PDF批量上传吗?
A:单文件最大10MB,支持几十到几百页的多页PDF完整解析。批量任务可通过接口循环提交,官方推荐使用批量模式处理海量文档,还能享受五折优惠。
Q4:是否支持中文手写文字、手写签名识别?
A:支持。常规中文手写文稿、手写签名都能自动标记为signature区块。复杂潦草的手写文字识别置信度会同步降低并标注分值,可通过置信度阈值筛选低识别页面,再人工复核。
Q5:输出的Markdown排版能直接导入知识库、笔记工具吗?
A:可以。输出的Markdown完整还原原文标题层级、表格格式、图片占位、公式标记,兼容主流向量知识库、Obsidian、Notion、企业文档管理系统,基本无需二次排版清洗。
Q6:低清晰度老旧扫描档案识别效果如何?
A:内置了图像自动矫正、去噪、对比度增强的预处理模块,可修复倾斜、阴影、淡墨的老旧扫描件。重度模糊、缺墨破损的原稿会输出低置信分数,方便人工筛选修正。
Q7:是否可以自定义抽取票据、合同里的特定业务字段?
A:支持。切换到Document AI模式,传入自定义JSON Schema模板,指定需提取的字段名称和数据类型,模型会自动从文档中定位并结构化输出对应字段,适配财务、法务的自动化流程。
八、总结
总结而言,Mistral OCR 4在精准度、语言覆盖、部署灵活性上打出了一套组合拳。轻量化的专用架构、170种多语种全覆盖、原生像素级结构化区块输出、手写公式LaTeX解析,加上公有云和本地私有化双部署模式,使其在一众文档识别工具中脱颖而出。覆盖场景从企业知识库RAG、科研教育数字化,到金融法务票据自动化、政企档案古籍电子化,几乎一网打尽。定价上也兼顾了中小企业批量成本和大型企业的数据合规需求。综合来看,它确实是一个兼顾识别精度、部署灵活性和业务结构化输出能力的综合型企业级OCR解决方案。