要说过去一年AI圈什么概念最火,非Agent莫属。从自动写代码到整理信息,再到端到端完成任务,整个行业都在见证一场转变:AI从“回答问题”进化到“完成工作”。
不过,当Agent真正被部署到企业生产环境里,一个更棘手的问题就浮出水面了——Agent的最终表现,说到底还是取决于喂养它的数据质量以及数据流转的效率。模型再强,如果拿到的数据是过时的、零散的、彼此对不上的,那也白搭。
现实世界可不会等AI慢慢准备好。金融市场每秒都在波动,直播间里弹幕和商品信息不断翻新,企业的系统每天都会生成海量的日志、交易记录和用户行为数据。对于一个真正要干活的Agent来说,最大的挑战不是生成一个漂亮的答案,而是如何在这样一个不断变化的环境里,持续获取信息、理解变化,然后做出下一步决策。
这也意味着,未来能用的企业级Agent,形态得变一变了:从过去那种“用户提问,AI回答”的对话式交互,转向由真实世界事件持续驱动的Event-driven Agent。
在刚过去的Flink Forward Asia(FFA)2026大会上,阿里云宣布Apache Flink全面进入Agentic Streaming时代,直接回应了这个双重命题:AI正从对话走向事件驱动,而Agent的竞争力,本质上就是背后数据供给质量和流转效率的比拼。底层数据基础设施的升级,已经不是一道选择题,而是前提条件。过去那些支撑业务决策的实时数据流系统,正在变成AI Agent连接现实世界的核心入口。
一、大模型之后,数据基础设施需要变一变
在过去的BI和实时计算时代,数据基础设施的核心任务,是帮企业更快地搞清楚“已经发生了什么”。以Flink为代表的实时计算系统,解决的核心问题就是怎么处理源源不断产生的数据流:订单变化、用户行为、交易记录、系统日志……这些结构化数据被实时处理后,变成业务决策需要的信息。
这个阶段,数据的主要使用者是人——数据开发工程师写任务,分析师看报表,业务人员根据结果拍板。
但AI进入生产环境后,情况不一样了。在阿里云开源大数据平台负责人王峰看来,Flink向Agentic Streaming演进,本质上是流计算技术自身的优势,和AI时代的需求刚好碰上了。过去流计算解决的是数据“实时流动”的问题,而Agent时代需要解决的是:怎么让智能系统“持续感知”现实世界。
变化首先来自数据本身。以前企业的数据主要是结构性数据,围着数据库和业务系统转;但AI时代,大模型和Agent要处理的数据范围迅速扩大——文本、图片、音频、视频、传感器信号,还有来自各种业务系统的实时事件,都成了AI理解世界的一部分。数据规模不是简单地在变大,而是从单一形态走向全模态,从静态信息变成了动态事件。
更重要的变化,是数据的使用者变了。
过去数据最终服务的是人:工程师写SQL,分析师做分析,运营人员制定规则。但进入Agent时代,数据开始直接喂给AI系统。一个真正干活的Agent,不会傻等用户输入后生成答案,它需要持续拿到新鲜、准确、完整的数据,并根据环境变化不断调整自己的判断。
这也是为什么Agent的能力上限,越来越依赖背后的数据质量和处理效率。大模型提供的是理解和推理能力,但如果Agent拿不到及时、正确的上下文,就很难真正参与复杂的业务。无论是智能运维、金融风控,还是内容分析,本质上都要求AI能接住现实世界不断产生的事件,并基于这些变化做出行动。所以,AI时代数据基础设施的核心命题正在变化:过去是“怎么把数据及时送到人手里”,现在则变成了“怎么让数据持续驱动智能”。
这,正是Flink进入Agentic Streaming时代背后的核心逻辑。
二、从实时计算到Agent,Flink正在重做AI的“基础设施层”
当下行业里讨论的Agent,大多集中在编程助手、个人效率工具这类场景。本质上还是“人提出需求,AI完成任务”的对话式交互,触发源永远是人的指令。但在更广阔的企业生产场景里,绝大多数触发源,其实是系统自发产生、永不停歇的事件。
在王峰看来,未来To B领域会走出一条独立的赛道——事件驱动型Agent。它不需要人发起对话,而是由海量持续产生的业务事件触发,7×24小时自主运行、异步响应、自主决策,这是真正能嵌入生产流程的AI形态。
这类Agent已经在多个场景里展现出价值。比如智能运维,企业IT系统每秒产生海量日志、指标和异常事件,过去靠人工运维和固定规则排查故障效率很低。现在,事件驱动Agent可以实时收集全量运行数据,结合大模型诊断性能瓶颈,自动调整资源并发、完成故障自愈。阿里云内部已经实现了“用Flink Agent运维Flink”,数千个计算任务的扩缩容、异常修复,全过程无需人工介入。
再比如金融风控,固定规则依然承担着前置过滤的职能,保证低延迟;而大模型则负责对可疑事件做深度研判,识别更隐蔽的作弊与风险。这种规则与模型混合的模式,同时兼顾了效率与精度。
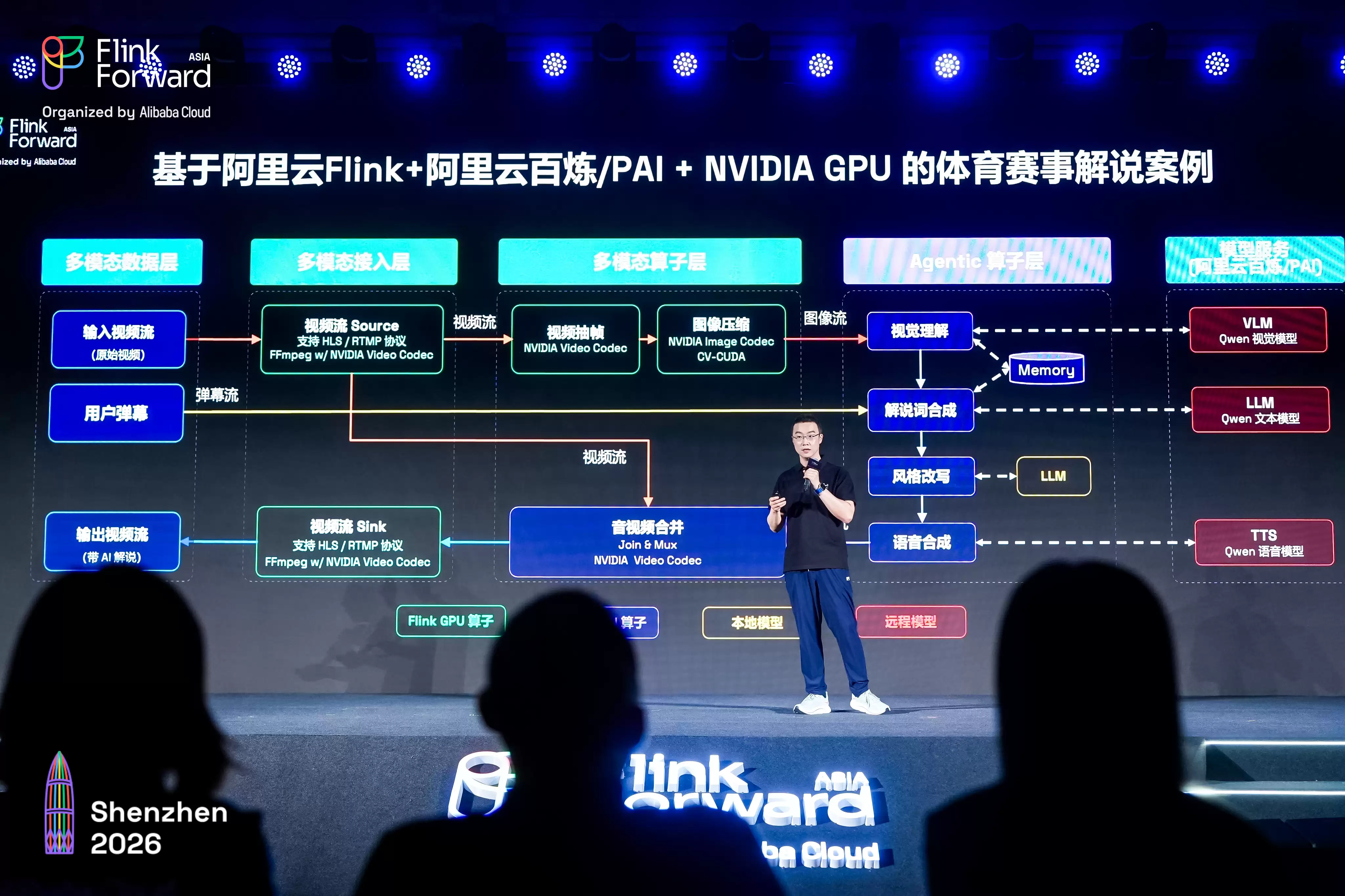
还有直播场景,视频流、弹幕流、用户行为流多路数据同时产生。Flink可以在同一条流水线里完成抽帧理解、解说词生成、弹幕意图识别,实时调整解说风格与输出形式。
Flink能支撑这类场景,核心在于把流计算沉淀了十几年的原生能力,直接变成了Agent运行的基础底座。
在王峰看来,这正是Flink和主流多模态计算引擎的差异所在:很多引擎擅长处理离线批量的多模态数据,但Flink作为纯流式引擎,既能承接存量批量数据,也能对接无限流淌的实时数据流,覆盖的场景边界更广。它的流水线架构实现了CPU与GPU全链路流水运转,数据不落盘、网络直传,让GPU资源持续满负荷运行。
另一方面,是原生状态管理与多流对齐能力。这部分能力其实是流计算的原生积累——BI时代沉淀的分布式状态管理系统,可以直接复用为Agent的短期记忆载体;再对接外部向量数据库来承载长期知识,完全不用从零搭建一套上下文体系。而水平线、窗口机制,天然就能解决多模态数据速率不一致、到达时间有先后的问题,把多路数据按时间轴精准对齐,避免AI拿到一堆碎片化的“拼图”。
计算能力之外,Agent要持续运行,还需要一个稳固的存储底座。这也是Flink生态正在补齐的关键一环——由Flink社区孵化的Apache Paimon与Apache Fluss共同构成的Agentic Lake,实现了湖流一体的完整架构。Paimon作为下一代流式数据湖,负责全模态数据的沉淀与统一管理;Fluss作为专门的流存储系统,负责实时数据流转与Agent上下文供给。两者双向自动互通,一个管“数据沉淀”,一个管“实时输送”,让Agent永远有新鲜、完整的上下文可以用,形成了从存储到计算的完整闭环。
事实上,To B生产级Agent对可靠性的要求远高于消费级产品:个人Agent出问题重启就行,但承载业务的Agent必须支持7×24小时稳定运行、具备故障自愈能力。这正是Flink多年企业级场景沉淀下来的核心长板。
说到底,Agent从Demo走向生产,瓶颈就在于能不能长时间、稳定、可靠地跑在业务里。Flink想做的,就是通过孵化Flink Agents项目,把自己沉淀多年的可靠性、一致性与容错能力,变成事件驱动Agent的通用运行底座——也就是Streaming Agent-OS。
三、Agent时代,基础设施竞争才刚刚开始
回看技术产业的竞争脉络,云计算时代,企业比拼的是计算与存储的资源效率;大模型爆发初期,行业关注的是参数规模与榜单成绩;而当AI开始真正走进业务、走向落地,竞争的重心正在从“大脑有多聪明”,转向“能不能持续感知真实世界”。
Flink提出Agentic Streaming,本质上是给实时计算重新下了个定义。

它不再只是大数据团队的专用工具,而是AI时代的通用基础软件:向上,通过全模态数据流处理为大模型输送高质量的实时燃料;向内,通过Streaming Agent-OS支撑事件驱动Agent的稳定运行;向下,通过Agentic Lake的湖流一体架构,筑牢一个永远在线的数据底座。
王峰谈到,目前Flink开源社区的项目管理委员会已经在推进3.0版本的规划讨论,面向AI与全模态的升级是全球社区的共识,国内外多家头部科技公司都已参与共建。从计算引擎到存储生态,整个技术栈都在围绕Agent场景持续演进。
如果说大模型是AI的“大脑”,负责思考与决策,那么一套完整的实时数据体系就是AI的“神经系统”——它持续感知外界变化,把分散的信号整理成有序的信息,精准传递给大脑,再把决策同步到执行端。Flink正在做的,就是把这套神经系统的基础设施做扎实。
大模型的能力迭代还在继续,但AI应用的竞争,早已从单点的模型能力,扩展到了全链路的系统能力。未来能真正规模化落地在千行百业的Agent,靠的不只是更聪明的模型,更是足够稳定、高效、实时的数据底座。
从这个角度看,AI与Agent的基础设施竞争,其实才刚刚拉开序幕。