先给出几个核心结论。
就在昨天,DeepSeek 为 V4 模型带来了一个重要的新成果,这次聚焦于推理速度的优化。他们推出了一套名为DSpark的投机解码框架,同时开源了配套的训练框架DeepSpec。该论文由 DeepSeek 与北京大学共同完成。
近期使用 V4 的用户应该能明显感受到,生成文字的速度变快了,尤其是在并发请求不多的时候。这正是 DSpark 带来的改善。目前它已经部署在 V4 的 Flash 和 Pro 两个版本的线上流量中,取代了上一代的 MTP-1 方案。
需要特别说明:DSpark 并非一个全新架构的模型,而是在 V4 基础上增加了一个推测性解码模块。这次更新的重点在于工程落地,而非模型能力的迭代升级。
DeepSeek 在推理效率方面一直持续投入。V2 的 MLA 压缩了 KV cache,V3 引入了 MTP(多 token 预测),V3.2 采用了稀疏注意力。DSpark 是这条技术路线上最新的进展,也是首次直接应用于主力产品中。

报告链接:https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
这项新成果从一个不同的角度来审视推理速度问题:
投机解码领域近两年一直在围绕“草稿生成的数量与准确性”进行竞争,而 DSpark 则将矛头指向了另一个被忽视的环节:验证过程。
先讲清楚:投机解码到底在做什么
大模型生成文本是逐字进行的:每生成一个 token,都需要将前面的全部内容重新计算一遍。输出越长,速度越慢,GPU 的利用率也越低。
投机解码(Speculative Decoding)是解决这一问题的标准思路:使用一个小而快的“草稿模型”一次性预测出后续若干个 token,然后由完整的“目标模型”并行验证这一批 token,接受其中正确的前缀,遇到第一个错误则将后面的全部丢弃。
打个比方,就像秘书先草拟一段话,老板快速审阅一遍,正确的留下,错误的地方自己修改。关键在于,验证是并行进行的,并且能在数学上保证结果与目标模型逐字生成完全一致。因此它是一种无损加速方式,质量不打折扣。
草稿模型如何构建是性能的关键。过去主要有两条技术路线:
自回归草稿(代表模型 Eagle3):逐个 token 向后预测,每个 token 都基于前一个。准确率较高,但起草时间随长度线性增长,只能写短序列,网络层数也较浅。
并行草稿(代表模型 DFlash):一次前向计算就能预测出整串 token,时间几乎与长度无关,可以写得很长。缺点是各位置独立预测,彼此不知道对方的结果,越往后越容易出现前后不一致。
并行草稿的这个缺点有一个形象的例子:当上下文同时支持“of course”和“no problem”两种续写时,独立预测可能会拼出“of problem”或“no course”。论文中将其称为 multi-modal collision,结果是越靠后的 token 越容易被拒绝,接受率快速下降。
DSpark 所做的两项工作,正好一项针对草稿生成,一项针对验证过程。
创新一:半自回归,为并行草稿补上“顺序”
前面说过,并行方法速度快但尾部不连贯,自回归方法连贯但速度慢,过去只能二选一。而 DSpark 试图兼顾两者。
具体做法是:繁重的计算仍由并行骨干网络一次性完成,然后在其后接一个轻量的串行模块,专门补充“前一个 token”的信息,从而弥补连贯性。
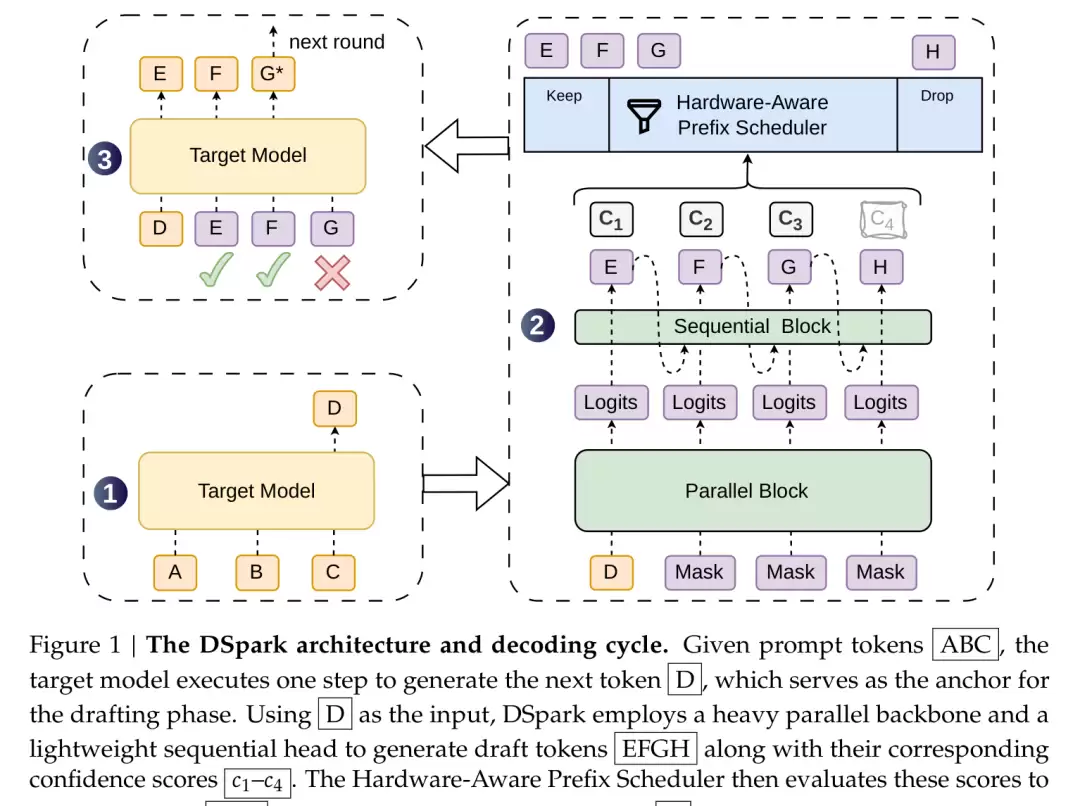
这个串行模块默认采用 Markov head:只参考紧邻的前一个 token,通过低秩分解(r=256)将转移关系压缩到极小规模,几乎不增加计算量。回到刚才的例子:一旦第一个位置确定为“of”,它就会在下一个位置提高“course”的概率、压低“problem”,从而使前后衔接起来。
论文也尝试了记忆更长的 RNN head,效果略好,但实现复杂且部署成本较高,最终默认仍采用 Markov head。
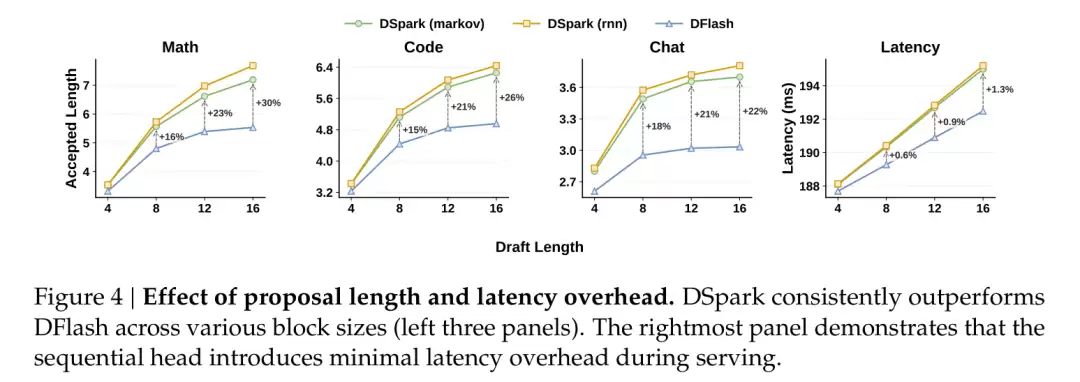
代价非常小。后续数据显示,这个串行模块给整轮延迟仅增加 0.2%–1.3%。
一个反直觉的发现:并行比自回归更准
按直觉来说,逐字向后生成的自回归方法应该比各自独立预测的并行方法更连贯、接受率更高。但论文的实测结果恰恰相反:并行草稿反而更准确。
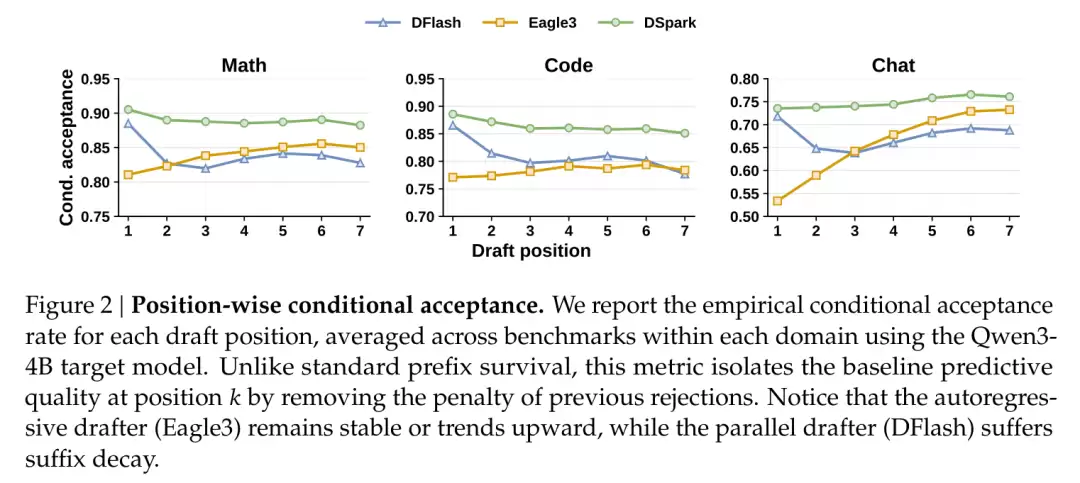
原因有两方面。
第一个 token,并行天然占优。并行草稿的起草时间与长度无关,因此网络可以做得更深;自回归为了控制延迟只能做浅。结果在第一个位置上,DFlash 的接受率高于 Eagle3(数学 0.88 对 0.81,对话 0.72 对 0.53)。而投机解码是前缀验证,一旦第一个 token 被拒,整串都会作废,因此起始位置的权重最高。
越往后,独立预测的短板才会显现。位置 2 到 7,DFlash 持续衰减(代码从 0.87 降到 0.78,对话从 0.72 降到 0.63);自回归则能保持甚至回升(对话从 0.53 升到 0.74)。
DSpark 正是要汲取两者的长处:用深并行骨干拿下高起点(数学第一位达到 0.93),再用轻量串行模块弥补尾部的衰减。这套组合还非常节省参数。
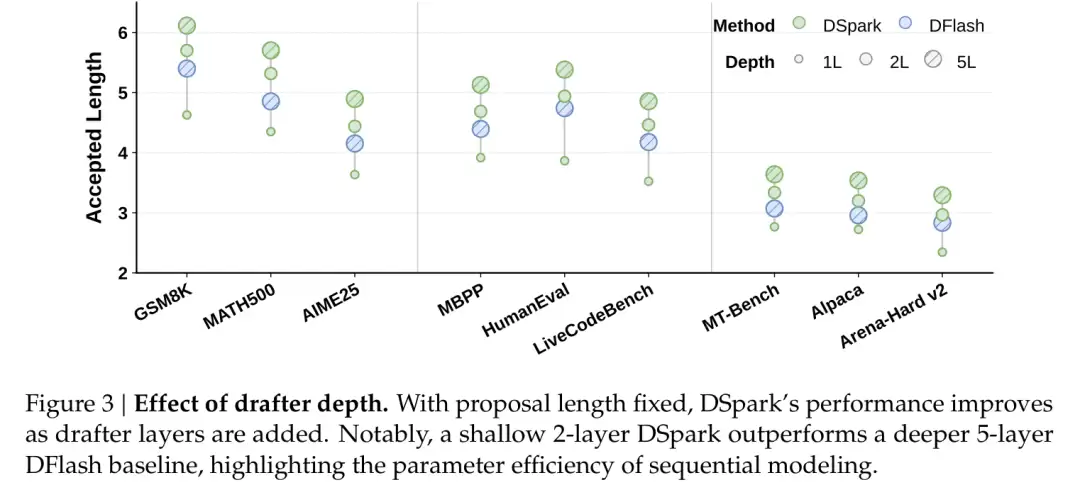
草稿写得更长时,优势会更加明显。
创新二:让验证也能动态调度
前面都在改进草稿生成,论文的另一个核心创新在于验证环节。
草稿可以写得很长,但这是否意味着需要整串都进行验证?答案是否定的。
在高并发的线上环境中,验证并不免费。多验证一个大概率会被拒绝的 token,就会占用目标模型这一批的算力,而这块算力本可以用来服务其他正在等待的请求。负载低时影响不大,但负载一高就会造成明显浪费。
DSpark 的第一步,是为每个草稿位置配备一个置信度头(Confidence Head),用于预测该 token 通过验证的概率。
仅仅判断是否应该验证尾部 token,这一步就已经能带来显著效果。
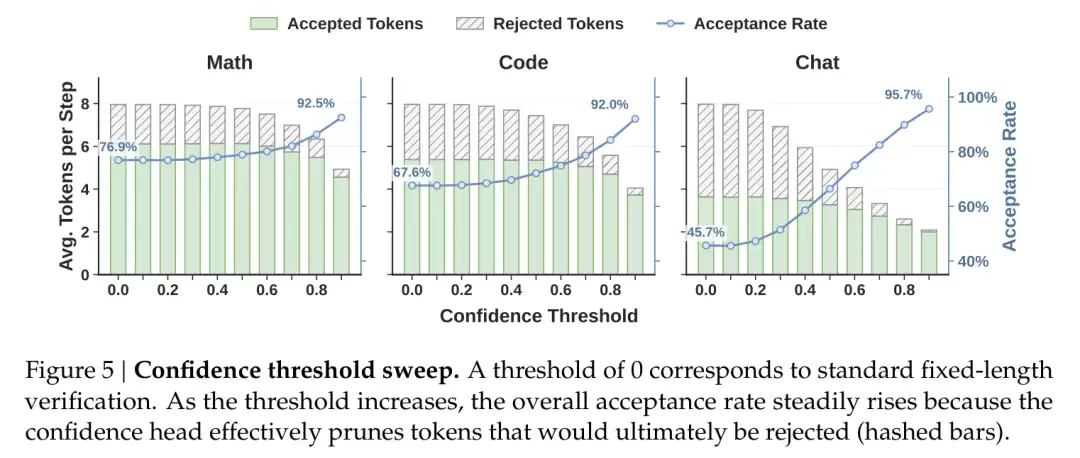
不过,要让置信度真正用于调度,还需要一步。
调度需要的不是“哪个 token 更有把握”的排序,而是存活概率的绝对值:数值准确,才能计算出应该验证多长。神经网络给出的置信度通常偏乐观,因此论文又加入了一道称为 STS 的事后校准,将预测概率拉回到真实接受率,同时不改变原有的排序。
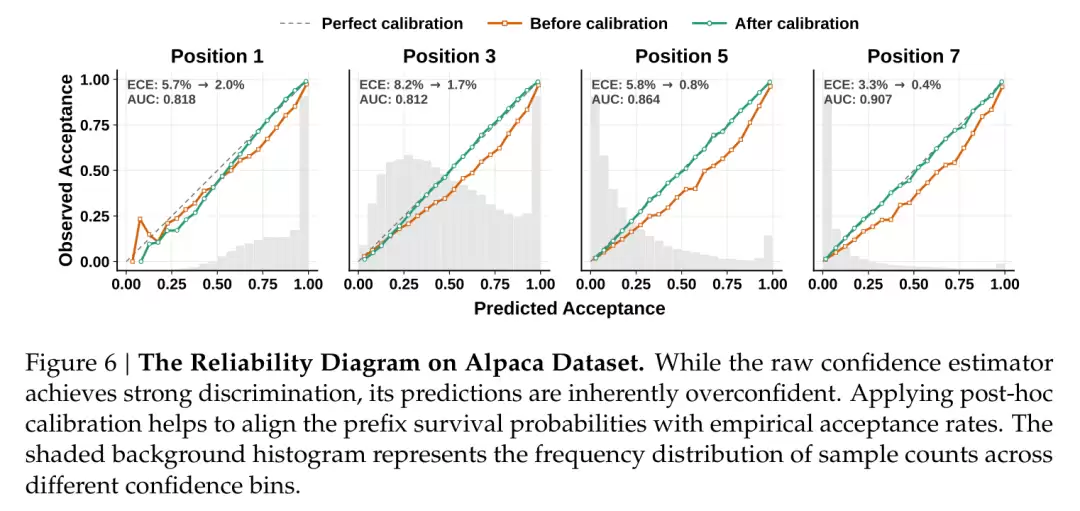
有了可靠的存活概率,最后一步才是核心:一个硬件感知调度器(Hardware-Aware Prefix Scheduler),根据当前负载动态决定每个请求需要验证多长。

在真实环境里,到底快了多少
先看离线评测。在 Qwen3 的 4B/8B/14B 以及 Gemma4-12B 四个目标模型上,DSpark 全面超越了自回归的 Eagle3 和并行的 DFlash。
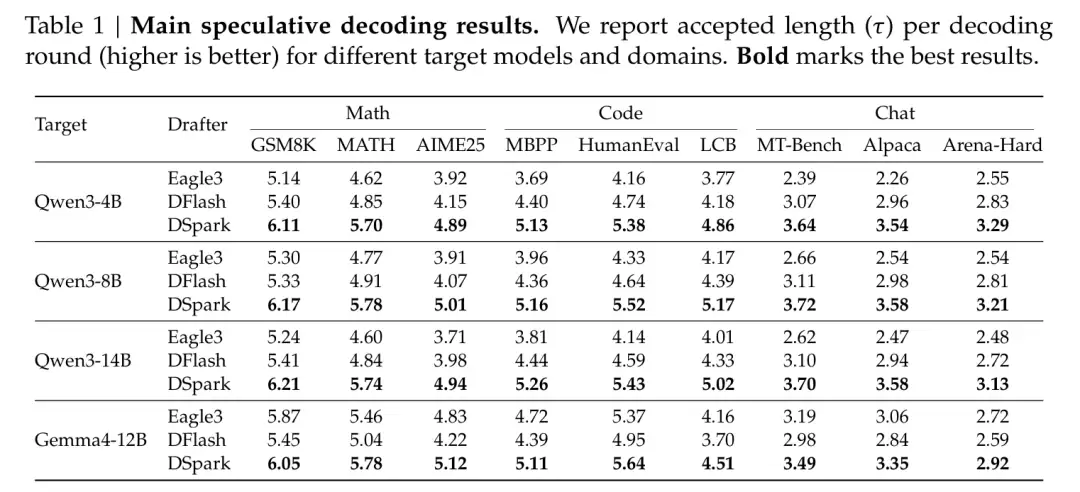
具体来说,平均接受长度相比 Eagle3 提升了 26.7%–30.9%,相比更强的 DFlash 也提升了 16.3%–18.4%。
数据中还呈现出一条规律:结构化任务(数学、代码)的接受长度天然高于开放对话。以 Qwen3-4B 为例,数学三项平均 5.57、代码 5.12,对话只有 3.49。这正好解释了固定长度验证为什么是浪费:对话中那些大概率被拒绝的尾部 token,本就不该花费算力去验证。这也是上一节动态调度的意义所在。
论文中更重要的部分,是真实的生产环境数据。
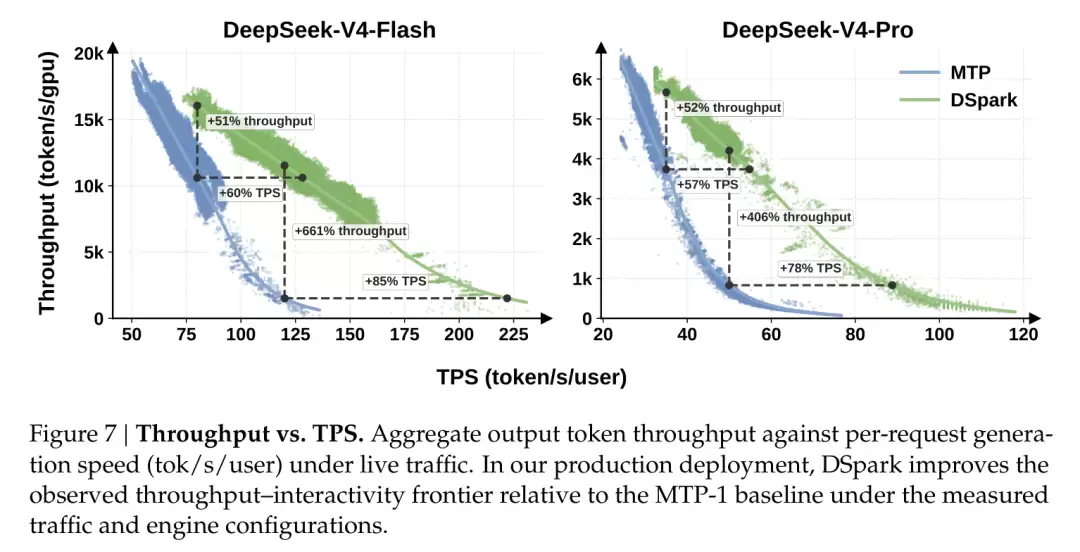
结论是:在吞吐量持平的前提下,V4-Flash 上每个用户的生成速度提升了 60%–85%,V4-Pro 上提升了 57%–78%。
另一个场景更为关键。当对单用户速度要求非常严格时(例如 120 tok/s/user),上一代 MTP-1 已接近极限、只能服务很少的并发,而 DSpark 仍能维持。此时两者的相对吞吐差距可达 +661%。论文也强调,这个数字更多是说明 DSpark 将可用的交互档位向外扩展了,而非真的有六倍提升。
它是如何做到的?请看负载自适应这张图。
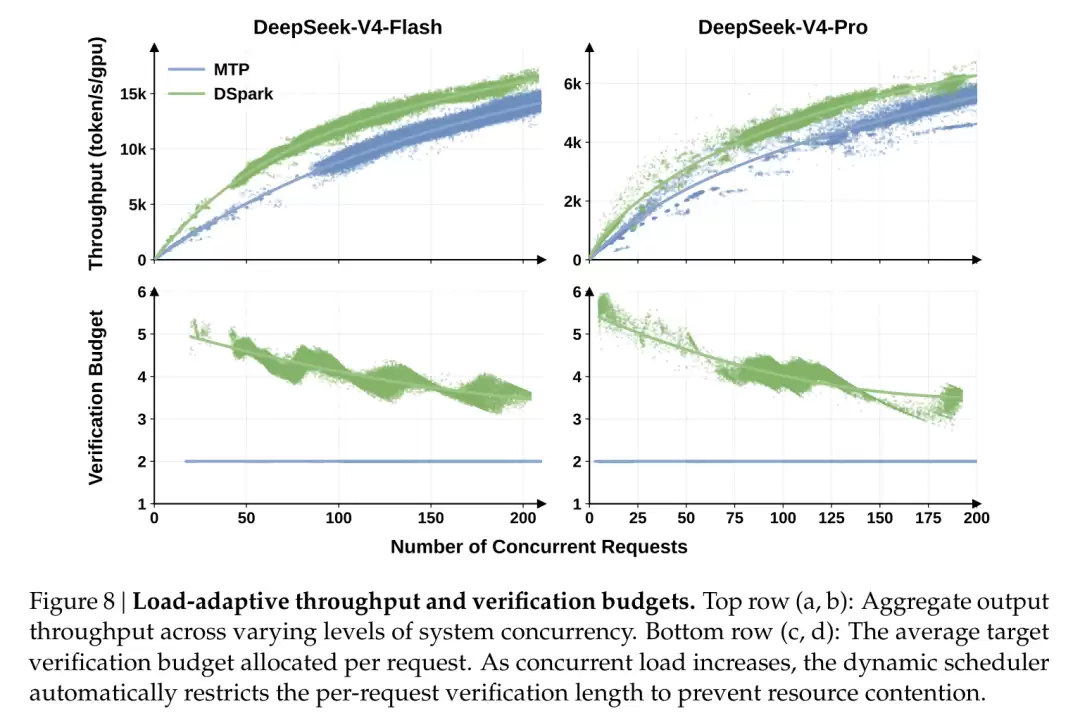
简单来说,就是空闲时多验证、多接受,繁忙时收紧,把算力优先留给真正在排队的请求。
写在最后
论文也提到了不足之处:DSpark 再省,起草的成本仍然无法避免。并行骨干生成第一块草稿是固定开销,遇到本身难度高、接受率低的复杂请求时,这部分前期投入可能难以收回。团队给出的后续方向,是让草稿模型也能根据难度提前停止。
总体来看,这是 DeepSeek 在推理加速领域的又一次推进,并且首次直接落地到 V4 主力产品中。