为一组照片摆了十几个pose、拍了几百张废片,回到家想挑两张让AI修一修,结果AI弹出一句:请精准描述你的需求。
审美这件事本来就很个人化,每次都是凭着自己感觉在P图,要描述清楚到底该怎么P,相当不容易。说给人都难解释清,何况说给AI。
面对AI,很多人只想说一句:“我要美。”结果就是修了十张,没几张能用,还有几张根本不像自己。
看着那些AI生成的P图,这让人不禁想问:到底是用户不会用AI修图,还是AI根本没想过要懂用户?
这两年越来越觉得,当下的AI工具就像越买越贵的智能健身器材,功能堆得越来越满,可大多数人扛回家,只用来晾衣服。
工具越强,人反而越累。好像大家都默许了一条潜规则:AI越厉害,人就得越拼命去追、去学、去写小作文讨好它。
前几天APPSO来到美图影像节,他们一次发了八款产品,号称是“AI影像团队”。这个节奏很AI了,但影像设计这个领域的AI产品实在太卷,美图这次有什么不一样?

发现其中有几款,恰好压在天天犯怵的地方:人像修图、口播、做图。趁着假期一款款真上手用了下来。
结果有点出乎意料。它们和其他AI产品比起来有点“非主流”——别的产品让人去适应AI,美图是让AI来适应人;其他人只丢一个工具,美图会把能直接用的成果交到你手上。
如美图创始人吴欣鸿所说:从“用户学工具”,到“用户直接获得结果”。从事实来看,这支AI影像团队交出的答卷,确实不太一样。
下面分享真实的使用体验,评判标准也很直接:东西能不能一次出对、比从前省了多少功夫、到底适合谁,给出的东西到底有多大用处。
P图也有一套Skill
先从最戳痛点的那款产品Picchi说起。通用大模型逼用户“精准描述需求”,说到底还是人在迁就AI;Picchi反过来——让AI来迁就你。
怎么验证它是不是真的做到了?挑了四个层层递进的场景去试。
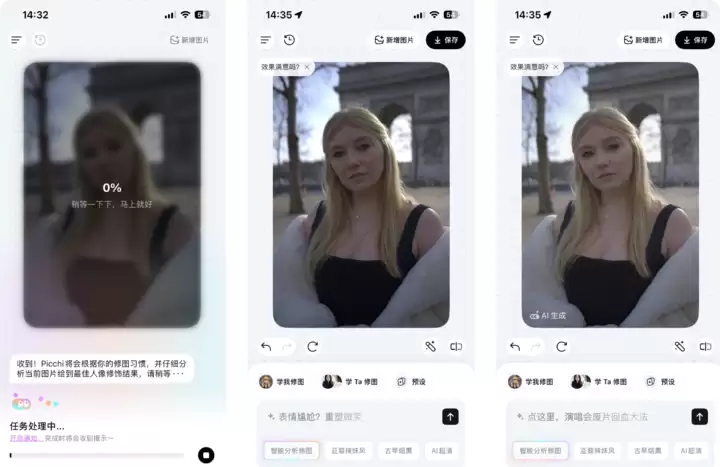
以往用AI修图,最痛苦的就是每次都要重新打长串提示词,部分AI指令遵循能力还不够强,经常修改了表情,改到根本不像本人。
打开Picchi应用,首页找到“学我修图”,上传3-10组前后对比图,Picchi就会创建一个专属自己的修图模型,它能自动记忆修图风格。
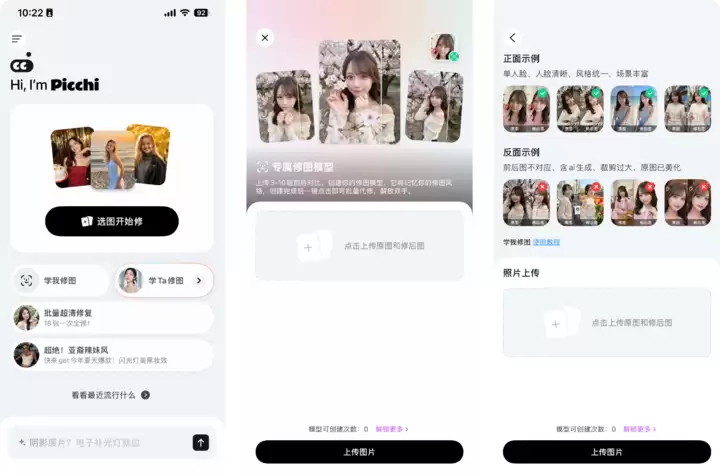
实测中,尝试把一些平时PS的照片丢给它学偏好,再上传新原图,它能从原图和修后图中找到完整的修图细节,直接Get到修图偏好。
值得注意的是,“学我修图”是Picchi采用顶级显卡、前沿算法以及高质量渲染来实现的,所以对上传照片的要求非常严格。
照片必须足够清晰、足够大,人脸区域也必须足够大,此外也只能上传同一人脸的照片——帮别人修的图不能和自己的放在一起。
在“像不像自己修的”这一项上,如果满分是100分,愿意打90分。因为测试时上传的原图和对比图,其实就是简单地修了一些光以及皮肤。在使用“学我修图”时,Picchi很好地抓住了这些习惯。
硬要挑一处不足的话,就是创建次数确实太有限了,处理时间也有点久。
但这种“记住你是谁”的能力,相当于直接把过去繁琐的P图流程打包成了一套Skill,在批量精修时能展现出更大的优势。

例如,可以直接把出门旅游拍的原图一股脑批量丢进去,Picchi就会根据之前总结的自定义图片模型,依照想要的风格,把照片统一编辑好。
如果是不懂HSL、不懂骨相蒙版的新手,平时不知道怎么手动修图,Picchi无法学习修图模式,它提供了一种“借用审美”的解法。
可以直接选用官方合作的“百万改妆师”或者“骨相修图大拿”等合伙人模型,在Picchi首页找到学Ta修图,里面囊括了Hana、哦基儿、Iris、清颜好困啊等模型,还有热门预设和灵感玩法。
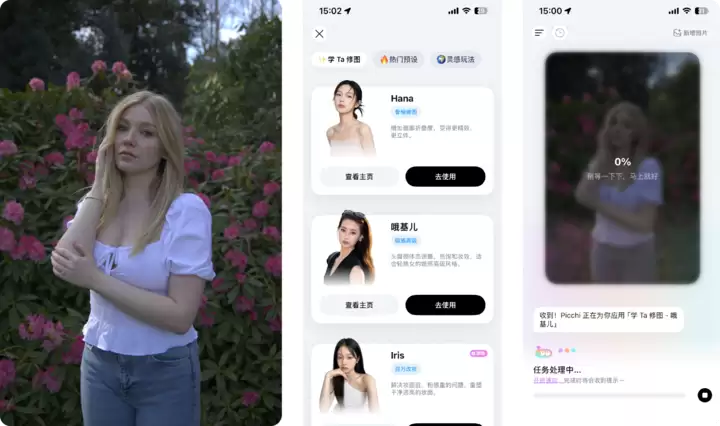
从网上找了一些相机直拍的原图,放到Picchi中使用“学Ta修图”来修改。依次用了哦基儿、Iris和Hana,最终呈现的高光面部提亮和骨相微调,真的很像专业大拿坐在身边亲自操刀的手笔。
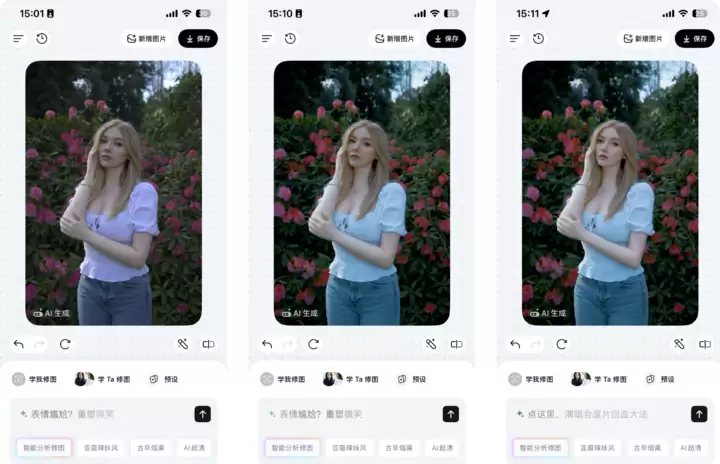
在“学Ta修图”旁边,Picchi还提供了一系列预设,包含了当下的热门照片风格,像是Pocket 3、理光负片、Xs Max、徕卡 DL7、鲜花增色、CCD等不同相机和场景。
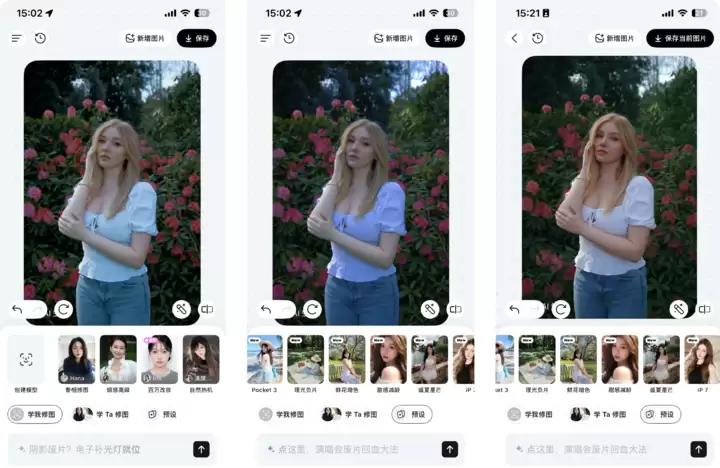
而在“学我修图”和“学Ta修图”之外,那些常挂在嘴边、说不清道不明的“氛围感”,Picchi现在也能用自然语言准确拆解。
说出“修出冬日萧肃氛围感”时,它能自动调整面部暖调光和发丝微光,同组提示词直接出片,不需要像以前那样频繁“抽卡”碰运气。
Picchi的价值核心在于,背后虽然是一支由调色、妆造、形象、打光、体态各司其职的AI修图师团队,但用户不必知道复杂的底层参数,只需要看到“真的像我、真的好看”。
而AI修图的终点除了要有更强的参数,更应该是懂你的那个人。专注人像这一件刚需,让Picchi反而做到了通用大模型做不到的“真的像你”。
给每首歌都能拍个大片的MVLAND
如果说Picchi搞定的是静态人像的动态审美,另一款重磅新品MVLAND则把触角伸向了更注重情绪共鸣的音乐视频领域。
吴欣鸿在现场提到一个数据:在这个短视频时代,有超过80%的年轻人是通过刷视频发现一首新歌的。然而现实是,市面上绝大多数的歌,根本没有MV。
少则几万、多则几十万的成本,两三个月的制作周期,让MV成了少数头部的特权。这叫视频时代的“音乐遗憾”。做MVLAND,就是想把这个遗憾补上。
在实测中,这也是最让人感到惊艳的一款新品。以前的通用AI视频工具往往“读不懂音乐”,最多只能傻傻地对个鼓点。但MVLAND的底层做到了对音乐结构、节拍、情感的深度理解。
它完美解构了一支专业MV必备的5大要素,拥有理解音乐、人物演绎、视觉风格、情绪编排、歌词字幕等功能,并行业首创了“画布剪辑台”。
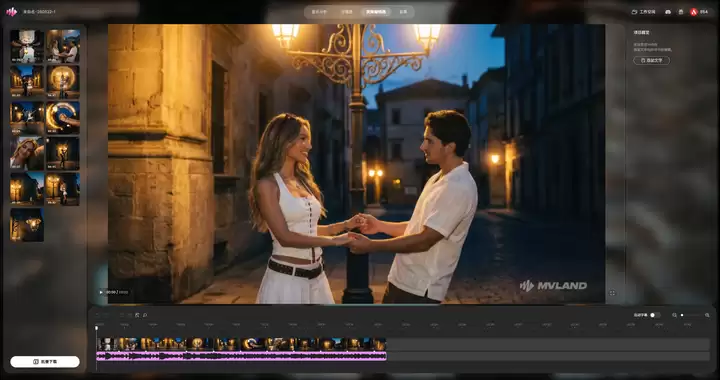
把一首歌扔进去,音乐分析Agent会自动拆解节拍、段落与情绪并生成画面。
根据实际工作流对比,同样做一支精致的MV,通用视频工具要3小时,MVLAND只要10分钟,且画面情绪与音乐节拍严丝合缝。

再派出一支专业团队,直接交付
如果说Picchi解决的是“懂不懂你”,MVLAND解决的是情绪和画面的对齐,那么这次美图影像节上带来的另外几款产品——美图设计室、开拍和RoboNeo,则将这种“直接交付成果”的底气带到了更硬核、更需要全流程托管的商业生产力场景。

▲美图生产力场景多款AI影像产品
它们的场景覆盖范围相当广,涵盖了口播、电商、MV和短剧,但落点出奇一致——最终交付的,必须是一件能直接拿去用的成品。
连学都不用学,把口播交给“开拍”
在口播领域,美图推出了由导演、营销、拍摄、剪辑Agent组成的口播团队——“开拍”。这次更新,它实现了从选题到拍剪,再到成片和数据复盘的全托管。
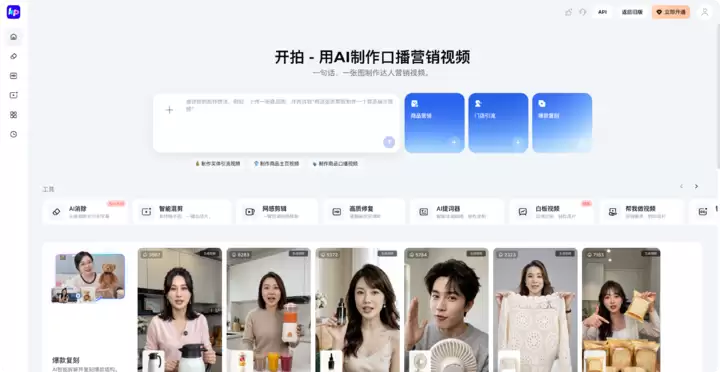
这项全新功能叫“开拍AI助手”。过去拍一条口播,要先想好文案、架起设备面对镜头,最后还要调整剪辑轨道。
开拍AI助手的出现,让这种传统工作流直接升级,口播创作变成了真正的“不用你想、不用你拍、不用你剪”。
尝试扔进去一段粗糙的口播素材并选定网感模板,它会自动剪掉气口、加字幕、配BGM并直出成片。
这种全托管让很多个体户和创作者松了口气。根据开拍一些真实用户的体验,一位实体店老板娘提到,以前是“拍摄5分钟、剪辑5小时”,现在用开拍十分钟搞定。快速产出的短视频获客,让店铺业绩翻了2.5倍。

▲ 开拍生成的自动字幕和花字视频
开拍的好用,在于它让用户连学都不用学,它懂用户的生意,直接帮用户做视频。只需要把自己要传递的内容表达清楚,它会把成片这个“结果”直接交付。
一张商品图,变成一套卖货素材
如果说开拍解决的是个人表达,美图设计室解决的则是商业生存。
它通过市场洞察、内容策划、视觉创作、数据分析等Agent以及几十个专业技能,能够一次交付全套商业物料。
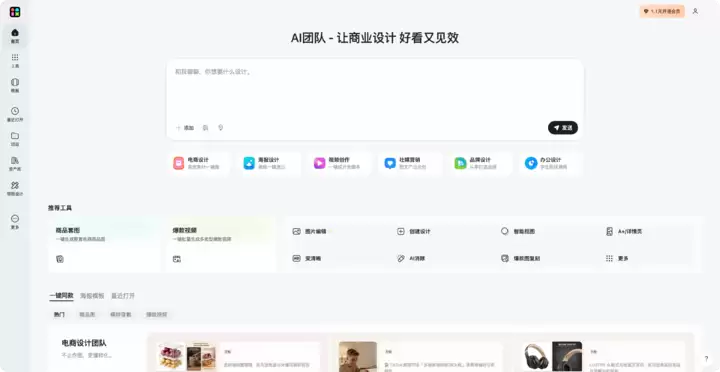
实测中,上传一张商品实拍图,输入商品卖点,它就能生成市场分析、场景图、卖点文案以及多尺寸电商海报的整套物料。
这一整套物料能直接帮助用户进一步完善营销方案,包括判断、选图、写卖点……美图设计室几乎是把“能不能卖货”的压力也扛了下来。
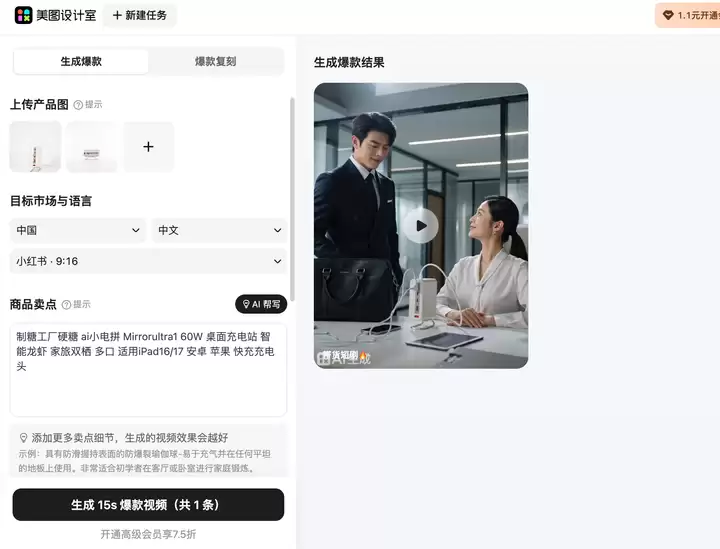
▲ 使用美图设计室内的爆款视频,给制糖工厂的小电拼生成了一段15秒的小视频。
规模化生产短剧的RoboNeo
至于面向短剧规模化生产的RoboNeo,直接模拟了一个真实的剧组,配置了编剧、选角、导演、美术、执行、运营等Agent。它主打四大核心能力:懂短剧、镜头可控、资产沉淀和数据闭环。
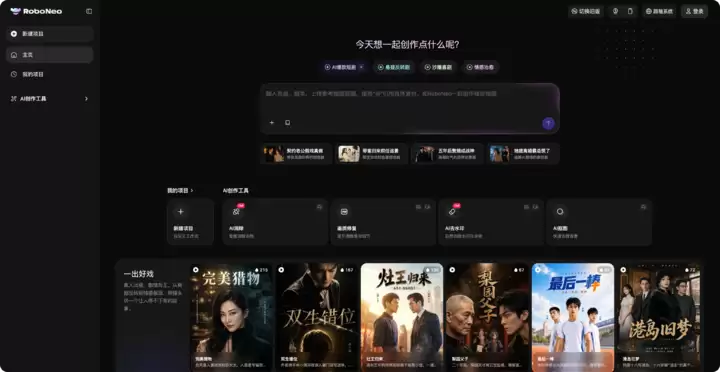
在演示中可以看到,剧本、角色、分镜全在画布上可控可改,角色和场景可以跨项目复用,发布后数据还能反哺下一集。
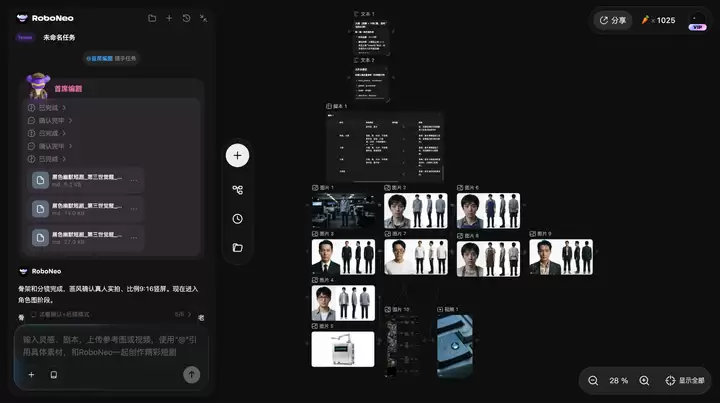
这也是RoboNeo出力的方向,也是短剧规模化最难的一环——一致性与可持续。
这几款产品场景各异,但它们合在一起才真正撑起了“你的AI影像团队已就位”这句话;团队的意义,就是替你把结果交付到底。
人、灵感和定制需求也在这套系统里
而为了让这支团队运转得更稳、更远,美图还布下了三块重要拼图。

首先是作为人力底座的站酷(ZCOOL)。当人人都能产图,大家对AI生成内容的“信任”反而成了稀缺品。
运营二十年的站酷,其价值正是“相信一份作品背后那个鲜活的人”。这也为美图的AI提供着高视觉标准、AI资产库和效果工作流。
而即将在6月30日上线的Artflo则走的是灵感创作路线。它保留你的判断,把概念影像那套又长又绕的创作流程压短,让过去一条动辄几十万的概念视频,用AI几百块就能做出来。
最后是8月5日推出正式版的MeituHub,它接住了标准化产品够不着的那20%规模化需求。用户只需要用大白话把需求说清楚,专家Agent就会替你搭出一条AI影像生产线,既能生成网页应用,也能通过API嵌入企业原有的流程中。

设计师、灵感型创作者、要规模化生产的企业,三类人需求差得很远。但美图想干的是同一件事:让AI来适应你,再对交付出去的结果负责。
AI影像,开始从生成走向交付
把8款产品挨个体验下来,感受是:它们合在一起,确实拼出了一套“AI影像团队”。
虽然这个影像团队还有很多空间——Picchi的专属模型训练时长,Artflo、RoboNeo短剧新版、MeituHub正式版也还得等正式上线才见真章。但有件事越来越确定:美图这次是真正多走了一步,把焦点落在了“给你结果”这件事上。
这一步,恰恰是行业最容易跳过的。大家都忙着比“生成式AI”谁生得更快、更炫,可用户要的是一次更好的商业判断,一条能直接发的视频,一支情绪真的对得上的MV。
美图把这件事拎出来,做成了“交付式AI”——AI负责生成,也要把最终好不好用这件事扛到最后。
往回看,这也正是美图这两年种种变化的落点:从App到AI Agent,工具复杂度的债由AI扛,不再甩给用户;从订阅到算力点消费,你买的是“成果”,费用跟着算力点走,功能权限退到后面;从成熟组织到AI创新组织,就是要适配新时代的需求……
最终,把AI产品的及格线,从“生成”抬到了“交付”。
▲ 美图主要产品
所以回到最初那个问题:美图“让AI适应人、对结果负责”,到底走到哪一步了?
答案是,它走到了把成果交付当成底线这一步。它没有把AI说成万能药,只一件件啃小众刚需。它始终站在用户和创作者那一边:靠效果驱动,少谈数据驱动。

当整个行业忙着证明“AI有多强”,美图在证明的是另一件事:AI到底能不能对你有用、对你的结果负责。前者制造焦虑。后者,才在终结焦虑。
发布会上,美图公司首席产品官陈剑毅说了句挺朴素的话:
做比想容易太多了,很容易让人产生一种我在创造价值的幻觉。但交付给用户好的成果,帮用户赚到钱,才是真正的价值。
AI产品到底成不成,最后都得落回这句话上:不看它生成了多少,看你有没有真的用上,有没有真的拿到那个结果。