当前大语言模型正朝着千亿参数规模与百万级上下文窗口快速演进,推理效率已成为制约落地的核心挑战。更庞大的模型体量、更长的序列长度、更复杂的MoE稀疏架构虽带来了能力质的飞跃,却也大幅加剧了算力消耗、显存占用与通信压力。
腾讯混元Hy3 preview作为新一代旗舰大模型,采用GQA + MoE混合架构,原生支持256K超长上下文,面向Agent智能体、智能编码等复杂应用场景。其主力部署卡为NVIDIA Hopper系列,相较于业界主流的Blackwell架构,Hopper卡在算力、显存及超节点互联能力上均处于劣势。这意味着,必须在资源受限的硬件条件下,将长上下文推理性能优化至极致,方能满足SLO约束并实现最优成本。本文旨在分享混元AI Infra推理团队如何从算子层面到系统层面,对Hy3 preview推理全栈实施深度优化。以下将从算子优化与融合、并行策略、多级缓存、MTP与异步调度优化、量化与稀疏五大技术维度,逐一剖析各项方案的设计理念、核心算法及实测收益。
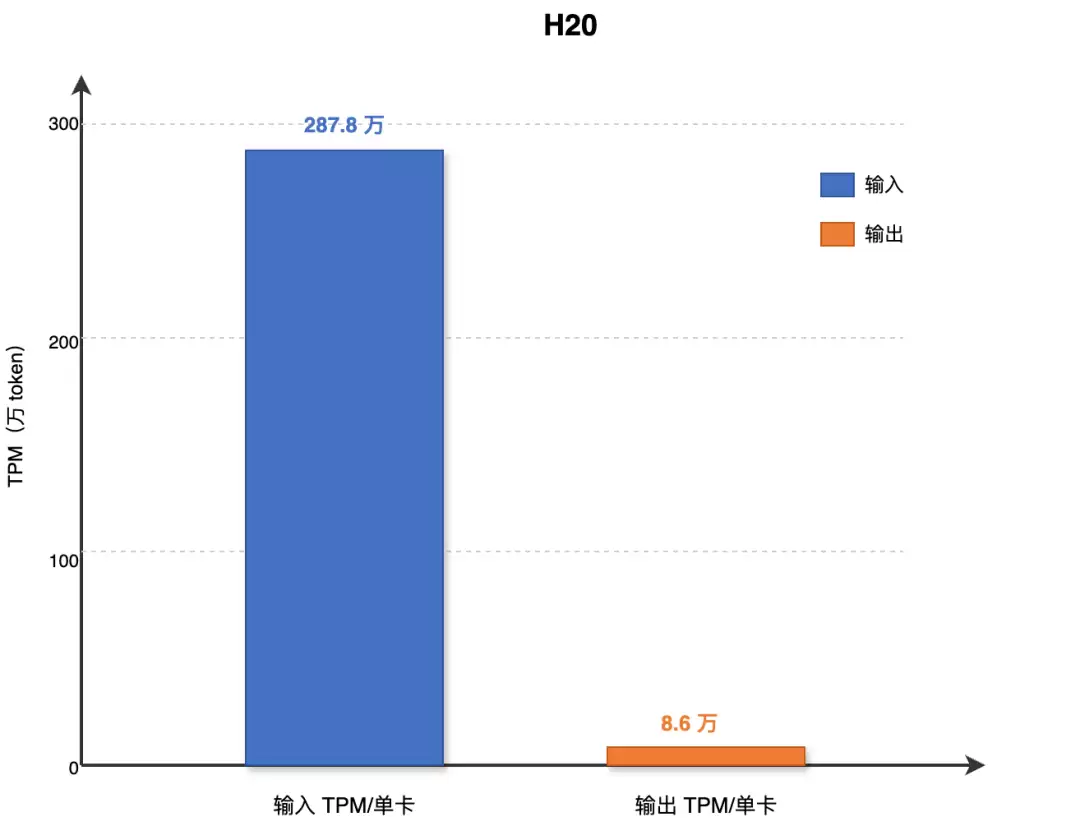
优化成果概览
测试数据集: 5000条真实数据(最大输入192k,平均输入68k;最大输出64k,平均输出0.9k;缓存理论命中率80%)
测试硬件:Hopper架构-96G
约束条件:50ms TPOP,4s TTFT
推理精度: W8A8C8
二、性能优化方案详解
2.1 算子级深度优化
针对Hopper架构特性与Hy3 preview模型结构,团队对Attention、MoE、Rope、Router、Sampler及通信算子进行了系统性深度优化,相关代码已开源在HPC-Ops仓库。
2.1.1 Attention动态调度:负载均衡根治推理长尾延迟
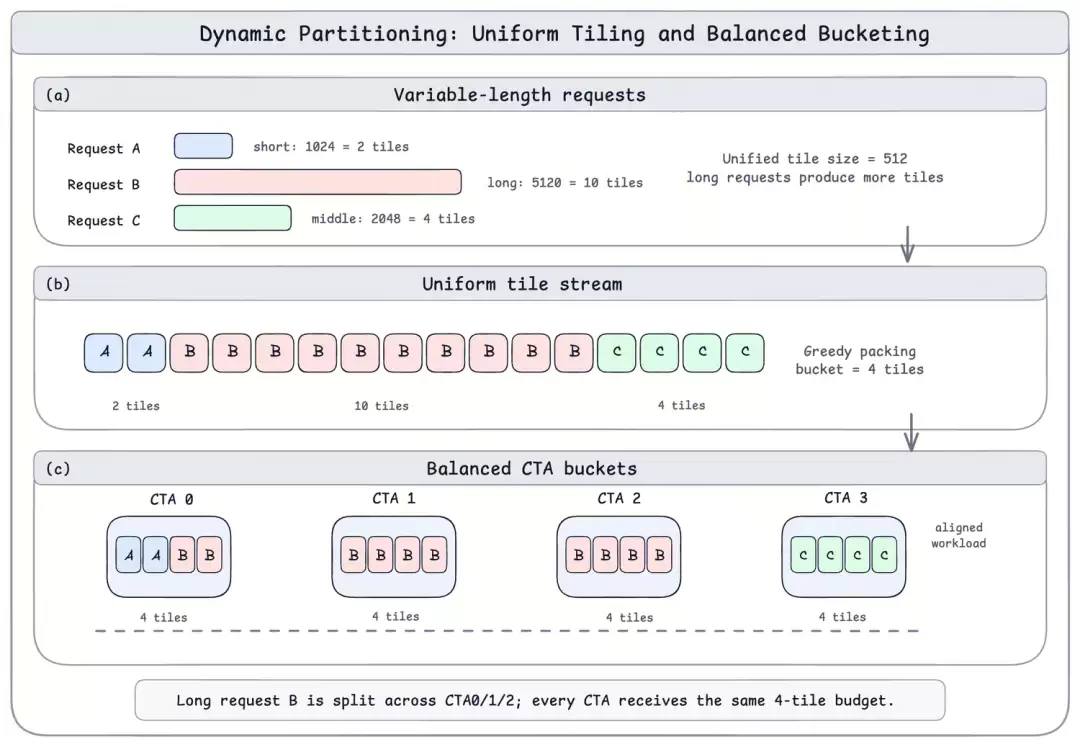
问题剖析
线上推理场景呈现显著动态性:请求长度实时波动,batch内长短请求混杂并存。传统静态split-kv方案需在长序列吞吐与短序列开销之间做出固定取舍,难以兼顾两端需求。
动态调度方案设计
所有推理请求按统一Tile粒度拆分,依据全局Tile总量均衡分配各CTA任务负载
通过贪心装桶算法实现Tile任务极致均分,从根源杜绝计算单元负载失衡现象
执行链路中,Task Assign模块在每次推理前生成专属任务映射表,各层Attention Kernel依据映射表精准领取并执行对应任务
最终由Combine Kernel统一合并split-kv计算结果,实现全流程负载均衡与高效协同运算
性能收益数据
单batch长文本场景下,单算子最高加速达2.95x
混合长度batch场景下,加速效果为1.59x~1.76x
2.1.2 Router GEMM:双BF16重构FP32计算,兼顾高精度与高性能
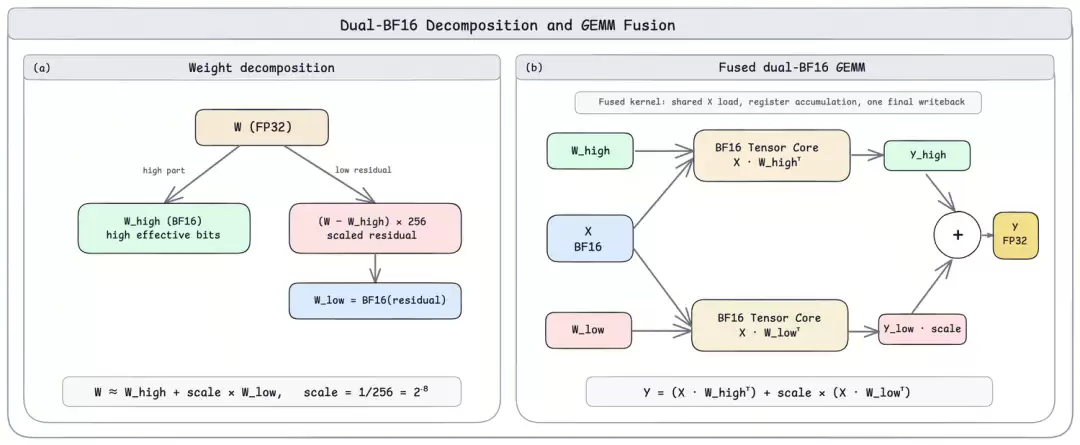
问题背景
在MoE路由及稀疏Attention等数值敏感模块中,传统BF16激活×FP32权重计算面临效率与精度的两难抉择。若将权重降级,模型精度会受损;若将激活升频至FP32/TF32,则需引入类型转换开销,且CUDA Core算力带宽有限,硬件利用率偏低。
解决方案
离线阶段将FP32权重拆分为高位BF16与低位残差BF16两组张量:W ≈ W_high + scale × W_low(scale = 1/256,对齐BF16的8位尾数)。
推理阶段执行两次BF16 GEMM并做线性组合,激活值全程保持BF16格式,无需类型转换,均运行在BF16 Tensor Core之上。
实现层面,双路计算融合至单一Kernel:输入数据仅搬运一次,双寄存器累加器分别缓存两路中间结果,Epilogue阶段经一次FFMA修正出高精度结果写入显存,全程无HBM往返,无冗余开销。
性能收益:N=192、K=4096规格下,在M=2~4096范围内相比FP32(cuBLAS)实现获得2.86x ~ 3.22x加速
2.1.3 FusedMoE:全算子流水线重构,极致压缩推理开销
重构方案设计
HPC-Ops对MoE完整推理链路进行了深度融合与执行逻辑重排,将五大核心阶段整合为一体化执行链路:
路由与索引预处理:基于共享内存分块统计,为每个专家预留连续显存输出区间,大幅降低大规模Token场景下的索引构建成本。
Gate-Up GEMM:通过路由索引直接读取原始输入,省去显式Gather搬运;取消Warp Specialization,由同一Warp Group完成搬运与计算,将访存掩盖逻辑由CTA内软件流水升级为跨CTA硬件调度,显著提升SM驻留密度与资源利用率。
激活量化 + Down GEMM:量化结果按专家维度紧凑写入显存,确保Down GEMM高效顺序访存。
Top-K加权聚合:在推理末端完成加权求和,全程无额外HBM往返。
PDL无气泡串联:全流程通过PDL技术构建无气泡执行链路,彻底消除频繁Kernel启动开销。
性能收益数据
TP=8 / EP=1场景:相比vLLM CUTLASS、vLLM Triton、SGLang获得1.5x – 1.6x加速
TP=1 / EP=8场景:获得1.2x – 1.5x加速
2.2 算子融合优化
2.2.1 Fused Rope+Norm+[Hadamard]+Quant+Store KV
在QKV Projection之后,存在一连串Element-wise算子(Rope、RMSNorm、Hadamard积、量化、KV Cache写入)。这些算子计算量极小、算力强度低,频繁启动Kernel并反复读写HBM会导致严重的访存带宽受限问题,是Prefill阶段不可忽视的延迟来源。
解决思路是将这5个算子深度融合,重构为单一的微型流水线Kernel。数据从HBM载入寄存器后,在片上完成全链路变换,最终只写回一次结果,将多次HBM往返压至最低。
寄存器级数据流转:全流程采用寄存器暂存中间结果,彻底消除中间变量的HBM存取开销。
在线量化与KVCache存储:写入KV Cache前完成在线量化,直接以低比特格式写入显存,进一步压缩写出带宽。
性能收益:融合算子加速约5x
2.2.2 Fused AllReduce+Norm+Add
在张量并行场景下,通信、残差计算与归一化拆分执行会带来性能损耗。联合腾讯网络平台部,实现了通信、残差计算与归一化的全链路融合,封装为NVLink原生一体化操作:RMSNorm(AllReduce(x) + residual, weight)。基于CUDA多播与P2P技术,支持BF16及单机多卡部署,采用高效Two-shot策略。
高吞吐版本(fuse_allreduce_rmsnorm_high_throughput)依托NVSwitch多播机制完成归约计算,适配大规模Token的Prefill预处理场景;
低延迟版本(fuse_allreduce_rmsnorm_low_latency)基于Lamport P2P机制,通过PDL实现双Kernel重叠执行,适配小批量Token的Decode推理场景。
性能收益数据
覆盖8~32k tokens 场景
相比NCCL与FlashInfer同类路径,实测最高加速1.68x
2.2.3 采样融合算子
传统采样后处理链路包含十来个零碎Kernel串联(重复惩罚、温度缩放、Top-K、Top-P、Softmax、随机采样等),流程高度碎片化。每个Kernel都需独立访问全局词表(vocab_size级别),导致HBM加载次数线性膨胀;重复惩罚阶段的掩码数据还需通过CPU-GPU拷贝传输,引入额外同步开销。
优化方案
将10多个Kernel融合为2个核心CUDA Kernel,封装成单一的fused_sampler算子。针对不同业务场景(简单温度采样 / 完整采样),算子内部自动适配专用内核,最大化GPU利用率。
全词表单次加载:将采样全流程所需的全局词表GPU读取压缩至1次,计算与访存充分掩盖。
GPU闭环惩罚计算:重复惩罚掩码在GPU内部完成,彻底消除CPU-GPU数据拷贝开销。
细粒度多CTA并行:单请求拆分至多线程块并行执行,提升小Batch场景下的SM并发度。
局部堆归并Top-K:当Max Top-K ≤ 64时,采用局部堆归并替代全局阈值扫描或拒绝采样,避免全词表重复读取。
Top-K与Softmax融合:将Top-K归约与Softmax的max/sum计算合并,进一步削减访存与计算开销。
收益数据
融合前效果:
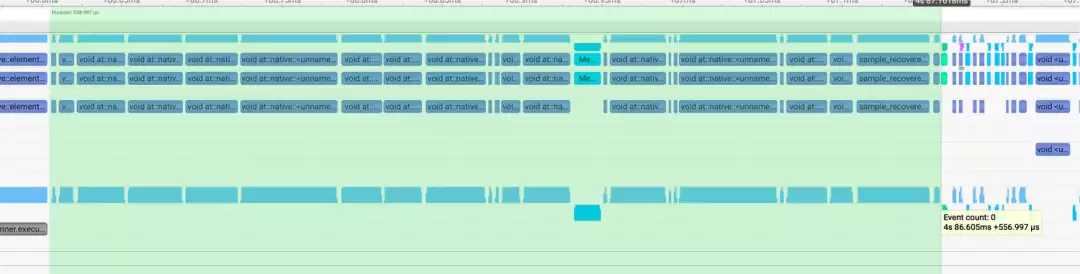
融合后效果:
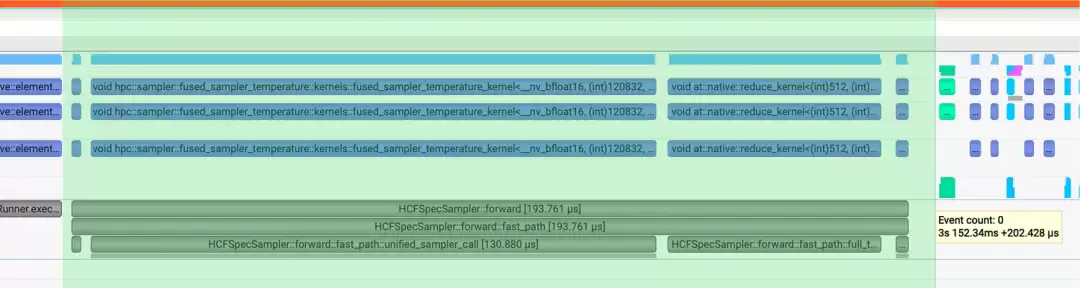
相比vLLM与FlashInfer中的采样算子,性能提升约5.5x、2.5x
2.2.4 Gemm+Comm细粒度通算融合
针对prefill TPSP并行场景,实现了GEMM与ReduceScatter的细粒度通算融合。SM资源被显式划分为计算SM(执行矩阵乘)与通信SM(执行RS搬运)两类角色:计算SM每产出一个Tile即落盘至本地Buffer,并通过信号量通知通信SM对就绪分片立即发起RS,实现Tile级计算与通信重叠。
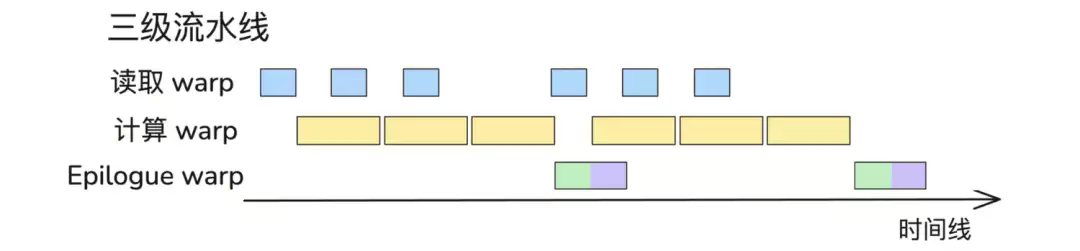
在传统Load Warp与MMA Warp之外,特化出专职Epilogue Warp,形成Load → MMA → Epilogue三级流水线:
Load Warp:异步预取下一轮Tile数据
MMA Warp:累加完毕后仅写回SMEM,立即进入下一轮计算
Epilogue Warp:异步取出SMEM结果,完成Quant/Scale等后处理并写回HBM,最后触发通信SM就绪信号
性能收益数据
矩阵形状 | 分段耗时 | 端到端耗时 | 加速比 | |||
|---|---|---|---|---|---|---|
(M, N, K) | GEMM | RS | 串行 | 本方案 | 覆盖率 | vs 串行 |
(8k, 4096, 1024) | 257.74 | 250.93 | 560.12 | 316.63 | 76.5% | 1.77× |
(16k, 4096, 1024) | 512.04 | 480.82 | 1,096.59 | 604.98 | 80.7% | 1.81× |
(32k, 4096, 1024) | 1,016.46 | 945.63 | 1,962.30 | 1,162.79 | 84.5% | 1.69× |
(64k, 4096, 1024) | 2,026.13 | 1,846.68 | 3,872.58 | 2,307.68 | 84.8% | 1.68× |
*本能力由腾讯混元AI Infra团队与腾讯网络平台部联合优化打磨。
2.3 并行策略优化
2.3.1 Prefill并行策略:TPSP
Hy3 preview模型上纯TP8方案会引入三重代价:
冗余计算:Elementwise / Router等token-wise算子沿完整序列维度在各卡重复执行
通信过重:AllReduce在8卡间交换全量数据,通信开销显著
算子畸形:MoE Grouped GEMM被沿hidden维切至极窄shape,计算效率急剧退化
优化方案
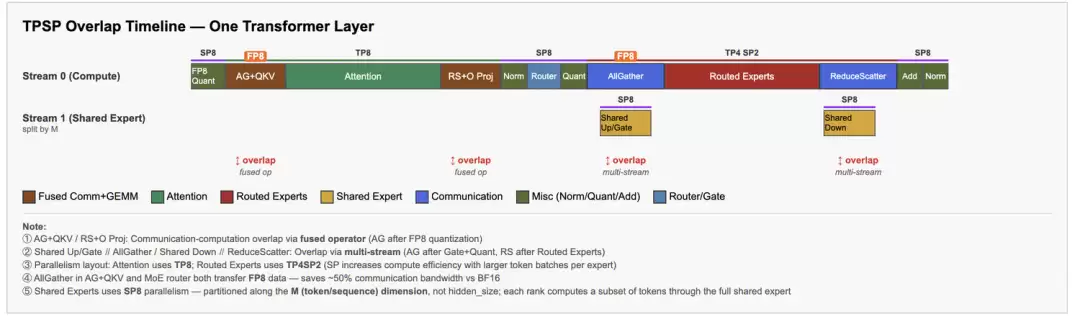
在保持单机8卡部署与模型精度不变的前提下,通过SP拆分 + 通算融合 + 通信量化 + 并行模式调整四项技术组合,系统性压缩TTFT。
性能收益数据
场景 | 优化前 TTFT | 优化后 TTFT | 节省 | 降幅 |
|---|---|---|---|---|
Prefill 16k | 764 ms | 536 ms | −228 ms | −29.9% |
Prefill 32k | 1885 ms | 1424 ms | −461 ms | −24.5% |
2.3.2 Decode并行策略:DP+EP
问题分析
Hy3 preview在单机部署时面临存算双重瓶颈:
显存被权重占用将近一半,挤压KV Cache空间,直接制约最大并发数
在小Batch场景下,MoE Grouped GEMM算力强度低,严重受限于访存带宽(Memory-bound)
优化方案
采用Attention DP + MoE EP的跨节点混合并行架构。通过增加专家并行度(EP Size)实现权重的多机分布式存储,腾出显存空间转产为KV Cache吞吐。同时,跨节点聚合Batch Size使Grouped GEMM进入Compute-bound区域,最大化Tensor Core利用率。
自研HPC Kernel,包含gate、route、group gemm、count and gather、combine等核心操作,在Hopper卡上取得SOTA性能
长序列Attn DPTP混合策略,大幅降低DP负载不均衡带来的影响,只需承担少量机内通信的额外开销
异步专家负载均衡 (Async EPLB),利用NCCL P2P异步执行权重重排。将每步仅一层权重的通信逻辑隐藏于前向计算之后,实现权重重排与Decode计算完全重叠,消除通信干预。
shared expert拆分与dispatch、combine并行,通信与计算overlap

性能收益:端到端吞吐提升15.7 ~ 44.7%
2.4 多级缓存架构
背景与动机
Agent、Coding等场景中存在大量长上下文、多轮对话及可复用公共前缀,Prefill计算开销直接影响TTFT与整体吞吐。但Prefix Cache若仅依赖GPU显存,会面临四重瓶颈:
容量受限:权重与运行时占用后,可用于缓存的显存空间极为有限
淘汰加速:长文请求产生的大体量KV Cache加速已有缓存淘汰
重复计算:缓存淘汰后相同前缀需重新Prefill,算力浪费严重
跨实例不可复用:单机缓存在实例迁移、扩缩容、跨节点调度时完全失效
解决方案
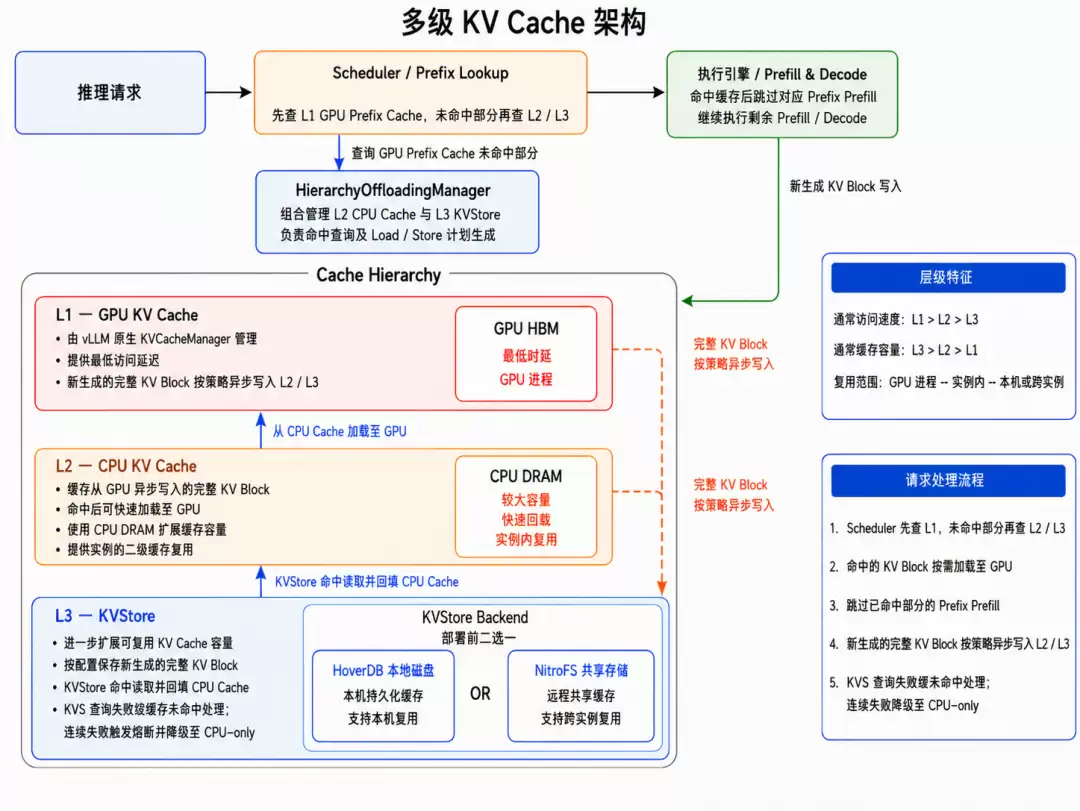
构建了GPU → CPU → KVStore三级缓存体系,将KV Cache从单一显存短期缓存扩展为可分层存储、按需加载、跨请求复用的多级架构。在不增加GPU显存占用的前提下,显著扩大有效缓存容量,降低重复Prefill概率。
调度流程:请求进入时按L1→L2→L3顺序查询可复用前缀,命中后按需加载回GPU并跳过对应Prefill;新生成的完整Block根据策略异步下沉至L2/L3,供后续请求复用。
2.5 MTP与异步调度优化
问题剖析
传统异步调度基于"每轮稳定生成1个token"的假设,在GPU计算时让CPU提前准备下一轮输入,掩盖CPU耗时。但多层MTP引入了动态接收长度——下一轮的序列长度、位置编码及KV Cache映射都强依赖验证结果。传统做法需在GPU Forward验证结束后强制同步,把结果拷回CPU再准备下一轮输入,导致CPU准备阶段只能与MTP层Forward重叠;而MTP层计算极快,无法充分掩盖CPU耗时。
优化方案

核心思路:解除CPU对真实接收长度的同步依赖——数据准备阶段一律按最大接收长度更新状态并组装下一轮输入;在下一轮实际计算前,再以上一轮的真实验证结果修正计算所依赖的关键值。这样CPU可提前一轮完成准备与Launch,无需阻塞等待GPU计算结果。
收益数据:减少decode间5~10ms CPU气泡,端到端性能提升10%~20%
2.6 量化压缩技术
2.6.1 量化方案
问题背景
模型规模持续增长,显存瓶颈与访存带宽压力成为部署落地的核心约束。直接应用W4A8量化和Attn FP8量化虽能大幅压缩模型体积,但权重的极低比特表示与激活中的离群值会严重放大量化误差,导致精度显著退化。
解决方案
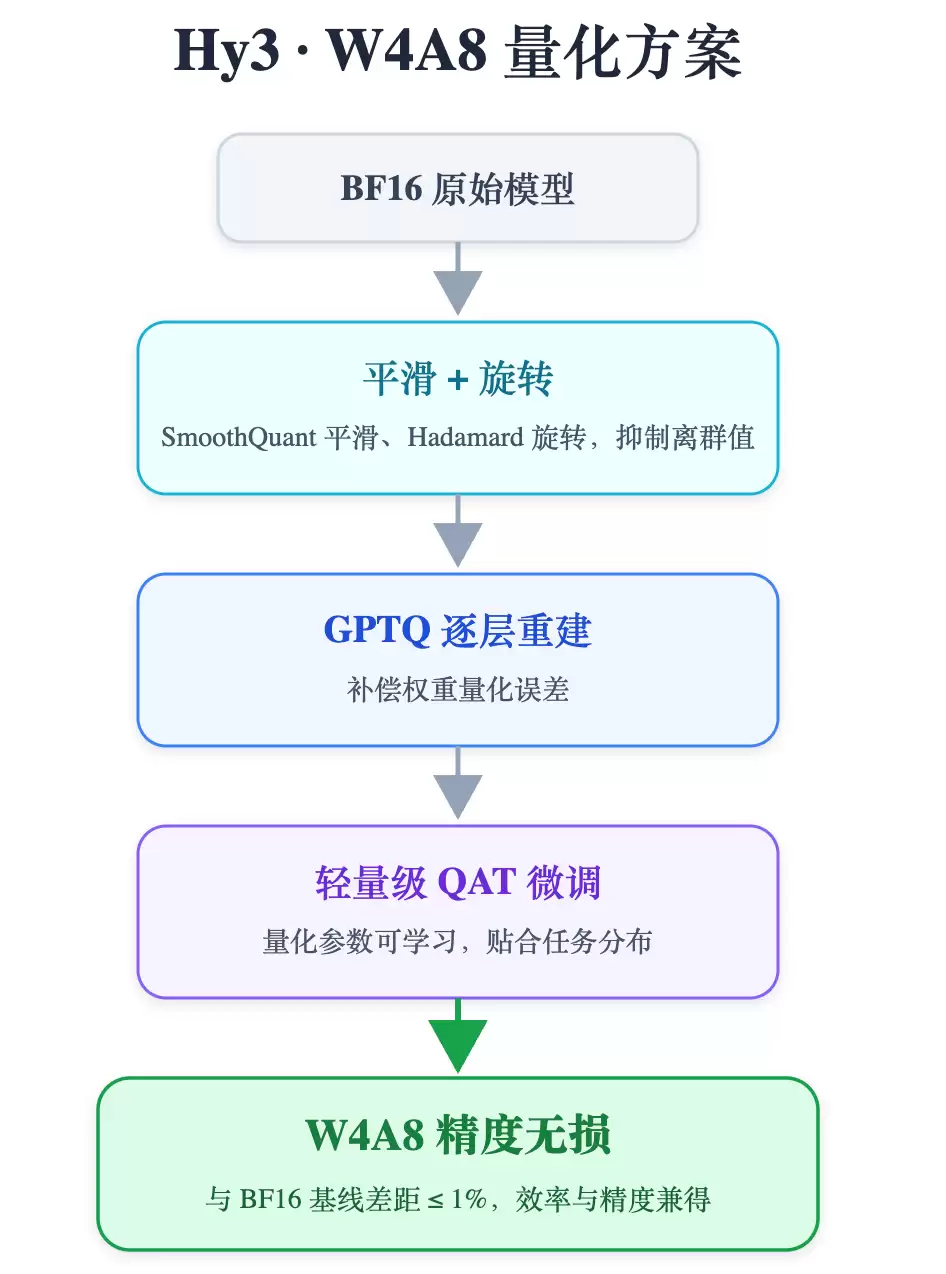
在AngelSlim框架中构建Hy3 preview量化方案,通过"GPTQ权重重建 + 激活平滑与旋转变换 + QAT轻量化微调"三级联合优化,系统性消除Attn FP8 + W4A8配置下的精度损失。
GPTQ逐层权重重建
基于Hessian逆的逐层误差补偿,显著降低INT4权重量化引入的精度损失。
激活平滑(Smooth)
利用搜索得到的逐通道平滑因子,在不改变模型输出的前提下压缩激活离群值幅度,有效收窄数值动态范围。
Hadamard在线旋转变换(Attention专用)
对Query/Key量化前施加正交旋转,将集中于少数通道的离群值均匀打散,抑制量化误差;变换本身计算高效、可融合至推理Kernel,几乎零额外开销。
QAT轻量化微调
训练中模拟W4A8量化噪声,仅更新量化相关参数(如scale/zero-point),使模型自适应学习最优量化配置。收敛迅速,训练成本极低。
性能收益数据
精度表现:多领域评测集上与BF16基线持平或差距 < 1%,实现精度无损。
性能提升:端到端吞吐提升28%+
2.6.2 稀疏注意力机制
Hy3 preview支持最大256K上下文,但标准自注意力的二次方复杂度导致Prefill阶段延迟和显存开销随序列长度急剧增长,成为制约TTFT的关键瓶颈。
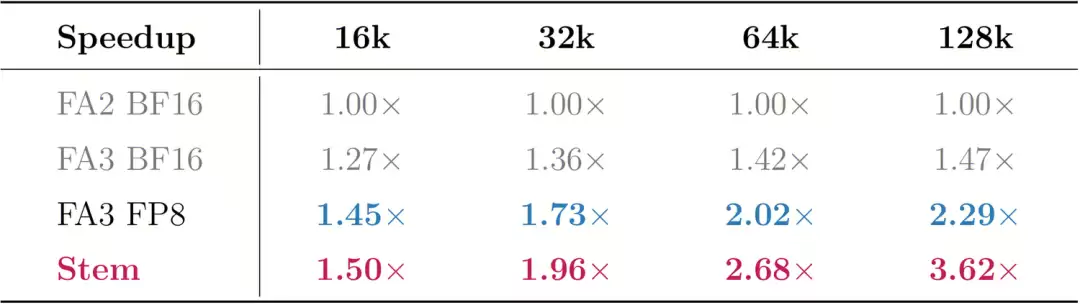
为此,团队提出了Stem稀疏注意力算法,结合HPC-BSA(Block Sparse Attention)算子,在仅使用25%计算预算的条件下实现接近稠密注意力的精度,将128K上下文下的Prefill延迟降低了3.6倍。
核心思路:从因果注意力的信息流视角出发,重新审视"哪些token该保留、哪些该剪枝",配合HPC-BSA算子实现上述效果。
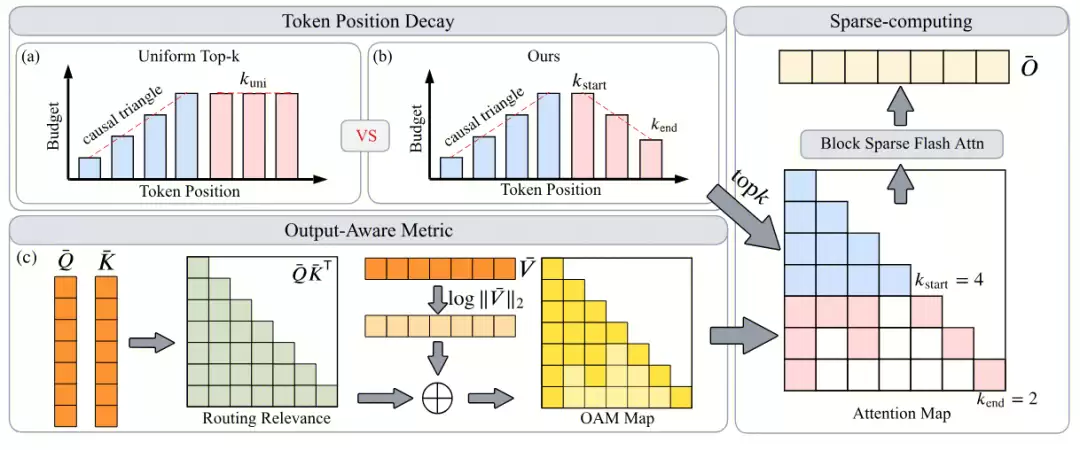
Stem整体流程图
两大关键技术
Token Position-Decay(位置衰减策略)
洞察:因果架构中,序列头部token参与了所有后续聚合计算,误差会逐层递归放大;尾部token影响仅局限于局部。
做法:将每个query位置的Top-k预算从头部的
k_start线性衰减到尾部的k_end = μ · k_start。头部关键token获得更大预算以保护递归依赖链,尾部冗余token被激进剪枝。效果:总预算不变,仅通过重新分配即可显著提升精度。
Output-Aware Metric(输出感知度量,OAM)
洞察:传统方法仅基于注意力分数(QK^T)选择token,但注意力分数只反映"路由概率",并非实际"信息贡献"。高注意力但Value模长接近零的token对输出几乎无贡献。
做法:提出OAM度量公式
M(i,j) = QK^T + β · max(0, log(‖V_j‖₂)),将Value向量模长作为信号强度引入选择标准。优势:对数变换使其可直接复用标准Top-k内核,无额外计算开销。
具体方案已集成至AngelSlim。
收益数据
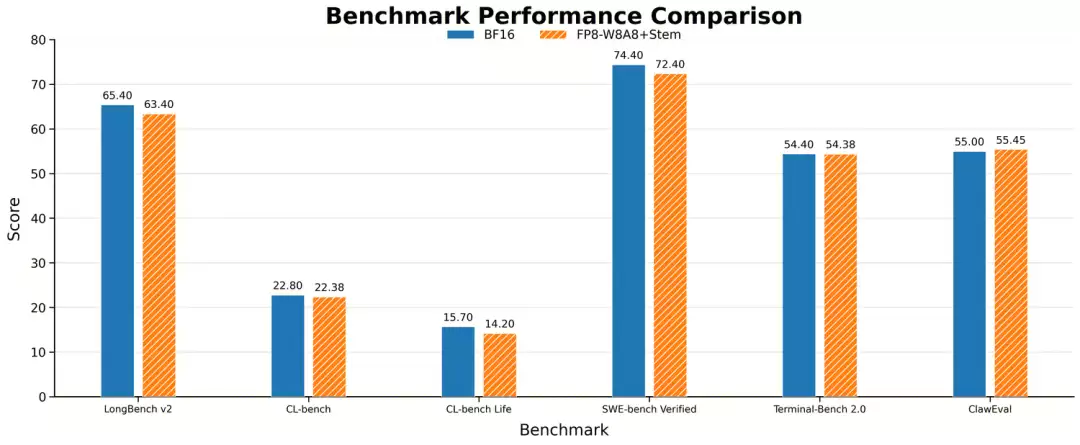
模型精度方面,在LongBench v2、CL-bench、SWA等多个数据集上取得了与密集注意力相当的精度。对比密集注意力,在128K上模型首字耗时提升3.6倍。
三、后续工作展望
在长上下文场景下,经过一系列优化后仍面临显存瓶颈,为此团队正积极推进C4与W4相关优化,在确保精度无损的前提下,进一步提升推理吞吐能力。
针对超高吐字速度的需求,正在探索全新的并行投机解码方案——在保证接收率的同时,以更低计算代价产出更多投机Token,有望实现吐字速率的大幅跃升。
与此同时,在调度与并行策略、PD高效传输、多级缓存中心、跨机通信与流量控制等关键环节,也在持续进行深入优化。
值得期待的是,团队同步推进对其他硬件平台的适配与优化工作。凭借更优的硬件性价比,推理成本有望进一步降低。