京东健康在OPC模式下探索高效交付时,遇到了一个非常现实的问题:团队里没有专职产品角色。这意味着,开发者不能只埋头写代码,还得回答一连串更前置的问题——这件事究竟值不值得做?支撑它的证据来自用户、数据、业务,还是仅仅是个人感觉?这个方案是唯一的吗?需求边界划清楚了吗?当前迭代有资源接吗?上线后怎么判断成败?进度和风险又该跟谁同步、怎么同步?
这听起来是不是特别熟悉?这说明一个问题:团队不能只满足于“把事做完”,还得主动承担产品判断的角色。
好消息是,Anthropic开源了一套Product Management Skills产品管理技能,正好能解决这些痛点。它本质上是一套产研共同决策的框架——把从发现需求到上线复盘的全过程,拆成一系列可重复使用的小动作。这样一来,即使没有专职产品经理,OPC团队也能保持清晰、可追溯、可评审的产品流程。
下面,就把这套实践适配到OPC的真实工作场景中,看看如何快速补齐团队的产品能力短板,跑通从需求发现到上线复盘的全链路。
流程总览:产品管理框架概览
在开始之前,先理清整个框架的脉络。
安装 Skill
这套实践在Anthropic原生的环境里对应一个product-management插件。如果你用的是JoyCode或Codex,需要接入`product-management/skills`目录下的8个Skill。在对话框里输入以下提示词就能完成安装:
从https://github.com/anthropics/knowledge-work-plugins/tree/main/product-management/skills
安装以下 skills:
synthesize-research、metrics-review、competitive-brief、product-brainstorming、
write-spec、roadmap-update、sprint-planning、stakeholder-update。一条判断链:从问题发现到决策闭环
这8个Skill最常见的使用顺序是这样的:

这条链的内在逻辑其实很好理解:
- 先问自己——这个问题值不值得做?这叫“问题判断”;
- 觉得值得了?那就把方向打磨成可执行的需求,这是“需求定义”;
- 需求有了,再放进优先级、团队容量和各种依赖约束里做个权衡,这是“排期执行”;
- 最后,用指标来验证结果,并向不同的人做同步,这就到了“上线复盘”。
可以把它当成团队内部的一条轻量工作协议:任何需求只要进入开发环节,就至少要走过“证据、假设、边界、排期、验收、复盘”这六个关卡。
第一阶段:问题判断
本阶段的目标:判断“这个问题是否足够重要”,而不是证明“我们想做的方案是对的”。
需求刚出现的时候,别急着写PRD,也别一头扎进技术方案里。第一步,先冷静下来,判断问题本身是不是真的成立。
使用哪些 Skill

怎么接入需求上下文
Anthropic的做法很有意思——他们不是让团队手工整理一份完整的报告再交给AI,而是把现成的材料按来源直接接入到Skill工作流里。以`synthesize-research`为例,它支持三种输入方式:
- 直接粘贴:访谈记录、会议纪要、问卷开放题、工单摘要;
- 上传文件:研究文档、表格、录音转写摘要、调研结果;
- 连接工具:从知识库、用户反馈系统、产品分析工具、会议转写工具里拉取上下文。
在Anthropic的插件设计里,这些工具用通用占位符表示:
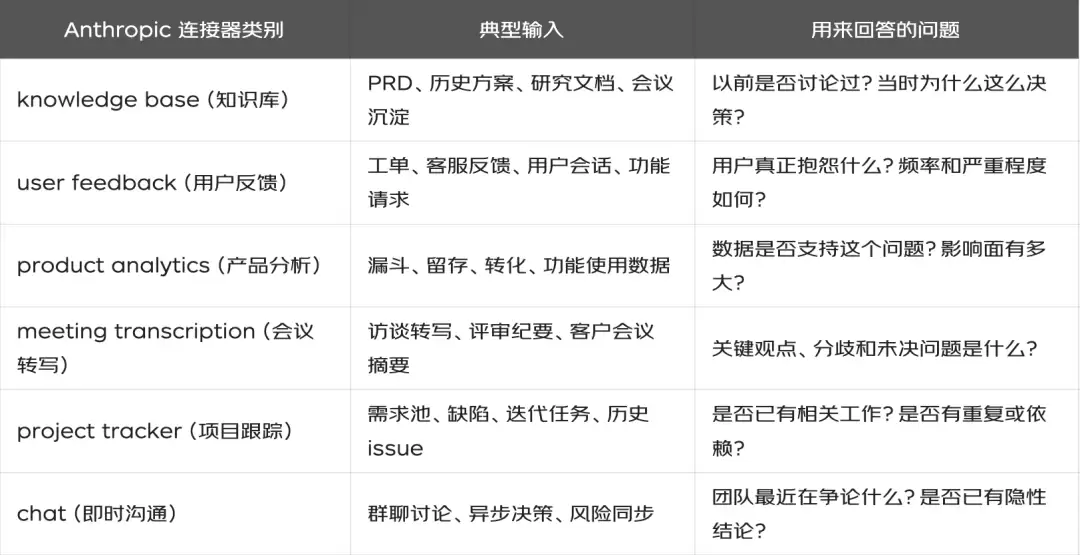
虽然我们没法直接用海外工具的连接器,但思路完全可以复用:把内部系统里的材料,一一映射到同样的证据类别上就行。
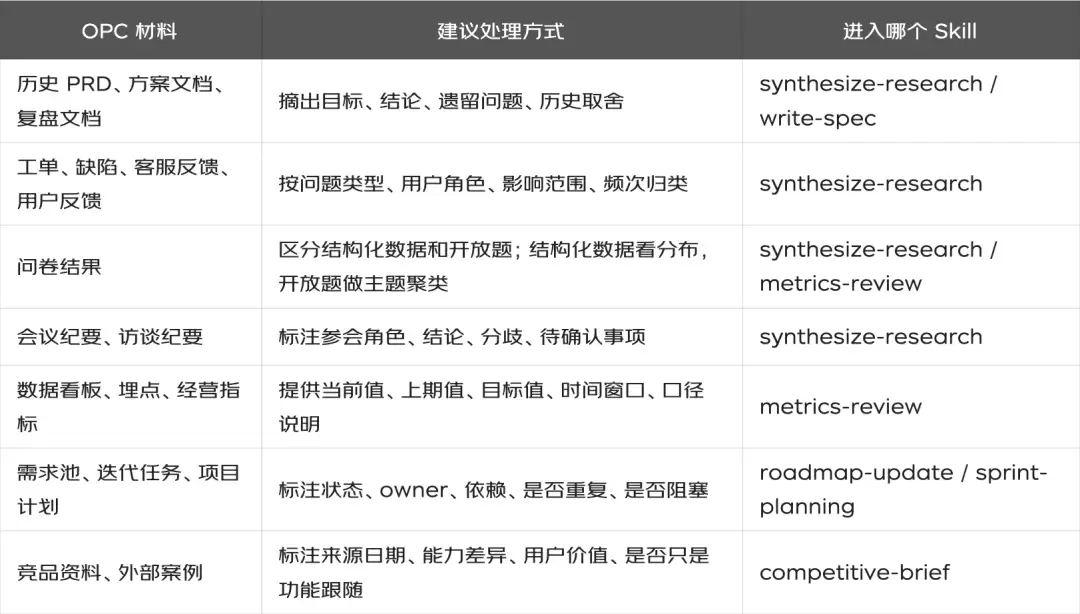
这里有个关键点:千万别把材料一股脑儿无差别地丢进去。每份材料进入Skill之前,至少要带上5个字段:
## 材料输入格式
-来源:来自哪个系统、文档或会议?
-时间:材料产生于什么时候?是否仍然有效?
-对象:涉及哪个用户、业务方、系统或场景?
-内容:核心事实、原话、数据或结论是什么?
-关联:它支持或反驳哪个问题假设?启动提示词:用于问题判断阶段的模板
可以直接用这段提示词来启动问题判断:
请按 synthesize-research / metrics-review 方法,
帮我判断这个问题是否值得进入需求定义。
我会提供以下材料:
1.历史文档和已有结论
2.工单 / 用户反馈 / 缺陷记录
3.问卷和访谈纪要
4.会议纪要和待决策事项
5.指标看板或数据摘要
请输出:
-主要问题主题
-每个主题的证据来源
-频率、影响和置信度
-用户说法与实际数据是否一致
-当前最关键的假设
-还缺哪些证据
-是否建议进入 product-brainstorming 或 write-spec本阶段的产出:问题主题清单 + 证据与置信度评估 + 是否进入需求定义的结论。
第二阶段:需求定义
本阶段的目标:把“值得做的问题”打磨成可评审、可拆解、可验收的需求规格。
先发散:product-brainstorming
当确认问题值得继续推进之后,先进入`product-brainstorming`。这个Skill的价值在于帮助团队拆解问题空间、方案空间和关键假设。它会推动团队追问几个硬核问题:
- 谁真正有这个需求?
- 用户现在是怎么绕过这个问题的?
- 这是症状还是根因?
- 除了当前方案,还有没有其他替代方案?
- 哪个假设一旦错误,整个方向就站不住了?
- 最便宜的验证方式是什么?
再收敛:write-spec 撰写产品需求文档
方向收敛之后,用`write-spec`生成需求规格。重点是让需求具备可评审、可拆解、可验收的结构。OPC团队的需求规格,建议至少包含这些内容:
## 需求规格
### 1. Problem
用户是谁?问题是什么?不解决会造成什么影响?
### 2. Evidence
证据来自哪里?用户反馈、数据、竞品、业务承诺分别是什么?
### 3. Goals
本需求要达成哪些可衡量的结果?
### 4. Non-goals
本期明确不做什么?为什么不做?
### 5. Requirements
- P0:没有这些就不能解决核心问题。
- P1:明显改善体验,但不阻塞上线。
- P2:未来可能需要,但本期不做。
### 6. Acceptance Criteria
如何判断每个需求点已经完成?
### 7. Metrics
上线后看哪些领先指标和滞后指标?
### 8. Open Questions
还有哪些问题没解决?谁负责回答?是否阻塞开发?一个好的需求规格,不是把所有想法都堆进去,而是清楚说明:为什么做、做什么、不做什么、做到什么程度算完成。
本阶段的产出:经过假设检验的方向 + 一份结构完整的需求规格文档。
第三阶段:排期执行
本阶段的目标:把需求放进优先级、容量和依赖约束里,落地成可执行的迭代计划。
需求清楚了,还不能直接进入开发。你还需要判断它在整体计划里的具体位置。
先定位置:roadmap-update 更新路线图
`roadmap-update`适合用来回答这些问题:
- 这个需求应该放在Now、Next还是Later?
- 它和当前目标、OKR或项目主题是否一致?
- 它依赖哪些人、系统、数据或外部条件?
- 如果要插这个需求,有什么需求要延期、降级或移除?
- 当前roadmap是不是已经超出团队的实际产能了?
在OPC里尤其要牢记一个原则:新增需求不是“多做一点”,而是一次资源的重新分配。
每次新增或调整需求优先级,都应明确说明:
## Roadmap 变更说明
-变更内容:新增 / 提前 / 延后 / 移除什么?
-变更原因:出现了什么新信息?
-影响范围:影响哪些需求、人员、时间点?
-取舍结果:为了做它,什么被降级、延期或移除?
-风险与依赖:有哪些阻塞项?谁负责处理?再落计划:sprint-planning 制定迭代排期
当需求被放进展路后,用`sprint-planning`把它落到具体的执行计划:
- 本迭代唯一的一个Sprint Goal是什么?
- 团队真实可用的容量是多少?
- 上个迭代的carryover(顺延任务)是因为什么?
- P0、P1、P2分别是什么?
- 每个事项的Owner是谁?
- 哪些依赖和风险会影响交付?
- Definition of Done(完成标准)是什么?
建议只规划70%-80%的产研资源容量,剩余的空间留给线上问题、临时协作、评审返工和那些不可预见的打断。
本阶段的产出:一份带取舍说明的Roadmap变更记录 + 一份带容量约束的迭代计划。
第四阶段:上线复盘
本阶段的目标:用指标来验证结果,形成下一步的决策,并向不同对象完成同步。
上线不是终点,而是下一轮判断的起点。
用指标说话:metrics-review 指标复盘
上线之后,应该再用`metrics-review`,把结果拉回到需求最初定义的成功指标上去:
## 上线复盘
-目标指标是否发生了变化?
-哪些领先指标最先出现了信号?
-哪些用户群体受益最大?
-是否出现了负向影响?
-结果符合预期,还是推翻了原来的假设?
-下一步是继续迭代、扩大范围、回滚,还是停止投入?复盘的时候,要避免只说“已上线”、“已完成”。应该回答的是:上线后我们学到了什么,下一步的决策是什么。
分对象同步:stakeholder-update 利益相关方同步
当需要向不同的人同步时,用`stakeholder-update`。同一件事,对不同的人要有不同的表达方式。

建议固定使用状态色来统一认知:
- Green:按计划推进,没有明显的阻塞;
- Yellow:已经出现风险,需要关注或调整;
- Red:明显偏离了计划,需要决策、资源或范围调整。
状态色不是用来汇报好坏的,而是帮助团队尽早发现和处理风险。
本阶段的产出:一份指标对照的复盘结论 + 面向不同对象的同步材料。
快速上手:试点同事的最小启动路径
如果你的团队刚开始OPC试点,不需要一次性把8个Skill全部用起来。建议按下面的路径,用一个真实需求先把链路跑通:
第一步:安装Skill(10分钟)
按第二章的提示词,在JoyCode或Codex里安装好8个Skill。
第二步:挑一个手头的真实需求(别挑太大的)
找你近期正要评估或正要排期的需求,规模以“一个迭代内能做完”为宜。
第三步:先只用三个Skill跑一遍核心链路
- 把手头的工单、反馈、数据按“材料输入格式”整理好,用`synthesize-research`做一次问题判断;
- 如果结论是值得做,用`write-spec`产出需求规格,拉着研发一起评审;
- 上线后,用`metrics-review`对照规格里的Metrics做一次复盘。
第四步:补齐其余环节
核心链路跑顺之后,再把`product-brainstorming`(方案发散)、`roadmap-update` / `sprint-planning`(排期)、`stakeholder-update`(同步)补进日常流程里。
第五步:沉淀团队约定
把跑通过程中形成的模板(材料输入格式、需求规格、Roadmap变更说明、复盘清单)固化下来,变成团队文档,后面的需求直接复用即可。
常见误区
结合实践来看,有几个坑特别容易踩:
- 拿到需求就写PRD。一步到位写PRD,那是典型的“跳过问题判断直接解题”。第一步永远是问题判断:证据够不够?问题值不值得做?跳过这一步,后面做得再快,也可能是白做。
- 用Skill来证明自己想做的方案是对的。问题判断阶段的目标是判断“问题是否足够重要”,不是给你的既定方案找论据。
- 把材料无差别地丢给AI。没有来源、时间、对象、关联假设的材料,产出的结论置信度会非常低。先按5字段格式整理,再进入Skill流程。
- 把新增需求当成“多做一点”。团队的容量是恒定的,新增需求必然会挤占其他事项。每次插入需求,都要写清楚取舍结果。
- 迭代排满100%的容量。线上问题、临时协作、返工是常态,只规划70%-80%,剩下的留作缓冲。
- 复盘只说“已上线”。上线只是验证的开始。复盘要回答:指标变了没有、假设验证了没有、下一步怎么决策。
- 对所有人用同一份汇报。管理层要结论和决策点,研发要阻塞和优先级,跨职能团队要配合事项。同一件事,按对象裁剪表达方式。
总结
对OPC团队来说,这套Skill最大的价值不在于多了几个AI工具,而在于:让产品与研发共同承担起产品判断的责任,并且把每一次判断沉淀成可讨论、可追踪、可复盘的工作资产。
证据、假设、边界、排期、验收、复盘——任何需求进入开发前后,都走一遍这六个环节。这样,即便在没有专职产品角色的情况下,OPC团队也依然能保持产品流程的质量和节奏。
参考来源
- Anthropic Product Management Plugin(https://github.com/anthropics/knowledge-work-plugins/tree/main/product-management/skills)
其他同类方案:
- phuryn/pm-skills(https://github.com/phuryn/pm-skills)
- refoundai/lenny-skills(https://github.com/refoundai/lenny-skills)