这篇文章的核心意图,是用两个具体案例来拆解AI Agent Skill的设计逻辑。一个关注“信息媒介”的持久化,另一个关注“视觉呈现”的一次性爆发。它们看似截然不同,但底层的方法论却高度一致。以下逐一拆解。
▐Skill.md 的定位:编排者而非执行者
- 核心原则:SKILL.md只负责流程编排和决策指引,不嵌入大段实现代码。
- SKILL.md应该回答的问题是:
- 这个Skill什么时候被触发?(触发条件)
- 分析流程有哪些步骤?(步骤编排)
- 每一步调用哪个脚本的哪个函数?(实现委托)
- 遇到异常情况如何决策?(判定标准)
- 不应该出现的内容是大段的Python代码——那些应该放在 scripts/ 里。
- 建议篇幅:控制在200行以内(行业里的成熟案例,通常是170行和133行左右),过长的SKILL.md会稀释重点,Agent反而可能忽略关键指引。
▐config.yaml的设计哲学:模板而非表单
最初把config.yaml写成下面这样:
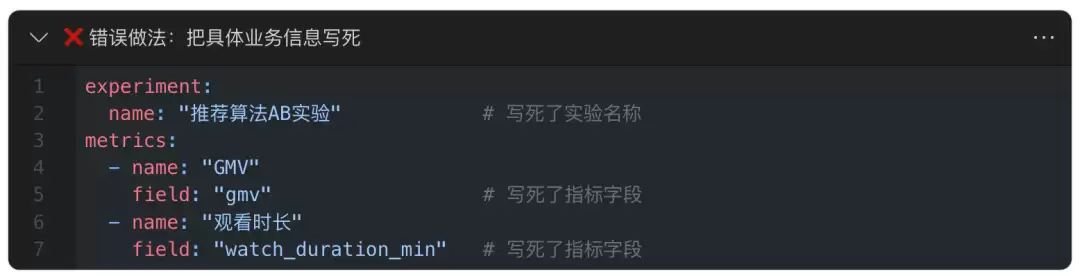
这根本就不是配置模板,而是一份填好的表单。下次换一个实验项目(比如“直播红包实验”或“搜索排序实验”),这份配置就完全不适用了。
正确的做法是——定义参数结构模板:
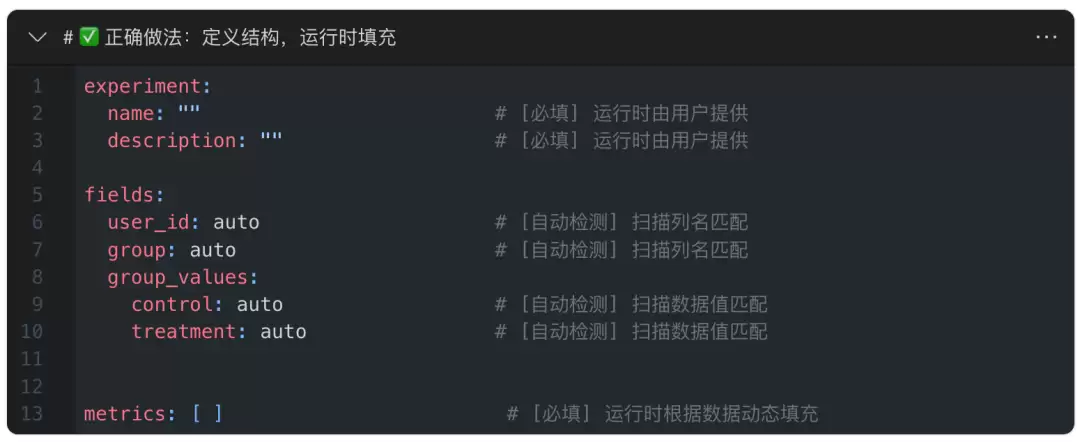
- 设计要点:
auto占位符:表示该字段由 scripts/ 中的自动检测逻辑在运行时填充- 空列表
[ ]:表示该配置项的结构已定义,但具体值在每次运行时动态决定 [默认值]标注:有合理默认值的参数(如significance_level: 0.05)可以直接填入- 注释说明每个字段的含义、标注 [必填]/[自动检测]/[默认值]
▐scripts/ 的价值:复杂逻辑的归宿
- Agent擅长写简单的代码片段,但对于需要精确控制的复杂逻辑(统计检验方法选择、字段自动检测、图表样式),让Agent每次临场发挥是不可靠的。
- scripts/的作用是把这些关键逻辑固定下来,确保每次执行结果一致。
- 以AB实验中的字段自动检测为例:
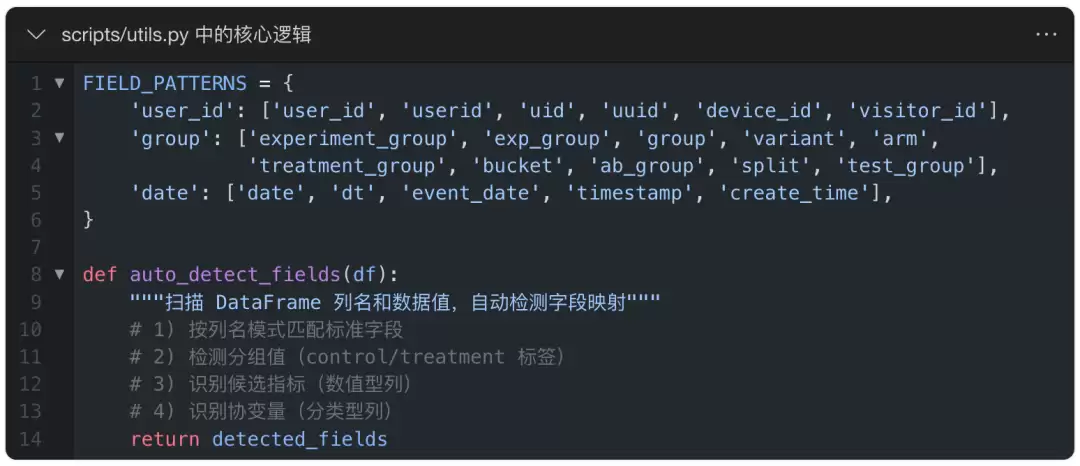
- 这个函数覆盖了常见的几十种列名变体,保证无论数据来自哪个系统,都能高概率自动映射成功。如果靠Agent每次自己猜,准确率和一致性都无法保证。
▐references/ 的作用:知识的渐进式披露
- SKILL.md篇幅有限,不可能把每个统计方法的原理都写进去。references/提供了渐进式披露(Progressive Disclosure):
- SKILL.md只说「连续型指标用Welch's t-test,非正态时回退到Mann-Whitney U」
- references/statistical_methods.md详细解释为什么选Welch而非Student、效应量怎么计算、多重比较校正的原理
- 这样Agent在正常执行时读SKILL.md就够了;当用户追问“为什么用这个方法”时,Agent可以引用references/中的详细说明。

对比上述设计理念
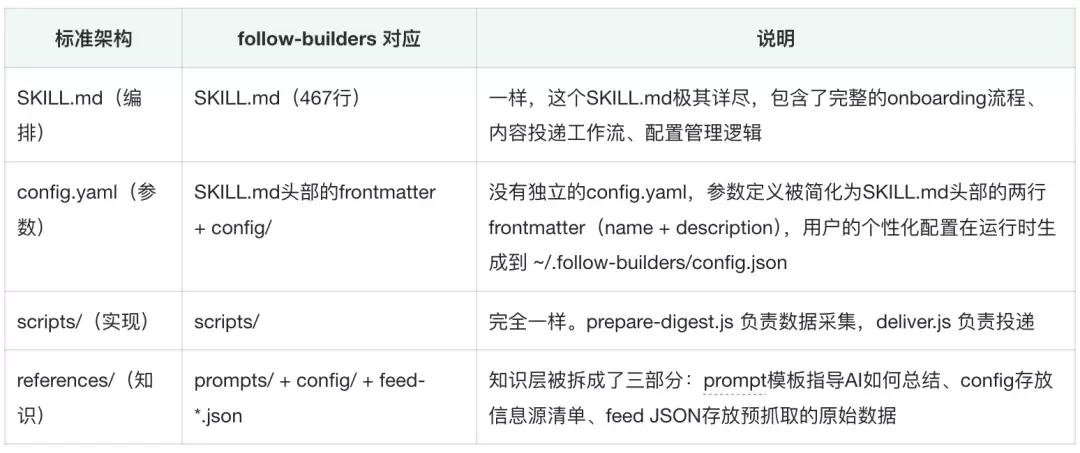
- 所以核心区别并不是“架构不同”,而是:
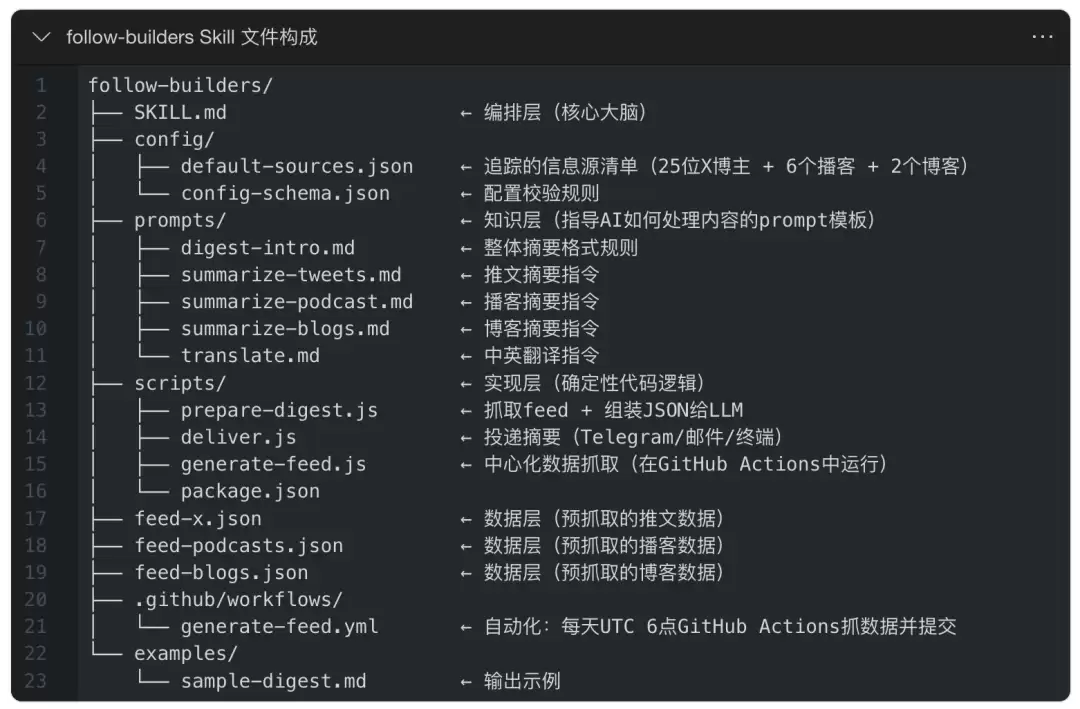
- 没有config.yaml,配置极简化。这个Skill的frontmatter只有name和description两个字段,所有复杂的用户偏好(语言、频率、投递方式)都在首次运行时通过对话生成,存到 ~/.follow-builders/config.json。
- 【知识层】被解构了。传统Skill把参考资料统一放在references/,这个Skill把它拆成了三种不同形态——prompt模板(给AI的指令)、JSON feed(给脚本的数据)、config(信息源列表)。
- 多了一个“中心化数据服务”。这是这个Skill最独特的地方:它不要求用户自己配API key去抓推文和播客。作者在GitHub上设了一个每天自动运行的GitHub Actions流水线(.github/workflows/generate-feed.yml),用自己的X API key和Supadata key抓取数据,结果提交为仓库里的feed-*.json文件。用户端的prepare-digest.js只需从GitHub raw URL拉取这些JSON即可。
▐Frontend Slides
HTML演示文稿生成技能,通过“先看再选”的视觉预览引导用户发现风格,最终让AI在严格的工程边界内生成零依赖的单文件网页幻灯片
功能链:模式检测(识别是新建、PPT转换还是增强现有文件) → 内容发现(一次性收集:目的、长度、内容、编辑偏好) → 风格发现 (生成3个视觉预览) → 生成交付 → 分享导出
⚠️ 注意:含内部数据的文稿生成后请不要选择Vercel部署,以免数据泄露;可以直接让Agent删除部署脚本
实际文件结构
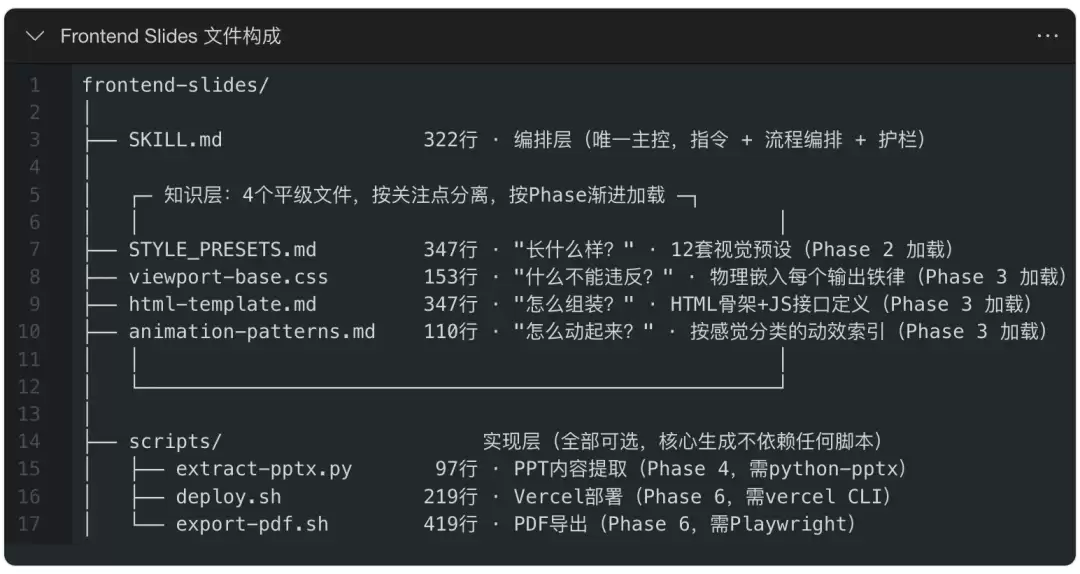
对比上述设计理念

分层拆解值得学习的部分
1)第一层:编排层 — SKILL.md
核心设计理念:作者把AI当作一个会遗忘、会走捷径、会趋于平庸的处理器来编程,所以在关键决策点反复设置冗余校验。
几个值得学习的技巧:
“NON-NEGOTIABLE”标注法。第16行写“Viewport Fitting (NON-NEGOTIABLE)”,然后在第39-48行展开规则,第49行再强调“read viewport-base.css and include its full contents”,第62行兜底“Never cram, never scroll”。同一条铁律在文件中间出现了4次不同表述——这不是啰嗦,而是对抗AI在长上下文中注意力衰减的工程手段。
反模式清单。第19-35行不只说“要做什么”,还显式列出“不要做什么”——overused fonts(Inter、Roboto、Arial)、cliched color schemes(purple gradients on white)、predictable layouts。这是给AI设置负向约束,因为大模型的“模式坍缩”倾向会让它总是输出最高频的组合,必须显式阻断。
内容密度限制表。第53-61行用一张6行的表格,给每种slide类型规定了硬性内容上限(比如content slide最多4-6个bullet)。
“一次性问完”指令。第90行 "Ask ALL questions in a single AskUserQuestion call"。作者深知多轮交互的成本(用户流失、上下文漂移),把Phase 1设计成一次性收集所有信息的“表单”。
Gotchas前置。Phase 6把部署和导出的“坑”直接写进了SKILL.md,而不是放在脚本注释里。这意味着AI在决定是否调用脚本之前就知道可能出什么问题,能主动提醒用户。
2)第二层:参数层 — 被“溶解”了
- 原因在于:配置的本质是“提前固化的决策”。但这个skill的所有决策都是运行时通过对话收集的——用户的mood、slide数量、内容类型,在Phase 1-2实时确定,不存在“提前配置”的场景。
- 传统config层的功能被“溶解”到了三个地方:用户对话(Phase 1-2收集的偏好,相当于“运行时配置”)、STYLE_PRESETS.md(12套预定义风格,相当于“枚举型配置”)、viewport-base.css(硬性约束,相当于“不可配置的常量”)。
- 对比follow-builders:它需要config是因为用户的追踪偏好(语言、频率、投递方式)是跨会话持久化的。而frontend-slides每次生成演示文稿都是独立的一次性任务,用完即走,天然不需要持久化配置。
3)第三层:实现层 — scripts/
- 核心功能(从零生成HTML幻灯片)完全不依赖任何脚本——它只靠SKILL.md编排 + 知识层的4个文件就能工作。
- 脚本层是纯粹的“可选服务”。extract-pptx.py只在PPT转换时调用,deploy.sh只在用户选择部署时调用,export-pdf.sh只在用户选择导出PDF时调用。
- 当“实现层”是AI本身时,传统的【scripts/】角色会缩小。follow-builders需要JS脚本来做API调用和数据处理,因为这些是确定性逻辑。但frontend-slides的核心任务(生成HTML/CSS/JS代码)恰好是AI最擅长的事,不需要外部脚本来辅助。
4)第四层:知识层 — 4个文件的精妙分解
- 没有references/子目录,4个知识文件直接和SKILL.md平级放在根目录——因为Markdown的[file](file)链接语法在同级目录最简洁,减少路径出错的可能。
- 4个文件按关注点分离,各自回答一个不同维度的问题:
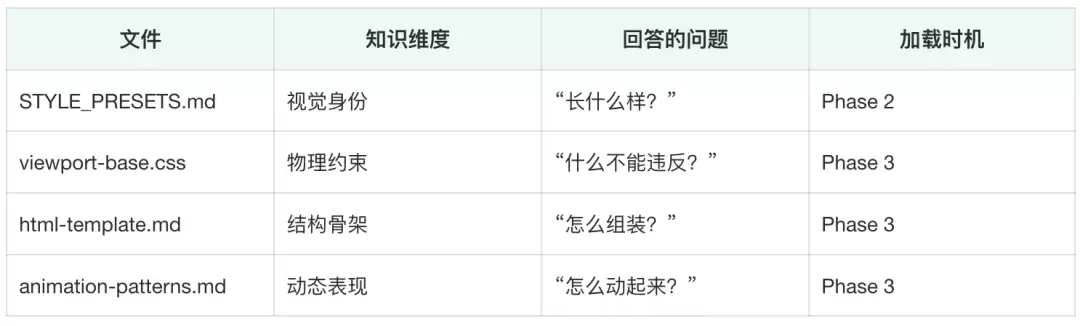

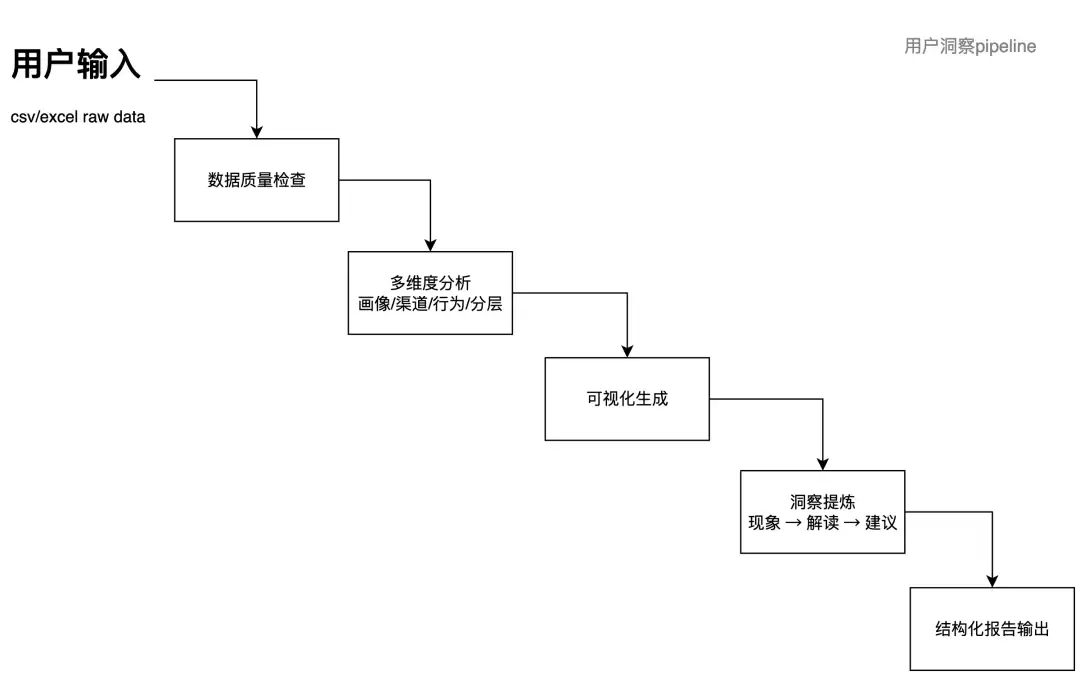
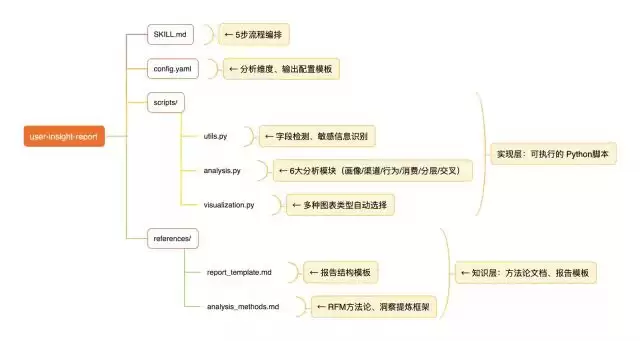
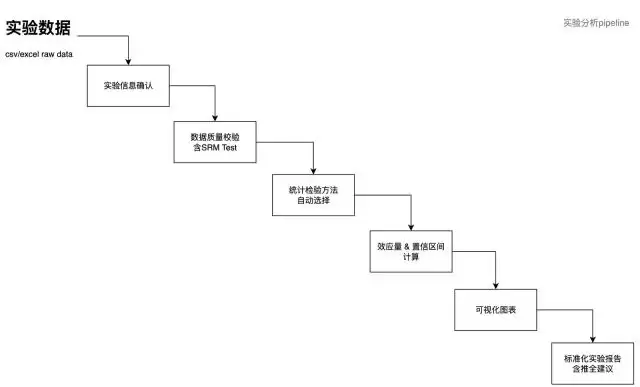
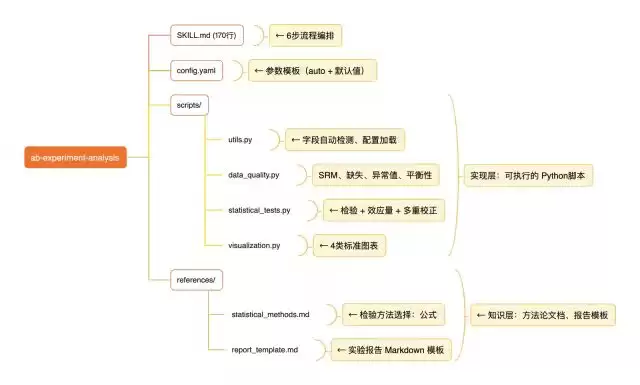


给代码不如给流程
- Agent本身很擅长写代码,但不擅长把控现实商业世界里的专业数据分析流程。
- SKILL.md的职责不是“怎么写Python”,而是“分析应该包含哪些步骤、关注哪些指标、注意哪些陷阱”,具体实现交给scripts/。
- 因此,SKILL.md的编写是重中之重,至于需不需要给scripts/,可以具体情况具体分析,但真的都还ok。
模板比自由发挥更可控
- 定义结构化输出的Schema,Skill一定要有能结构化输出的能力,没有Schema,Skill就会退化成和对话聊天一样的背景板
- 提供明确的报告模板,确保输出格式统一,减少Agent的随机发挥带来的不确定性。
config.yaml 是模板不是表单
- 所有和具体业务相关的值(实验名称、指标列表、字段名)都不应该写死在config里,而是用
auto或空值占位,运行时由检测逻辑或用户确认来填充。
控制篇幅,渐进式披露控制信息密度
- SKILL.md建议控制在500行以内(200行以内更佳)。信息太多反而会稀释重点。
- SKILL.md言简意赅,方法论细节放 references/,代码实现放 scripts/。这样Agent不会被信息过载。


▐关键收获
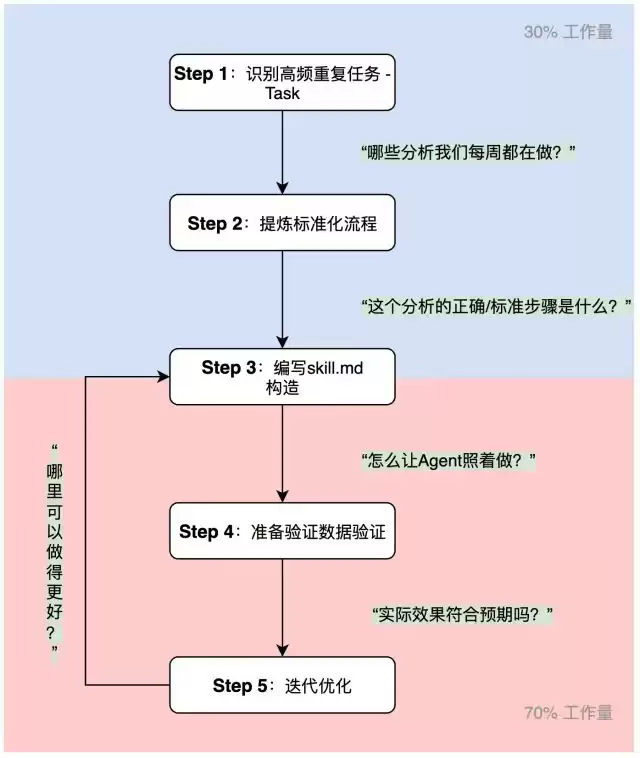
- 测试数据很重要,测试驱动开发:开发Skill时一定要用模拟数据跑通全流程,对Skill不断进行测试,发现其中的问题,进一步调整优化,这一步的工作可能占据了实际Skill开发的70%-80%。
- 产运视角 ≠ 数科视角:报告模板要考虑非专业背景用户的阅读体验。“p=0.023”对产运没有意义,“实验组GMV提升8%,建议推全”才是他们想看的。
- 工程化思维:Skill开发不是写一个Markdown文件的事,而是一套工程体系。config.yaml如何设计、scripts/如何拆分、SKILL.md如何引用——这些架构决策直接影响Skill的通用性和可维护性。
- Token消耗:对Skill进行调用测试验证的过程中,对于Token的消耗量极大,后续需要进一步思考如何在开发过程中节约成本。

