火山引擎豆包Seed2.1深度实测:一句话需求如何落地为可用的全栈系统
近日,火山引擎正式发布了豆包 Seed 2.1 系列,Pro 与 Turbo 两个版本同步上线。此次官方为其贴上的标签是:面向 Coding 与 Agent 时代的新一代深度思考模型。三大升级方向清晰明确——代码工程交付、Agent 长链路任务执行、多模态理解。
多年来,面对层出不穷的模型发布,我逐渐形成了一些固定习惯:先扫一眼 benchmark 数据,再比对价格,最后问自己一个实际问题——如果我扔给它一个真实项目,它能真正交付出来吗?
Benchmark 终究只是参考,真实工作流从来不是单点作战。你需要模型理解模糊的需求,拆解工程结构,生成可运行的代码,处理环境配置,修复 Bug,最终交付一个别人能直接使用的产品。这种端到端的交付能力,才是我们真正应当关注的核心。
因此,本次实测的思路很简单:只给 Seed2.1 Pro 一句粗糙到极致的需求描述,看看它能做到什么程度。
一、我们打造了一个生产级的论文工具
测试项目名为 paper-graph-manager,是一个论文图谱管理工具。需求只有一句话:“做一个论文图谱管理工具”。
这句话里没有任何技术栈说明、模块划分或边界条件。我们想验证 Seed2.1 Pro 能否从这一句话出发,独立完成以下任务:
- 理解什么是论文图谱管理
- 设计数据模型与存储架构
- 拆解为前后端分离的全栈系统
- 实现论文搜索、入库、智能标注、知识图谱、聊天、笔记六大核心模块
- 处理真实工程问题:环境配置、路径兼容、API 联调、Bug 修复
这本质上是一个从产品需求文档到可运行系统的完整交付链路。如果 Seed2.1 Pro 能稳定跑通这个链路,说明它的工程能力已不只是写代码片段,而是能理解需求并交付产品。
二、从需求到多模态:五个维度的能力实测
测试过程被整理为几个关键维度来评估。
1. 需求理解与产品需求文档生成
我们没有提供现成的产品需求文档。初始输入仅有一句话需求,外加几次简短对话补充。
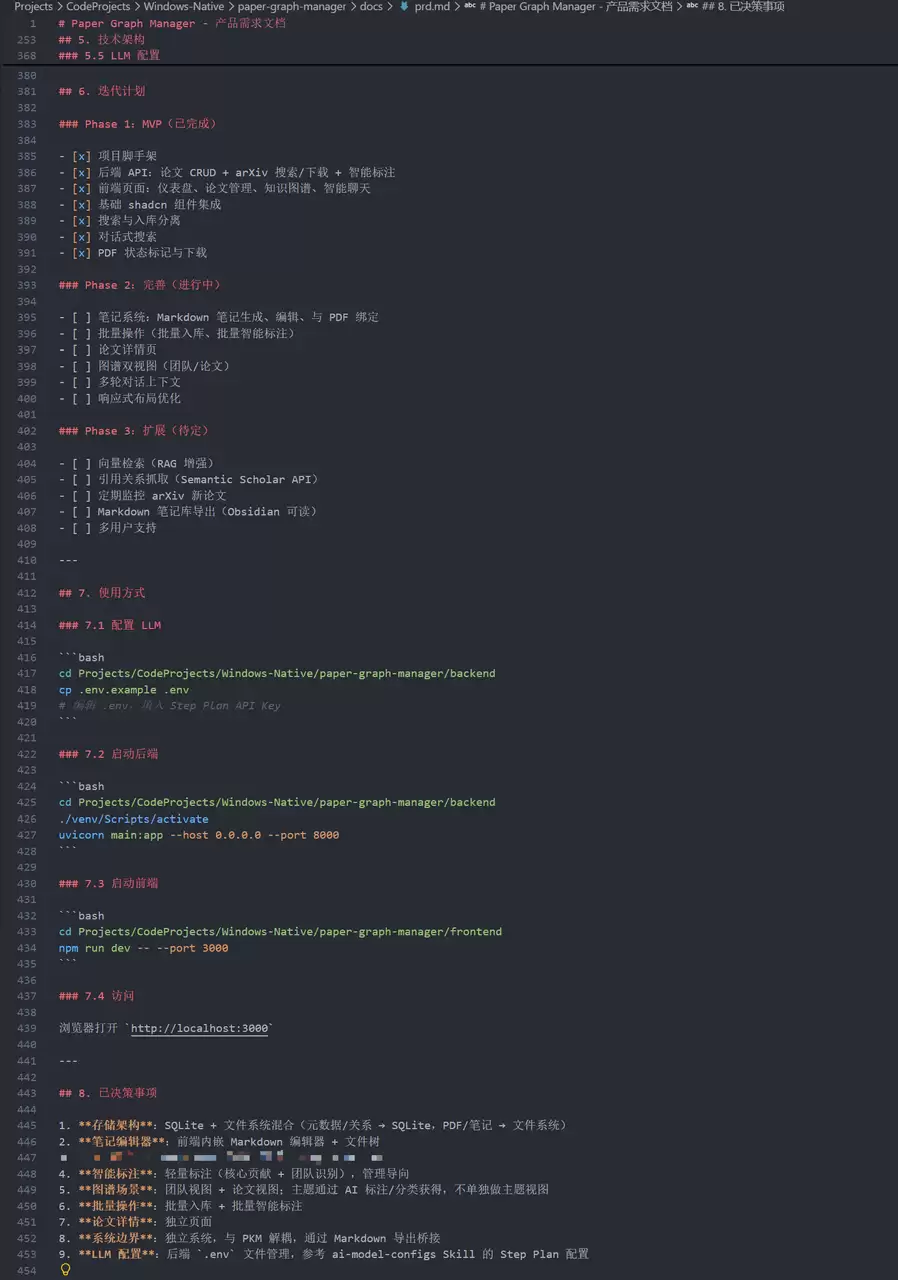
Seed2.1 Pro 第一次输出便是一份结构化的产品需求文档,覆盖了用户旅程地图、核心功能模块、数据模型、技术栈选型以及迭代计划。文档质量超出了预期:它不仅列出了要做什么,还解释了为什么做,以及为什么不做什么。
随后,我们与 Seed2.1 Pro 进行了多轮对话,用于校准这份文档。校准方式是用问题施压,而非替它写代码:
- 这个场景还缺少什么?是否有可优化的点?
- 如果数据量过大,如何处理?有无应对方案?
- 系统的边界条件是什么?是否需要预防?
每一轮对话后,Seed2.1 Pro 都会修正数据模型,补充缺失的模块,调整技术栈决策。最终产出的文档包含完整的全栈架构设计,可直接作为开发依据。
2. 代码工程交付
产品需求文档锁定后,进入全自动代码生成阶段。Seed2.1 Pro 按模块拆解了项目结构:
- 后端:FastAPI + Python 3.12 + SQLite
- 前端:React 19 + Vite 7 + TypeScript + shadcn/ui
- 图谱:NetworkX + react-force-graph-2d
- AI 能力:通过 OpenAI 兼容接口接入
它一次性生成了整个项目的目录骨架,包括后端入口、数据库操作、论文入库逻辑、智能标注模块、图谱构建、Markdown 笔记管理,以及前端的页面路由、API 服务层、UI 组件和交互逻辑。
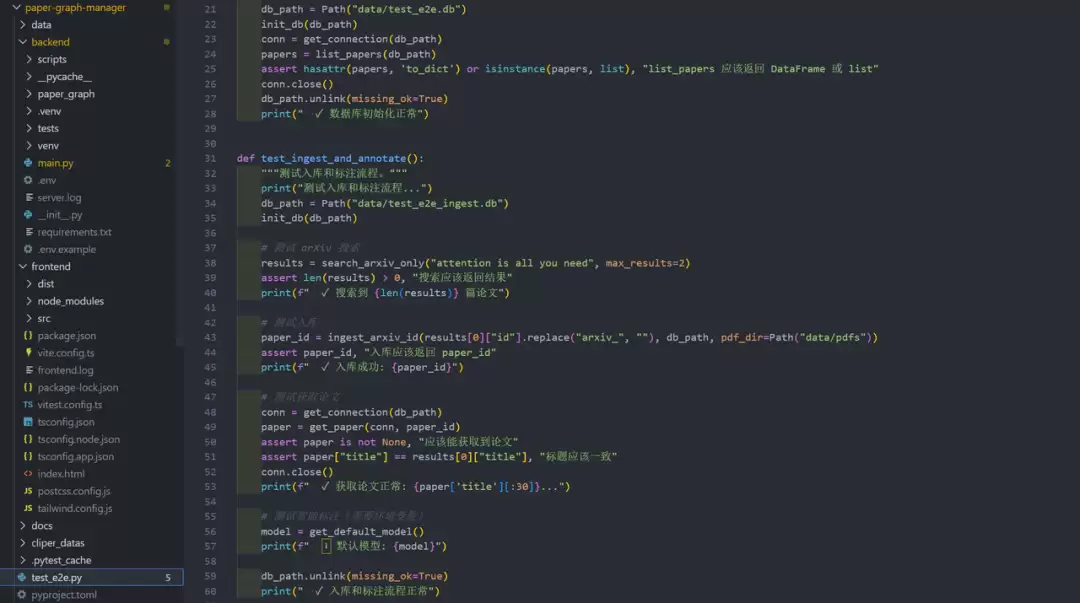
更关键的是,它生成了一个端到端测试脚本,覆盖了数据库初始化、论文搜索入库、图谱构建、笔记系统等核心流程。这意味着它写的代码是可验证的,而不仅仅是能跑起来的。
3. Agent 长链路执行
在整个过程中,Seed2.1 Pro 展现了强大的长链路任务执行能力。从一句话需求到可运行系统,中间经历了多次迭代:
- 需求澄清阶段:将模糊的表述替换为具体的约束
- 架构设计阶段:在多个技术方案之间做出选择并给出理由
- 实现阶段:按模块逐步生成代码,每完成一个模块就运行验证
- 修复阶段:环境配置问题、Windows 路径兼容、API 联调错误,全部由它自主修复
我们在代码层面几乎没有过多干预。我们的角色只是提出问题的人和验证结果的人,而非写代码的人。
4. 工具调用与外部集成
paper-graph-manager 需要调用 arXiv API 搜索论文、解析 PDF 元数据、构建知识图谱、生成 Markdown 笔记。这些涉及外部服务集成、数据格式转换和文件系统操作,绝非简单的函数调用。

Seed2.1 Pro 在处理这些集成时表现稳定。它自主选择了合适的 Python 生态库(PDF 解析、图谱网络分析等),设计了清晰的数据流,并在代码中预留了扩展点。
5. 多模态理解
虽然 paper-graph-manager 的核心是文本和图谱,但 Seed2.1 Pro 的多模态能力在项目中也有体现。例如,在智能标注模块中,模型需要理解论文标题、摘要、作者信息,从中提炼核心贡献并识别研究团队。这需要对文本信息的深度理解,而非简单的关键词匹配。
官方资料显示,Seed2.1 Pro 在 CharXiv-RQ(复杂文档理解)、ERQA(空间推理)、MMLongBench-128K(长上下文多模态)等基准上表现突出,这些能力在真实工程场景中得到了验证。
三、一个具体的交付物:paper-graph-manager
经过多轮对话和代码生成,Seed2.1 Pro 交付了一个完整的全栈系统。以下是它的主要能力。
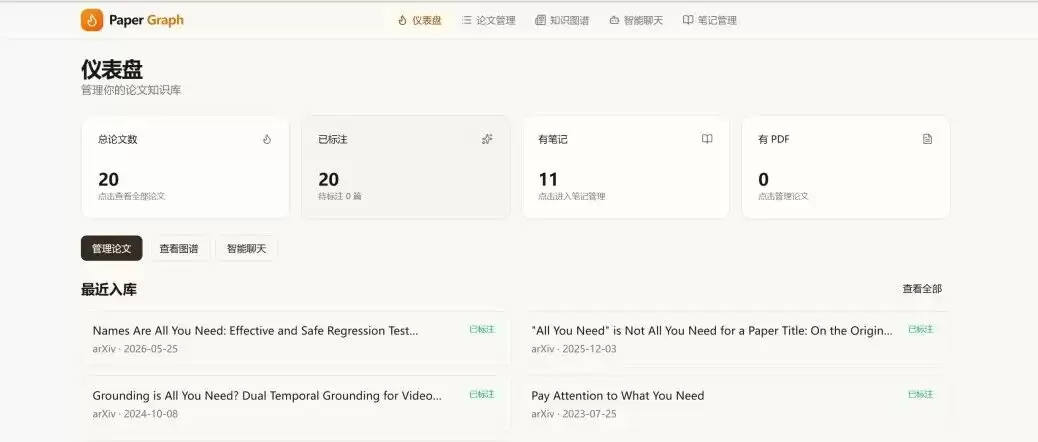
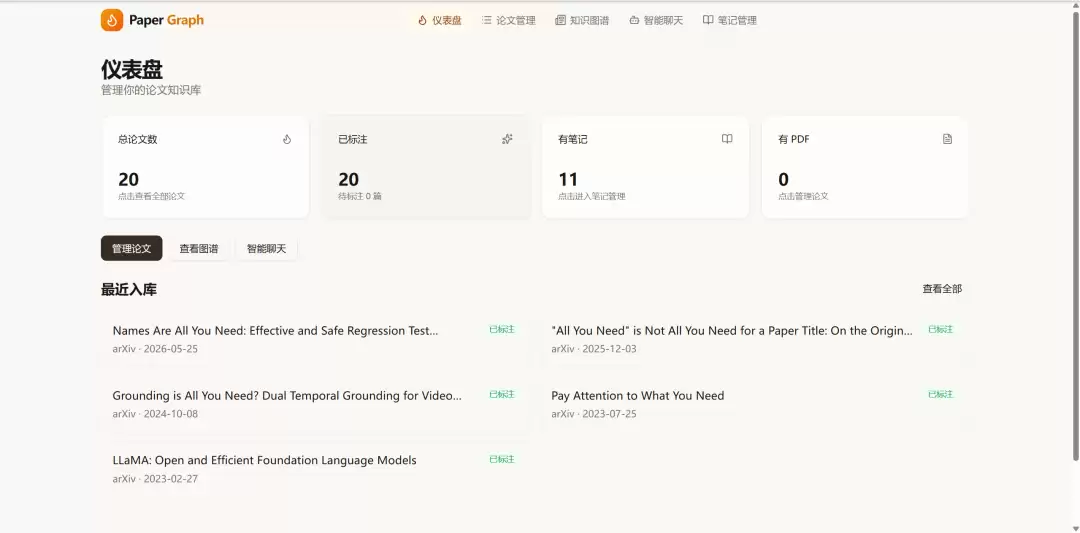
1. 仪表盘
首页展示论文库的全局统计:总论文数、已标注数量、有笔记的论文数、有 PDF 的论文数。最近入库的论文以卡片形式展示,标注状态一目了然。
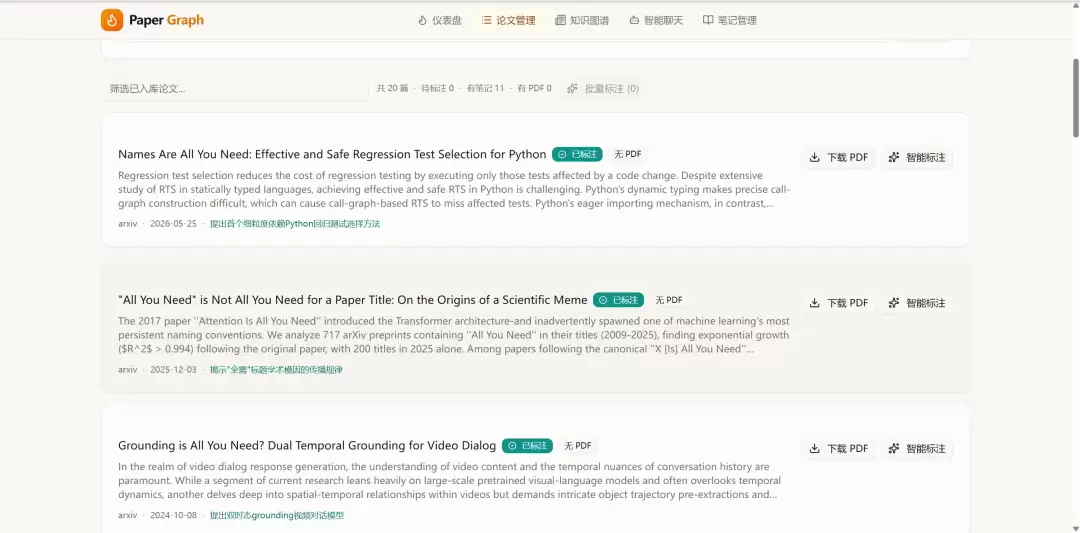
2. 论文管理
支持 arXiv 搜索、本地 PDF 上传、arXiv ID 直接入库。论文列表展示标题、摘要、发表日期、PDF 状态和标注状态。用户可以逐篇点击入库,也可批量处理。
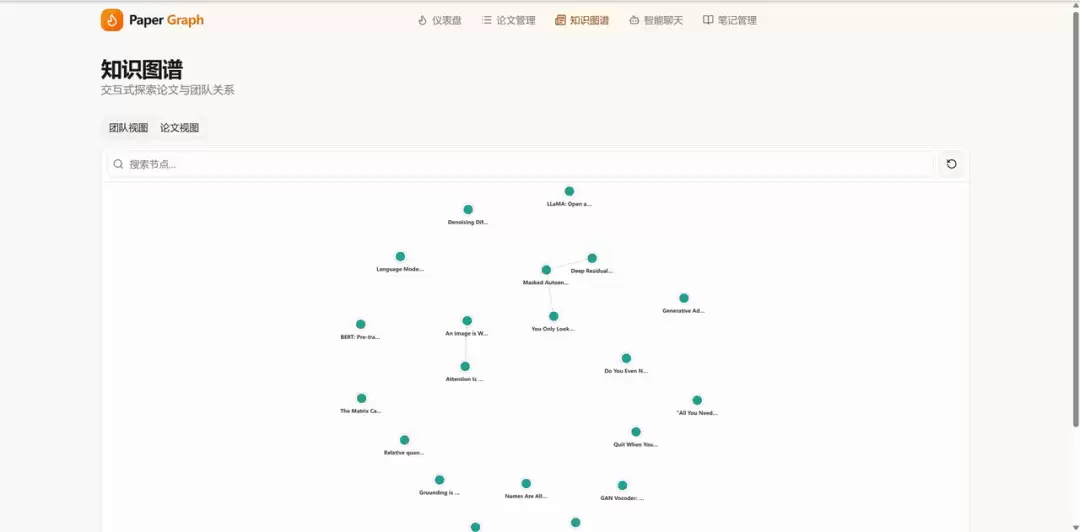
3. 知识图谱
提供团队视图和论文视图两种图谱模式。团队视图以研究团队为节点,共著论文为边;论文视图以论文为节点,共享作者为边。支持拖拽、缩放、搜索和点击查看详情。
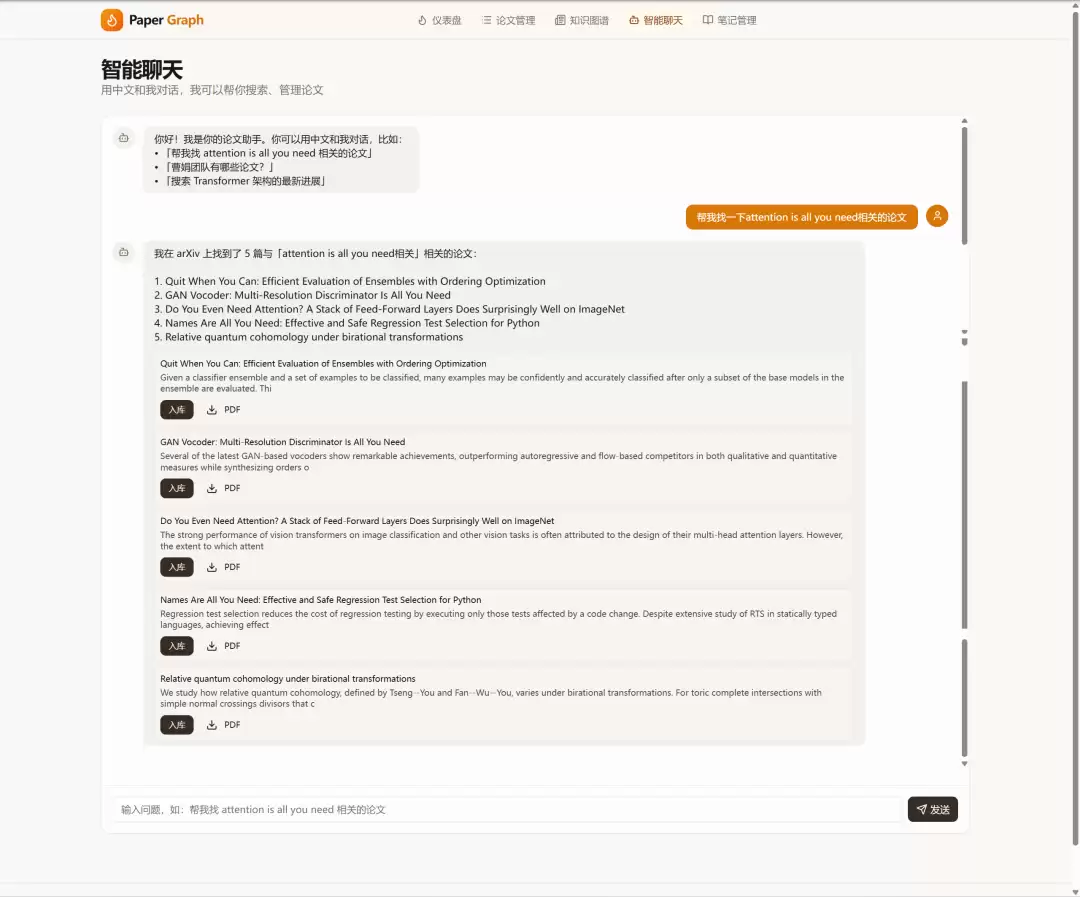
4. 智能聊天
用户可以用中文与系统对话。系统支持三种模式:对话式搜索 arXiv、结构化查询本地论文库、基于摘要匹配的 RAG 检索。聊天结果以论文卡片形式展示,支持一键入库和 PDF 下载。
5. 笔记系统
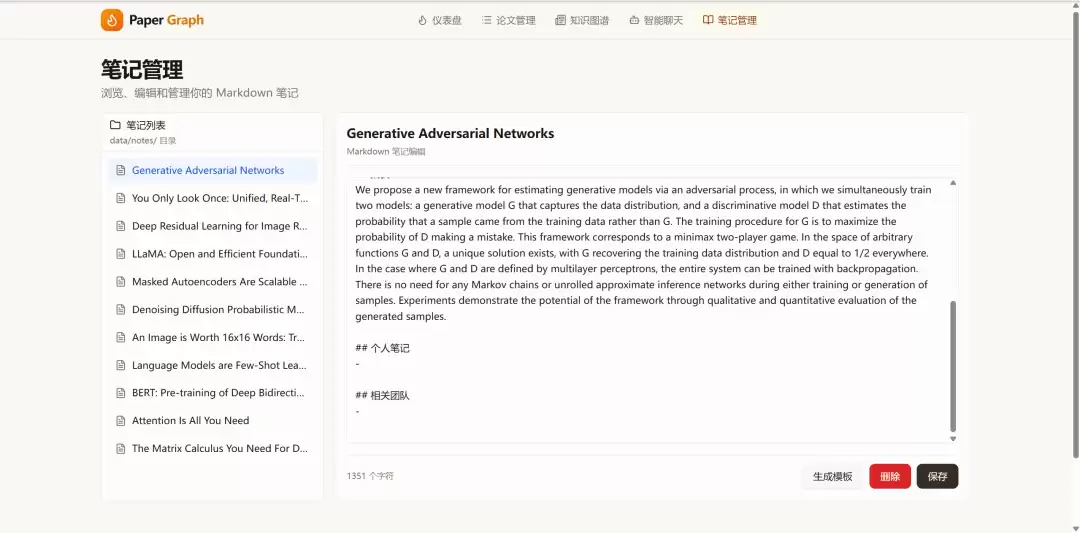
入库时自动生成 Markdown 笔记模板,包含 frontmatter 元数据。笔记与 PDF 路径绑定,支持 [[wikilink]] 关联其他笔记和论文,可一键导出为 Obsidian 可读的笔记库。
6. 智能标注
这是整个系统的 AI 核心。Seed2.1 Pro 对每篇论文执行两项任务:用一句话提炼核心贡献,从作者和机构信息中识别研究团队。标注结果写入 SQLite 数据库,用于知识图谱构建和论文管理。
四、我们是怎么和 Seed 2.1 对话的
很多人问,是怎么把一句话需求变成全栈系统的?核心方法其实很简单:不要给精致的需求文档,要给粗糙的需求。
初始输入只有一句话:做一个论文图谱管理工具。不是一份几十页的产品需求文档。
然后和 Seed2.1 Pro 进入一个校准循环:
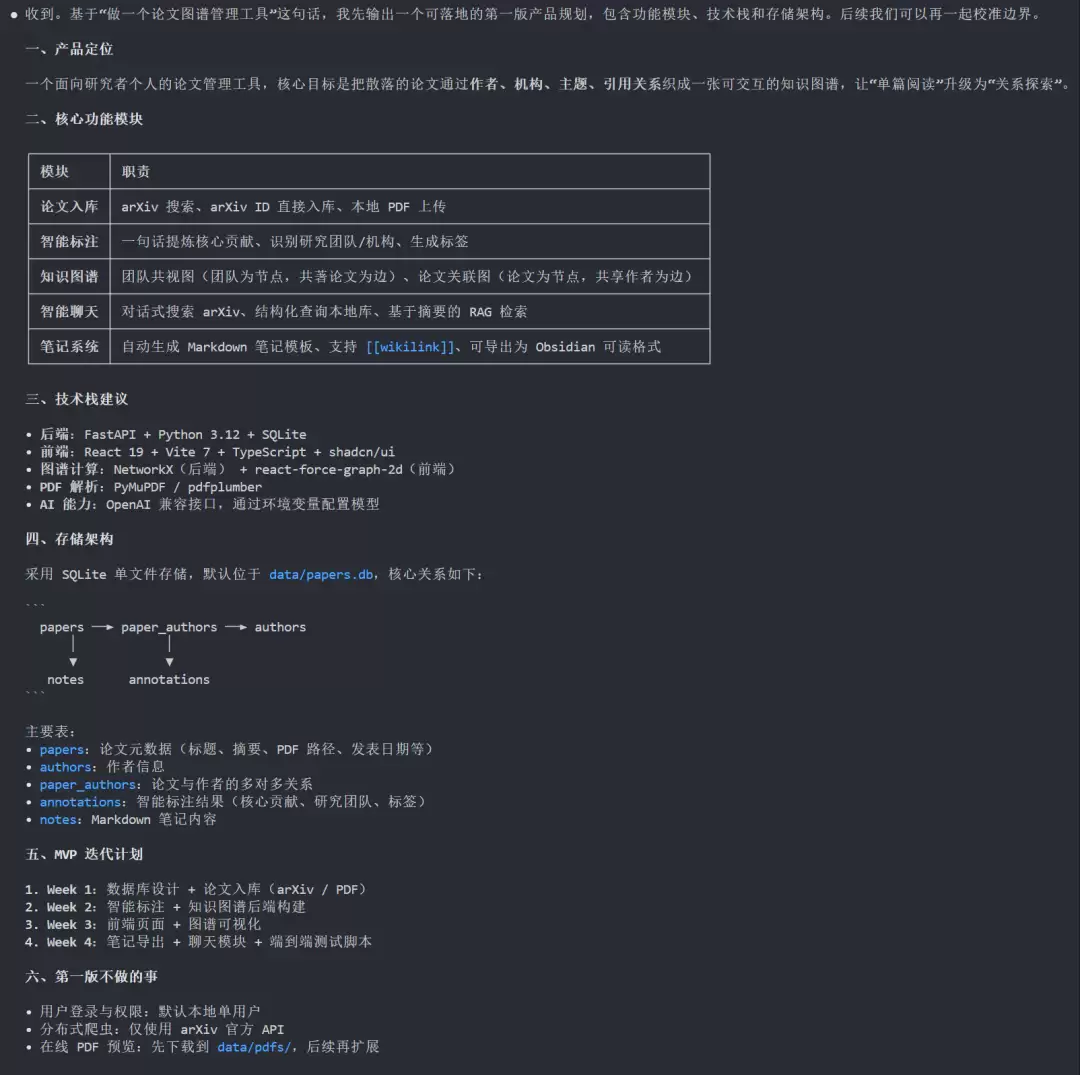
第一步:让它先出结构。基于一句话需求输出初步的产品规划。它给出了功能模块划分、技术栈建议和存储架构设计。
第二步:用问题驱动。不替它写代码,只提问题:pdf 解析用什么?arXiv API 限流了怎么办?数据量到了一万条会有问题吗?这些问题会迫使它补充边界条件。
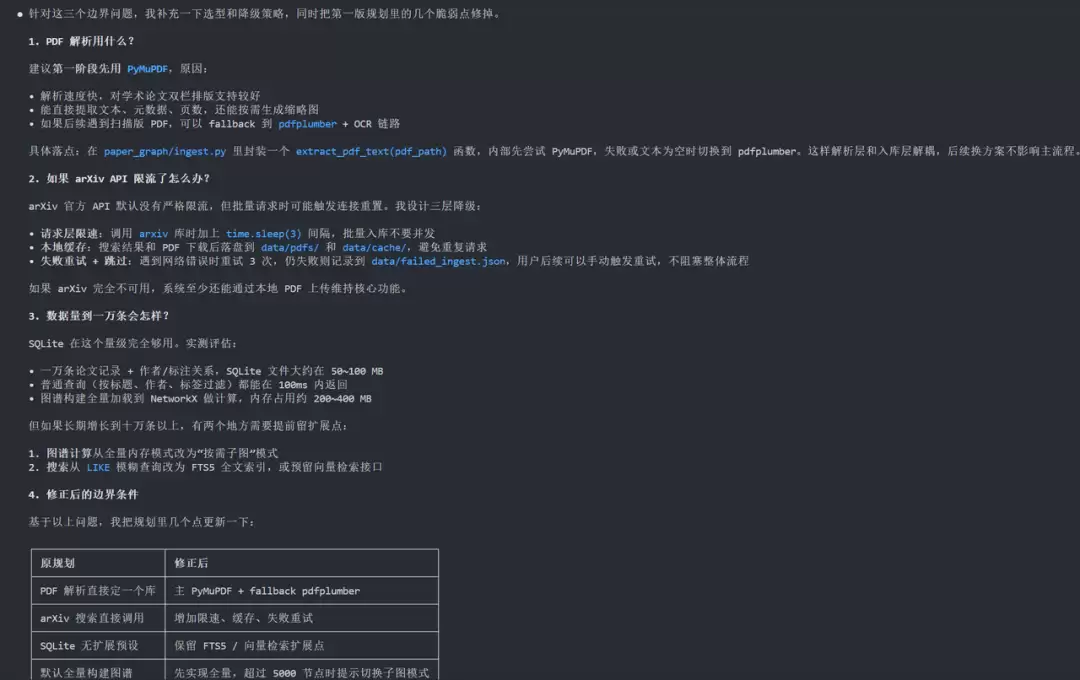
第三步:只做删减和合并。当它的设计过于复杂时,没有重写,只是说这个模块先不做,或者把这两个功能合并。它会在下一轮输出中自动修正。
第四步:每完成一个模块,立即运行验证。代码生成后,跑测试脚本,把报错信息原样复制或者让它自己去读取修正。这种生成-验证-修复的循环,比一次性写完再调试效率高得多。
在这个过程中,我们逐渐发现了 Seed2.1 Pro 的几个特点:
- 擅长从模糊需求中提取结构化信息
- 能在对话中保持上下文,记住之前的决策
- 会主动给出技术选型的理由,而不是随便选一个
- 遇到环境问题时,能根据报错信息自主修复
五、和 Seed 2.1 协作,五条经验总结
和 Seed2.1 Pro 做项目的过程中,我们摸索出几个与 AI 协作的习惯,不限于这个项目,其他模型和场景也适用:
给粗糙的需求,不要给精致的需求文档。你给的需求越粗糙,模型的自主性越强,你越能观察到它的真实能力。如果你的需求文档都写好了,那测试对象就从模型变成了你的文档能力。
用“这个场景缺少什么”让它去思考。这句话比“我觉得这里有问题”更有效。它迫使模型主动思考边界条件,而不是被动接受批评。
让模型先出结构,人类只做删减。不要替它写代码。你的角色是产品经理,不是程序员。如果它设计的架构有问题,删掉或合并,让它自己去修正。
每完成一个模块,立即运行。不要等全部写完再调试。越早暴露问题,修复成本越低。把报错信息原样喂回去,比描述问题更有效。
记录关键对话。产品需求文档经过了十几轮对话迭代。这些对话本身就是评估模型能力的重要数据。哪些地方它理解错了?哪些地方它主动提出了更好的方案?这些记录比最终代码更有价值。
六、回到 Seed 2.1 本身
经过这个项目的实际使用,我们对 Seed2.1 Pro 的能力有了更具体的感知。
在代码工程方面,Seed2.1 Pro 展现了端到端的交付能力。从需求理解到功能实现,从 Bug 修复到环境搭建,形成了一个相对完整的交付闭环。这种系统性理解和执行能力,超出了简单的代码补全。
在 Agent 能力方面,Seed2.1 Pro 能够在多轮对话中保持任务一致性,并根据用户的反馈持续修正输出。对话跨度从需求澄清到代码调试,始终保持在同一个任务上下文中,没有出现明显的上下文丢失。
在多模态理解方面,虽然 paper-graph-manager 的核心场景是文本处理,但 Seed2.1 Pro 对论文元数据的理解深度超出了预期。不仅能准确提取标题和摘要,还能识别研究团队和研究方向,这对后续的知识图谱构建至关重要。
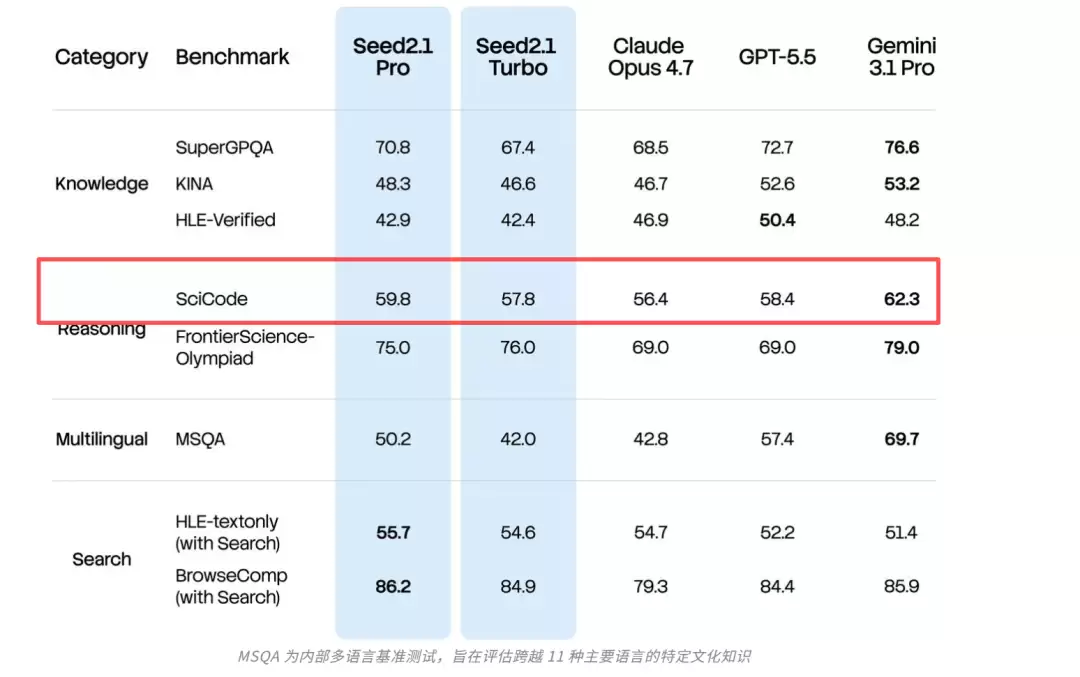
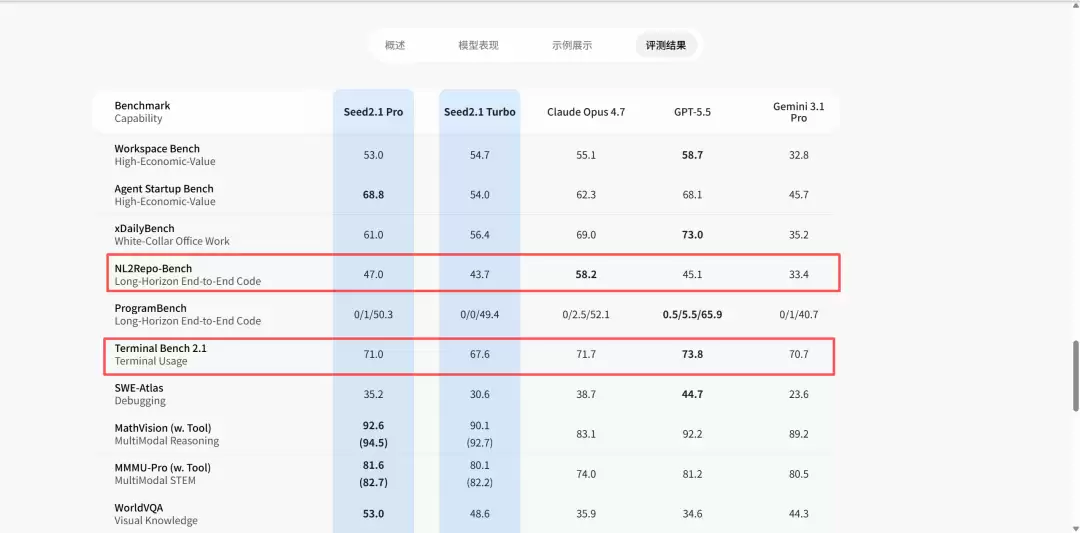
官方发布的 benchmark 数据显示,Seed2.1 Pro 在 TerminalBench 2.1 上得分 71.0,接近 GPT-5.5 的 73.8;在 NL2Repo-Bench 上得分 47.0,高于 GPT-5.5 的 45.1;在 SciCode 上得分 59.8,反超 GPT-5.5 的 58.4。这些数字在实际测试中得到了印证,因为它还能驱动浏览器帮我们完成测试。
价格方面,Seed2.1 Pro 的输入价格为 6 元/百万 tokens,输出价格为 30 元/百万 tokens;Turbo 版本直接减半。对于一个需要大量 API 调用的工程项目来说,这个定价对比 GPT 和 Anthropic 家动辄几十美元的价格,还是比较有竞争力的。
七、写在最后
做这个测评,是想回答一个更实际的问题:当把一个真实项目交给 AI 的时候,到底在多大程度上可以信任它?不是要给 Seed2.1 Pro 打一个分数。
经过 paper-graph-manager 这个项目的实践,答案是:在代码工程和 Agent 执行这两个维度上,Seed2.1 Pro 已经达到了可以信任的水平。可以把粗糙需求扔给它,它会给你一个结构化的方案;可以让它写代码,它会生成可运行的全栈系统;可以在对话中持续修正方向,它会跟着你的节奏调整输出。
当然,它还不是完美的。有些地方需要手动介入,有些细节需要反复调试,有些架构决策我们可以做得更好。但这些不完美恰恰是真实使用场景的一部分。我们看重的不是 benchmark 上的数字,而是它在真实场景中的交付能力。
如果你也在用 Seed 2.1,欢迎在评论区分享你的使用体验。