TL;DR
- 提示词并非静态配置文件。每新增一条指令,都会悄然改变它在所有已有查询类型上的行为表现。
- 多数团队只有在用户反馈错误时,才意识到提示词出了问题。本文将详细讲解如何为提示词搭建一套完整的测试套件。
- 该套件利用40条黄金查询,对四个提示词版本执行测试,配合四个确定性验证环节来校验输出,并能够精准识别"假性改进"模式——即总体准确率看似上升,但某个关键类别的表现却急剧恶化。
- v4版本,也就是那个总体准确率高达67.5%的"最优"提示词,由于否定分类能力骤降66.7%,被明确标记为"假性改进"(FALSE IMPROVEMENT)。
- 零外部依赖。纯Python代码实现。单次运行耗时不足两秒。
先分享一段亲身经历。RAG查询层原本运行稳定,后来为了处理PDF和策略文档,新增了文档路由指令,提示词从6条扩展到了14条。随手测试了几个案例,看似一切正常,便直接上线了。
三周后,在追踪一个支持工单时发现,否定类查询(例如"哪些产品不在保修范围内?")被错误地归类为普通策略查询,而非专门的否定检查。令人困惑的是,分类逻辑和路由代码从未被修改过。唯一变化的,只有系统提示词。
这让我恍然大悟:我一直把提示词当作静态配置文件来使用。但事实并非如此。提示词本质上是一个随机API,每添加一条指令,就相当于修改了它处理所有查询类型的API合约,而不仅仅是你心中所想的那几种。
软件工程领域早已为这类问题给出了解决方案:回归测试套件。逻辑非常朴素:任何改动上线之前,先跑一遍测试。原本通过的用例现在失败了,那就不能上线。遗憾的是,我在提示词上从未建立这套机制。绝大多数团队也都没有。
这一思路与测试驱动开发(Beck [5])的核心理念高度一致:在实施改动之前,先清晰地定义期望的行为。这种纪律迫使你在触碰代码之前,就明确何为正确的行为。应用到提示词上,就是在添加新指令之前,先为每个类别定义好有效的分类逻辑。缺乏这些定义,你根本无法判断一次改动是否会悄无声息地破坏你未曾预料的部分。
这种隐藏成本在机器学习系统中同样普遍存在。Sculley等人 [4] 曾指出,未声明的依赖和不稳定的数据接口,会在生产环境的ML流水线中积累成技术债务。提示词在未被察觉的情况下,悄悄改变各类别的行为,正属于这一范畴——从外部看接口似乎稳定,但内部行为早已偏离正轨。
以下数据均基于Python 3.12、Windows 11、纯CPU环境的真实运行结果。
代码仓库:https://github.com/Emmimal/prompt-regression-suite
基本设定
这个回归测试套件在40条黄金查询上,对四个提示词版本进行测试,覆盖六个意图类别,构建于一个RAG意图分类系统 [1] 之上。这四个版本反映了一个真实的迭代演进过程:每个改动都有看似合理的理由,但每个改动也引入了新的隐藏问题。
v1是基准版本。它使用最简指令和零推理步骤来处理纯粹的意图分类,仅包含一条保持简洁的规则和一条规定JSON输出格式的规则。
v2加入了思维链推理。之所以添加这一功能,是因为像"企业级付费方案的P1工单在非工作时间的响应时间"这类多跳查询经常被错误分类。研究表明,思维链能显著提升复杂推理任务的性能 [2],它也的确解决了那个具体问题。但问题在于全局应用。v2版本的提示词先要求模型"保持简洁",紧接着又要求"一步一步推理"。这两条规则在处理任何简单查询时相互矛盾。
v3加入了文档路由。新指令要求模型在分类意图之前,先检查表格、策略和PDF信号。其中一条指令"在意图分类之前优先进行文档路由"直接干扰了否定句的处理。像"哪些区域被排除在快递政策之外?"这样的否定查询包含策略关键词,在v3版本下,模型会先解析文档类型,意图处理的逻辑根本不会触发。
v4将前两者的改动合并在一起,这也成为最终上线的提示词。指令总量大约增加了三倍,v2和v3版本中的隐性冲突开始叠加放大。
黄金查询集
40条查询分布在六个类别中。
| 类别 | 数量 | 针对的失败模式 |
|---|---|---|
| simple_intent | 10 | 过度推理噪声 |
| comparison | 8 | 缺少比较锚点 |
| aggregation | 6 | 数字范围坍缩 |
| negation | 6 | 指令冲突 |
| multi_hop | 6 | 受益于思维链 |
| edge_ambiguous | 4 | 虚假自信 |
| 总计 | 40 |
每条查询都经过精心筛选,目的是暴露某种特定的失败模式,而非追求通用代表性。以比较类别为例,它是这个系统中一个已知的短板——比较查询需要一个比较锚点,但当前提示词架构无法解析它。这份基准测试没有回避这一事实,你会在每份差异报告中看到[已知失败]的标注。
每条查询并不依赖于一个硬编码的参考答案,而是带有一个验证签名:一组确定性约束条件。
{"id": "NQ_01","query": "哪些产品不在保修政策覆盖范围内?","category": "negation","expected_intent": "negation_check","expected_schema_keys": ["intent", "confidence", "query_type", "rewritten_query"],"expected_patterns": ["not covered", "warranty"],"must_not_contain": ["I cannot", "As an AI"],"failure_mode": "instruction_conflict"}
failure_mode字段不仅仅是用于文档记录,它本身是一个可测试的断言。如果提示词存在阻止否定句处理的指令冲突,这条查询就会失败,而失败模式标签会直接指引你排查方向。
验证器
QueryValidator类对每条输出执行四个确定性检查。没有LLM作为裁判,也没有任何主观的质量评分。
class QueryValidator:def validate(self, output: dict, query: dict) -> ValidationResult:# 1. 模式检查:输出字典中是否存在必要字段schema_failures = [k for k in expected_keys if k not in output]schema_pass = len(schema_failures) == 0# 2. 模式检查:输出文本中是否含有期望模式output_text = " ".join(str(v) for v in output.values()).lower()pattern_failures = [p for p in expected_patternsif not re.search(re.escape(p.lower()), output_text)]pattern_pass = len(pattern_failures) == 0# 3. 意图检查:分类出的意图是否与预期标签一致detected_intent = output.get("intent", "")intent_pass = detected_intent == expected_intent# 4. 守卫检查:不应出现的内容是否确实缺席guard_violations = [g for g in must_not_contain if g.lower() in output_text]guard_pass = len(guard_violations) == 0
一条查询要么通过全部四项检查,要么就算失败。没有部分得分或复杂加权,更不会有裁判模型在多次运行间引入方差。类别得分就是简单的通过数 / 总数。相同的输入,永远输出相同的结果。
完全绕过了LLM-as-a-judge这条路。老实说,这里需要阐明一个关键点:回归测试本质上不是一个"质量"问题,而是一个"合约"问题。检查输出意图是否匹配预期意图是一个二元判断,使用裁判模型只会引入噪声。况且,每次对提示词做一个小改动,就运行一次LLM裁判去评估40条查询,成本会迅速攀升。而这个脚本在两秒内就能完成,成本为零。
评分器与假性改进检测
Scorer类计算每个类别的准确率,然后做另一件更重要的事——这才是这个系统的核心价值所在。
REGRESSION_THRESHOLD = 0.10CRITICAL_CATEGORIES = {"simple_intent", "negation"}# 假性改进检测overall_improved = candidate.overall_score > baseline.overall_scoreif overall_improved and critical_regressions:candidate.false_improvement_detected = Truecandidate.false_improvement_reason = (f"总体得分提升了 "f"{(candidate.overall_score - baseline.overall_score) * 100:.1f}% "f",但关键类别出现回归: [{cats}]")
假性改进模式是这样的:一次提示词改动提升了总体准确率,但同时导致某个关键类别的表现崩溃。总体指标看起来不错,数据涨了,于是你就上线了。但其实这个提示词已经坏了。
CRITICAL_CATEGORIES是一个与系统相关的设计决策。对于我的意图分类器来说,simple_intent和negation是关键类别,因为它们代表了绝大多数真实流量。多跳查询虽然重要,但相对少见。一个不常出现的查询类型获得了100%提升,这完全不能为常用类别上66.7%的暴跌开脱。正如在支付流程中,应该先写集成测试再写单元测试:优先保护那些对用户影响最大的关键路径。
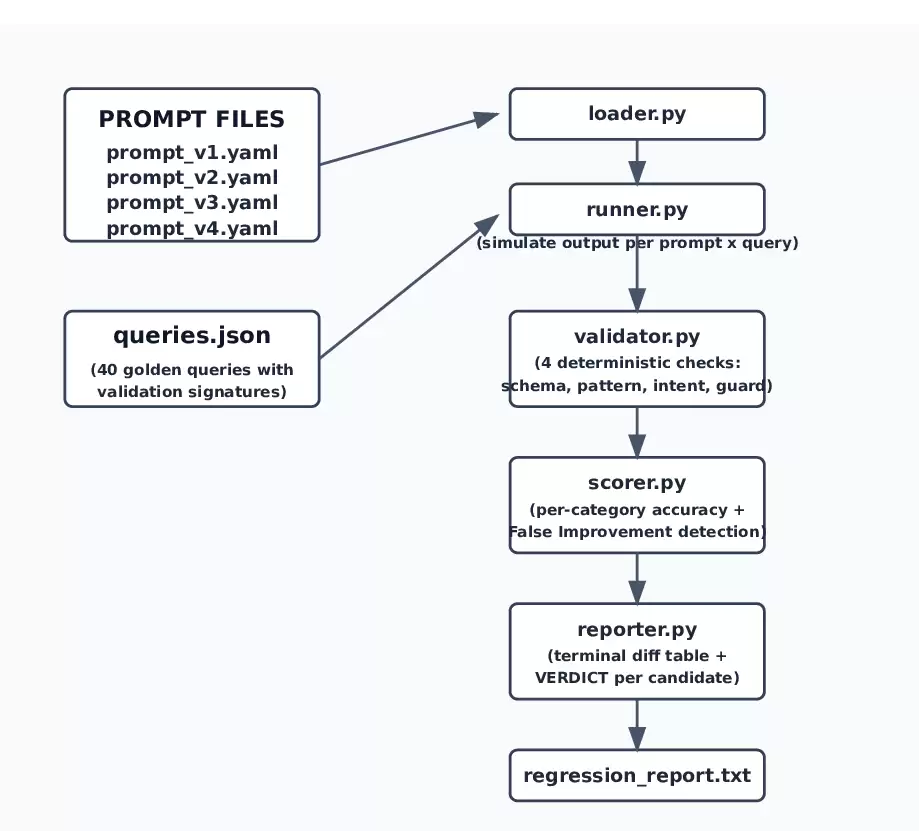
确定性模拟器
这个套件使用一个确定性的模拟器来代替真实的LLM调用。这是整个代码库中最关键的一个架构决策,值得单独说明。
这个模拟器不产生随机输出。每个失败函数都模拟了由对应提示词版本中某个特定指令冲突所引发的、具体的、真实的失败模式。
def simulate_output(prompt_version: str, query: dict) -> dict:# v2 + simple_intent → CoT侵入rewritten_query,触发守卫检查if version == "v2" and category == "simple_intent":return _overreasoning_noise(query)# v3 + negation → 文档路由在意图解析前截胡if version == "v3" and category == "negation":if query_number in (1, 3, 5):return _instruction_conflict_moderate(query)# v4 + negation → 两种冲突叠加,意图被误判为ambiguousif version == "v4" and category == "negation":if query_number in (1, 2, 4, 5):return _instruction_conflict_severe(query)
_instruction_conflict_severe函数会产生"intent": "ambiguous",而正确的结果应该是"negation_check"。置信度掉到0.39。重写后的查询里混入了CoT噪声:"第一步:扫描文档类型信号... 第二步:检测到否定关键词,但文档路由优先级更高... 第三步:因此,在文档上下文确认之前,将其归类为歧义。"
这个输出在意图检查上失败(意图错误),模式检查上失败(缺少否定模式),守卫检查上失败(包含CoT步骤词元)。一条输出导致三项检查不通过,这就是基准测试中v4版本下否定类别66.7%崩溃的真相——6条否定查询中有4条失败。
在确定性模拟和真实LLM调用之间做选择,完全取决于你想测量什么。回归测试并不是质量评估。质量评估问的是"输出好不好",回归测试问的是"改动有没有破坏原先能用的功能"。这是两个完全不同的问题,需要不同的工具。
LLM-as-a-judge在质量评估上效果很好,因为它能处理开放性输出 [3],而这正是确定性指标的短板。但回归测试要求绝对的确定性。如果你的测试结果在多次运行间有波动,你就没法把真正的提示词回归和背景噪声区分开。确定性模拟器每次运行产生完全相同的结果,这是它的一大特点,而非限制。
两种方法可以互补。每次提交提示词改动前先跑这个回归套件,拦截结构性破坏;然后定期运行LLM-as-a-judge评估,来审查那些代码检查无法捕捉的开放性问题。
由于避免了实时API调用,运行python run_regression.py无论谁克隆仓库,每次都会得到完全相同的数字。消除了模型方差、供应商侧更新和不必要的API费用。对于一个回归测试框架来说,可复现性才是唯一重要的指标。
基准测试结果
各提示词版本的类别得分
| 类别 | v1 | v2 | v3 | v4 |
|---|---|---|---|---|
| simple_intent | 100.0% | 40.0% | 80.0% | 90.0% |
| negation | 100.0% | 66.7% | 50.0% | 33.3% |
| aggregation | 100.0% | 100.0% | 100.0% | 100.0% |
| multi_hop | 0.0% | 100.0% | 100.0% | 100.0% |
| comparison | 0.0% | 0.0% | 0.0% | 0.0% |
| edge_ambiguous | 25.0% | 100.0% | 100.0% | 100.0% |
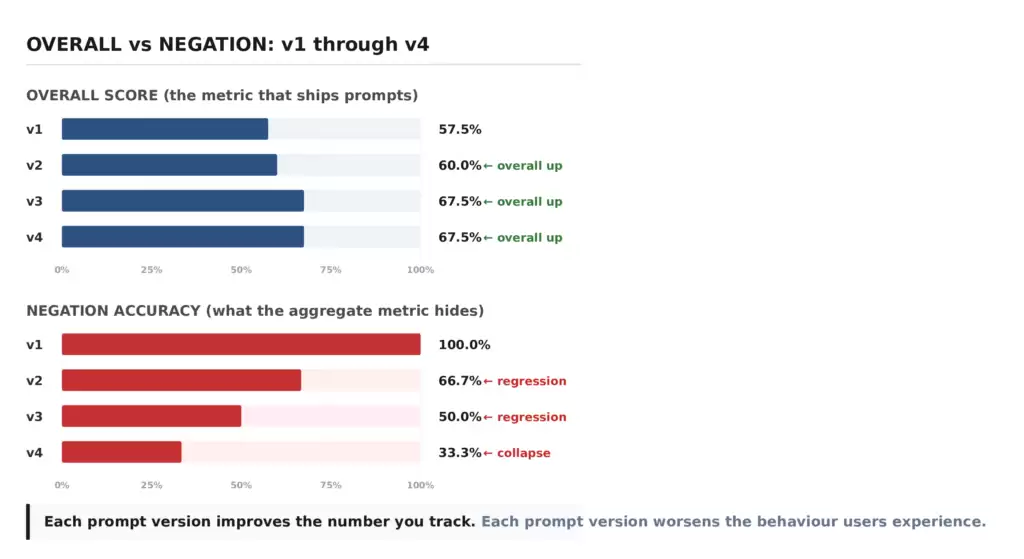
| 总体 | 57.5% | 60.0% | 67.5% | 67.5% |
正是"总体"这一行,让提示词被决策上线。v4和v3并列67.5%,都高于v1基准的57.5%。单看这个指标,v4就是你最好的提示词。但按照回归套件的标准来看,v4是一个有问题的提示词。
判決:v1 → v4⚠假性改进检测到总体得分提升了10.0%,但关键类别出现回归:[negation]关键回归:• negation 100.0% → 33.3%▼ 66.7%失败模式:instruction_conflict状态:✗不允许推送到生产环境
v2和v3也触发了同样的判定。三个候选版本都出现了假性改进检测。三个版本相比基准都有总体提升。三个版本都有关键类别崩溃。
每个版本实际做了什么
下面这张图展示了三个候选版本中的回归级联过程。

多跳准确率正好说明了问题。v1基准在这个类别上得了0.0%。没有思维链,复杂的条件查询(需要按顺序解析三个或更多条件的那些)会被错误地分类为fact_retrieval。模型无法在没有明确推理框架的情况下并行处理这些条件。CoT彻底解决了这个问题,让v2、v3和v4都达到了100.0%。
思维链对于要解决的特定问题来说,是对的修正。错就错在全盘应用。那条修复了条件推理链的指令,同时也导致模型对简单查询过度解释,用一步步的噪声污染了rewritten_query字段。如果采用条件式CoT(仅在query_type == "complex"时应用推理),就能在不破坏简单意图的情况下修复多跳问题。没有回归测试套件,你根本没机会在用户反馈之前发现这个问题。
假性改进模式的可视化
这不是故意构造的极端案例。这是持续对提示词进行迭代优化、却不追踪类别级别准确率的必然结果。每次改动都解决了一个真实问题。每次改动也都在总体指标下面藏了笔真实成本。
架构图
坦诚的设计决策
loader.py中的YAML解析器是一个最小化的手写解析器,负责处理字符串字段和多行块标量。没有引入PyYAML——为一个应该是可审计、易克隆的框架增加依赖,这不是个好的权衡。如果你确实需要在提示词文件中使用YAML锚点或别名,换成PyYAML也不过是一行代码的事。
确定性模拟器产生的是受控的性能退化,而不是随机噪声。每个提示词版本下具体哪些查询会失败,都反映了我生产系统中真实的失败模式。一个不同的系统,自然会有不同的指令冲突和完全不同的失败点。这个框架是可移植的,但其中的退化模型不行。你需要根据自己提示词历史中实际存在的冲突,来编写你自己的模拟器。
10%的回归阈值是随意定的。选它只是因为在一个确定性系统里,这是能明确排除测量噪声的最小变化。对于一个医疗分诊系统来说,urgent_symptom分类至关重要,那我就会设成5%。对于一个低风险的推荐系统,15%可能也能接受。阈值是一个参数,不是一个原则。
比较类别在全部四个提示词版本中得分都是0.0%。这是当前提示词架构中一个已知的缺陷,并非由这四个版本中的任何一个所引入。意图分类器缺少一个比较锚点解析步骤,因此需要跨共享属性比较两个实体的查询就会稳定失败。我没有把它隐藏起来或排除在基准测试之外。它出现在每份差异报告中,并带有[已知失败]标注。一个生产级的回归套件,应该能区分已知的、被追踪的失败和新引入的回归问题。这个基准测试明确了这一点。
CRITICAL_CATEGORIES目前覆盖了simple_intent和negation。要新增一个关键类别,只需要一行代码和相应的黄金查询集。这个框架并不假设这两个类别对所有人都同样重要:它们对我的特定系统来说很重要。
如何在你的系统里应用
验证器和评分器是与系统无关的。下面是一个最小可行版本——刚好能在"假性改进"上线前把它揪出来。
从20条黄金查询开始,分到两个类别里。选择处理你系统里最大流量的两个类型,每个写10条查询。关键在于,对每条查询,在写输入之前先定义好它的验证签名。强制自己明确"正确行为应该是什么样",这能帮你选出真正合理的测试用例。如果你连签名都写不出来,说明你还没真正理解你的提示词应该怎么处理这类查询。
定义两个CRITICAL_CATEGORIES。这些是那些一旦出现回归,就要自动阻止上线的细分领域。对于客服机器人来说,可能是退款资格和升级工单触发;对于医疗分诊系统,可能是紧急症状分类。"关键"的定义完全取决于你的系统,这个框架不会对你的需求做任何假设。
在每次提示词改动之前运行这些测试,而不是之后。遵循Beck [5] 描述的纪律:在代码上线前运行套件,而不是等到用户报告了失败才跑。整个套件跑完不到两秒,没有任何操作上的理由能让你拖延它。
每出现一个线上bug,就扩展你的黄金集。每当有用户报告一个误分类case,就把那条查询连同它的验证签名加到黄金集里。久而久之,黄金集就会成为你提示词整个历史失败面的全面档案。
根据失败的影响来调整CRITICAL_CATEGORIES的阈值。默认的10%下降只是一个起点。对于高风险的类别,把阈值收紧到5%。对于低风险的领域,15%可能也能接受。记住,阈值是由失败成本决定的参数,而不是一个普适的常数。
关于模拟器,审计你的提示词变更日志。初始基线之后引入的每条指令,都代表一个潜在的冲突点。为每条指令写一个失败函数,让输出强制反映这个特定冲突。如果你加了一个路由优先级规则,就创建一个函数,强制那个规则会截获的查询类型被误分类。构建这个模拟器的过程本身,就会强迫你以手动测试永远无法达到的程度,去映射你提示词的失败面。
结语
提示工程不是一锤子买卖。它是对一个随机API的持续性维护。每当你为了处理一个新边界情况而加一条指令时,你都在改变这个提示词已能处理的所有查询类型的行为方式。有些改动是无害的。有些改动则是在你根本没注意到的类别上,发生静默式的崩塌。
这个回归套件并不是不让你改提示词。它只是能在你改了之后,明确地告诉你:到底什么坏了。
完整代码:https://github.com/Emmimal/prompt-regression-suite
声明
本文所有代码均为作者原创,在Python 3.12、Windows 11、纯CPU环境下开发和测试。基准测试输出来自run_regression.py的真实运行结果,通过克隆仓库并运行入口点即可完全复现。模拟器产生确定性输出:每次运行结果相同。基准测试过程中未调用任何LLM。比较查询失败(在四个版本中均为0.0%)是当前提示词设计的一个已知架构局限,已按原样包含在基准测试中。作者与本文提及的任何工具、库或公司均无财务关系。
参考文献
[1] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474. https://doi.org/10.48550/arXiv.2005.11401
[2] Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35. https://doi.org/10.48550/arXiv.2201.11903
[3] Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems, 36, 46595–46623. https://doi.org/10.48550/arXiv.2306.05685
[4] Sculley, D., Holt, G., Golovin, D., Da vydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems, 28, 2503–2511. https://dl.acm.org/doi/10.5555/2969442.2969519
[5] Beck, K. (2002). Test-Driven Development: By Example. Addison-Wesley Professional.