ViiTorVoice是什么
先说说这个ViiTorVoice到底是什么来头。它是由云上曲率推出的全球首个支持局部编辑的AI语音合成模型,一发布就直接拿下了Seed-TTS权威评测的榜首。核心架构是NAR(非自回归),说白了就是“像改Word一样修语音”——你可以定向替换音频里的某个词或某一片段,其余的音色、节奏、情感全都不变。除此之外,它还支持无文本跨语种克隆、情绪精准控制,以及低至60ms的端到端首帧延迟。值得一提的是,1B参数的模型已经开源,开发者可以直接上手。
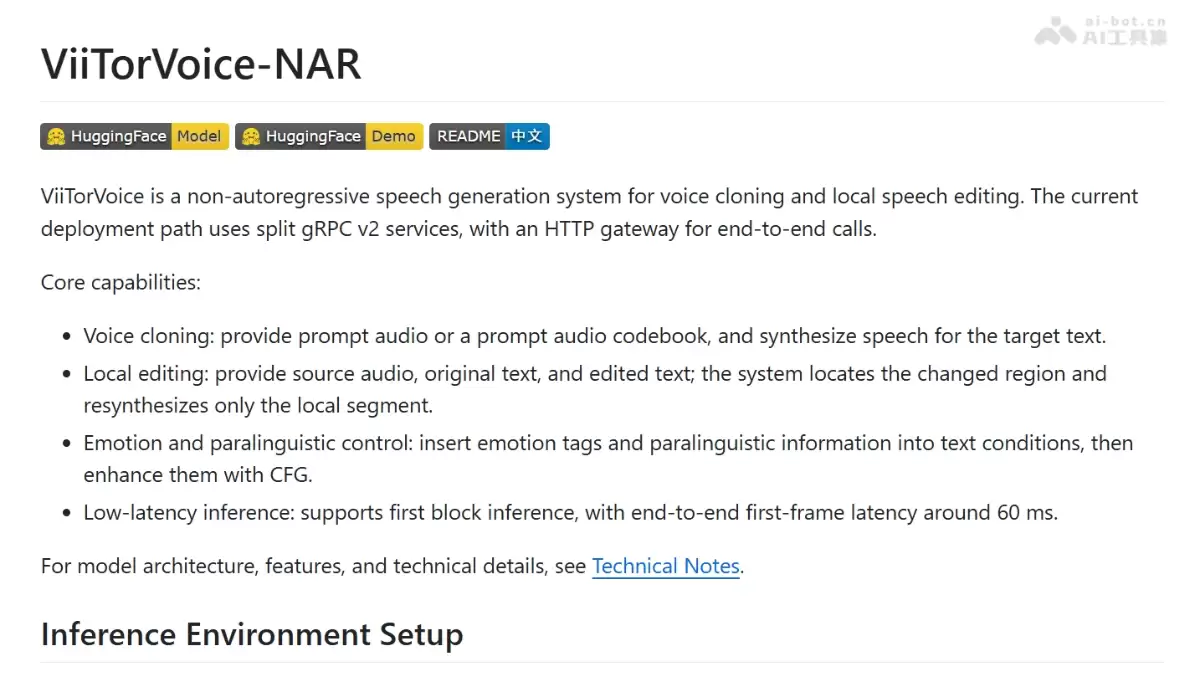
ViiTorVoice的主要功能
- 片段级局部编辑:指定替换音频中的某个词或片段,其余部分完全不变,精准得像用手术刀。
- 语音克隆:支持无参考文本(Zero-Shot)跨语种克隆,只需上传纯音频就能提取音色,连转录文本都不需要。
- 情绪与副语言控制:通过插入特殊Token(比如
- 低延迟推理:首帧生成时间低于60ms,支持首块推理,几乎感觉不到等待。
- 多语种支持:中、英、日、韩等多语种内容生成,覆盖主流语言。

如何使用ViiTorVoice
- 访问Demo页面:直接打开Hugging Face的在线体验地址(https://huggingface.co/spaces/ZzWater/ViiTorVoice),无需本地部署。
- 选择功能模式:在界面顶部切换「Voice Edit」(局部编辑)或「Voice Clone」(语音克隆)标签,看你要修词还是克隆。
- 上传源音频:把需要编辑或克隆的原始音频文件拖入左侧「Source Audio」区域,支持常见格式。
- 输入文本指令:在编辑框中填写原始转录文本和修改后的目标文本,系统会自动定位差异片段——你只管写,它来算。
- 插入情绪标签:如果想控制情感,在文本里插入特殊Token,比如
- 调整生成参数:设置推理步数(4步或8步)等配置,点击生成按钮,等几秒就好。
- 预览与下载:右侧「Edited Audio」区域播放效果,确认无误后下载保存到本地,一步到位。
ViiTorVoice的核心优势
- 评测成绩全球第一:在Seed-TTS榜单上,英文词错率1.32、中文词错率0.99,SIM-o与UTMOS分数也全面领先,数据不会说谎。
- 独创局部编辑能力:行业唯一支持片段级定向编辑,解决了传统TTS改词必须整段重录的痛点——以前改一个词要跑整句,现在只改那一秒。
- 无文本依赖克隆:不需要准确的转录文本就能实现跨语种音色迁移,这对小语种场景来说非常实用。
- 极速推理:首帧延迟控制在60ms以内,远优于行业常见的150-200ms水平,实时交互毫无压力。
ViiTorVoice的项目地址
- GitHub仓库:https://github.com/viitor-ai/viitor-voice-nar
- HuggingFace模型库:https://huggingface.co/ZzWater/ViiTorVoice-NAR
ViiTorVoice的同类竞品对比
| 对比维度 | ViiTorVoice | Qwen3-TTS |
|---|---|---|
| 研发方 | 云上曲率 | 阿里巴巴通义实验室 |
| 核心架构 | NAR 非自回归(完形填空式) | AR 自回归(逐帧链式生成) |
| 局部编辑 | ✅ 支持片段级定向修改,改词不改全段 | ❌ 不支持,修改一词需整段重生成 |
| Seed-TTS 英文 WER | 1.32(更低=更准) | 1.54 |
| Seed-TTS 中文 WER | 0.99(行业首个<1.0) | 1.15 |
| 首帧延迟 | <60ms | ~150-200ms |
| 无文本克隆 | ✅ 仅需纯音频即可跨语种克隆 | ❌ 需提供音频+准确转录文本 |
| 情绪控制 | 词级 Token 精准控制(笑声/叹气等) | 基础自然语言描述控制 |
ViiTorVoice的应用场景
- 影视后期制作:对白调整无需召集演员重进录音棚,导演在非线性时间线上直接替换台词,音色和呼吸节奏都能无缝保持一致——省时又省心。
- 有声书与播客:录制中间出现口误或专有名词错误,只需定向修改一两秒的音频,不用重录整章。后期修音时间从几天压缩到几十分钟,效率提升显著。
- 短剧出海本地化:不需要重新召集配音演员,直接在原始录音上替换特定用词,就能产出多语言版本。每版听感都像原生表演,本地化成本大幅降低。
- 广告营销:文案临时调整产品名称或Slogan时,直接局部替换音频片段,品牌音色和情绪感染力得以保留,不需要重录整个广告。
- 游戏配音:跨语种角色语音快速克隆,只要上传角色原声音频,就能生成中、英、日、韩等多语种配音,让游戏角色在全世界说同一种“声音”。