QwQ-32B模型发布后,在AI社区引发广泛关注。今天咱们直击主题,详细讲解如何借助阿里云原生工具,轻松完成模型的部署与调用。这是一篇纯实操指南,从性能表现到部署细节,都将为你逐一拆解。
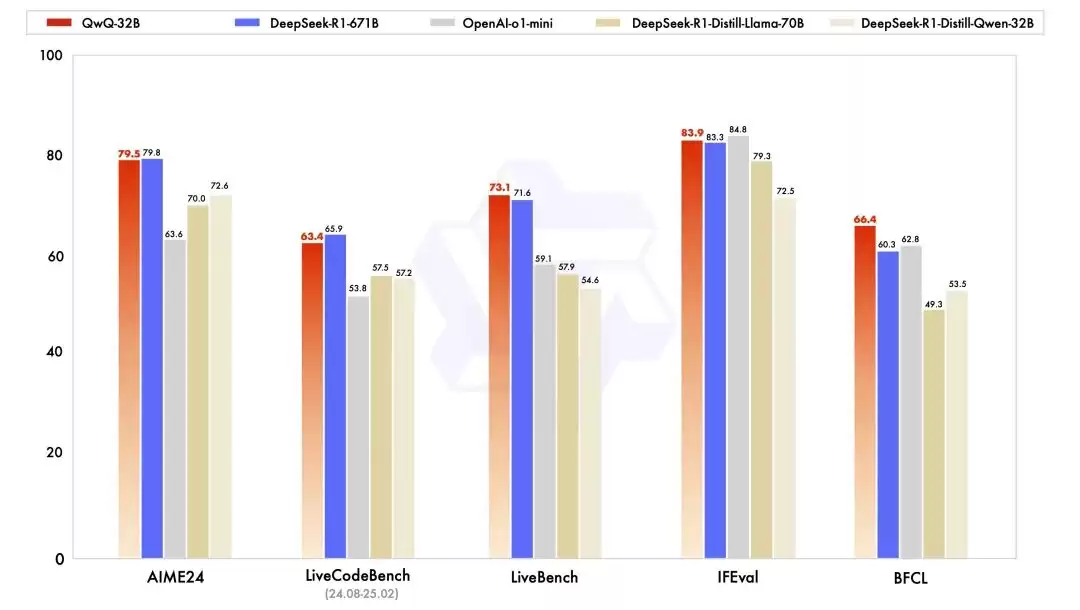
首先看性能——尽管仅有32B参数,该模型的表现却相当惊艳。在AIME24、LiveCodeBench等数学与编程基准测试中,其成绩与DeepSeek-R1-671B几乎持平,大幅超越OpenAI o1-mini以及同尺寸的蒸馏模型。更令人惊喜的是,在LiveBench、IFEval和BFCL等综合能力、指令遵循与函数调用评估集上,它甚至超过了DeepSeek-R1-671B。可以说,小尺寸参数实现了“越级”水平的性能突破。
那么如何快速上手使用它?目前阿里云原生平台提供两种便捷方式:一种是“应用模板”,直接搭建好带聊天界面的AI助手;另一种是“模型服务”,通过API接口对接现有业务系统。下面分别讲解操作步骤。
前置准备
首次使用阿里云CAP平台时,进入后会自动跳转至授权页面,滚动至底部点击“确认授权”即可。等待授权完成,返回控制台,前置准备工作便告完成。请注意,此过程中创建的GPU函数会按资源规格与调用时长计费,不过无请求时仅产生极低的闲置快照费用。建议先领取函数计算试用额度用于抵扣消耗,超出部分再按量付费,具体细节可查阅计费说明。
方式一:应用模板部署——带界面的聊天助手
该方法适合希望直接体验对话交互效果的用户。
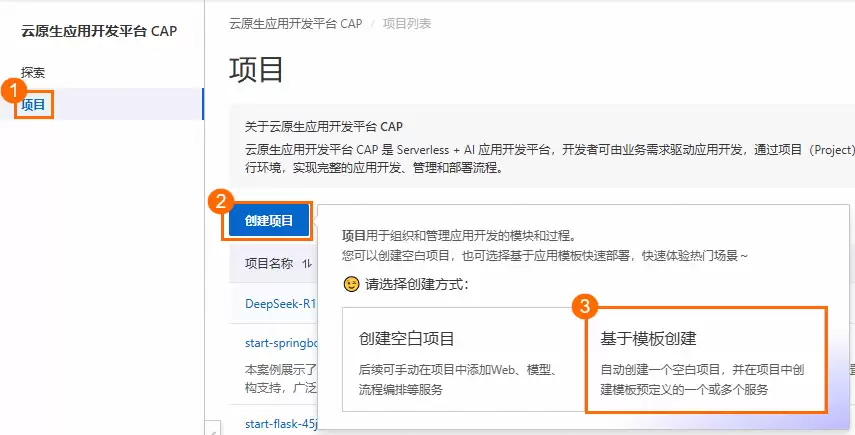
1. 创建项目
进入CAP控制台,点击“基于模板创建”。
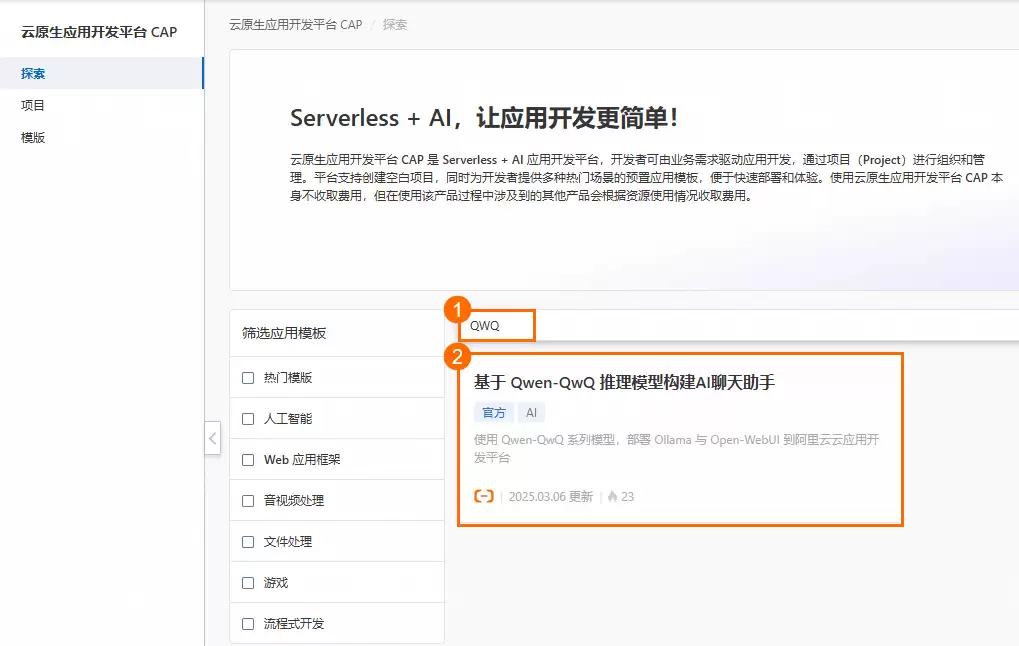
2. 部署模板
- 在搜索栏输入“QWQ”,查找名为“Qwen-QwQ 推理模型构建AI聊天助手”的模板,点击进入详情页,再点击“立即部署”。
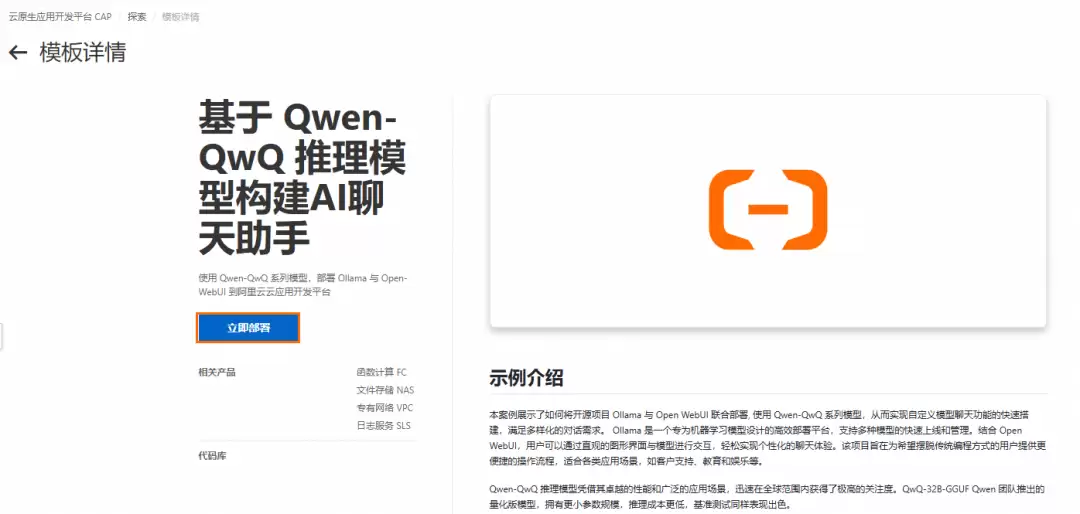
- 接着选择地域(当前支持北京、上海、杭州)。一般就近选择即可,但若之前已开通NAS文件系统,需确保选择相同地域。部署过程大约需要10分钟,状态变为“已部署”即表示成功。若遇到部署异常或模型拉取失败,很可能是当前地域GPU资源紧张,可尝试切换其他地域。

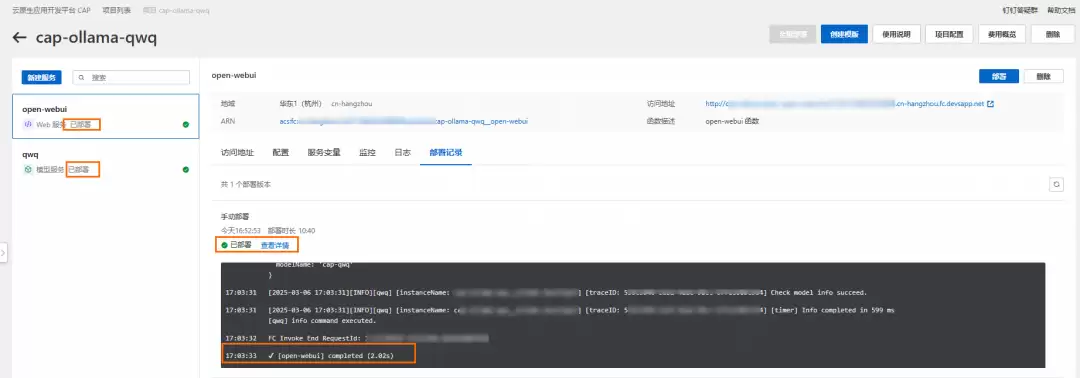
3. 验证应用
部署完成后,点击“Open-WebUI”服务,在“访问地址”中找到“公网访问”并点击,即可在OpenWebUI界面直接与QwQ模型进行对话。

方式二:模型服务部署——走API,对接业务
若希望将模型能力集成到自有应用中,API方式更为合适。
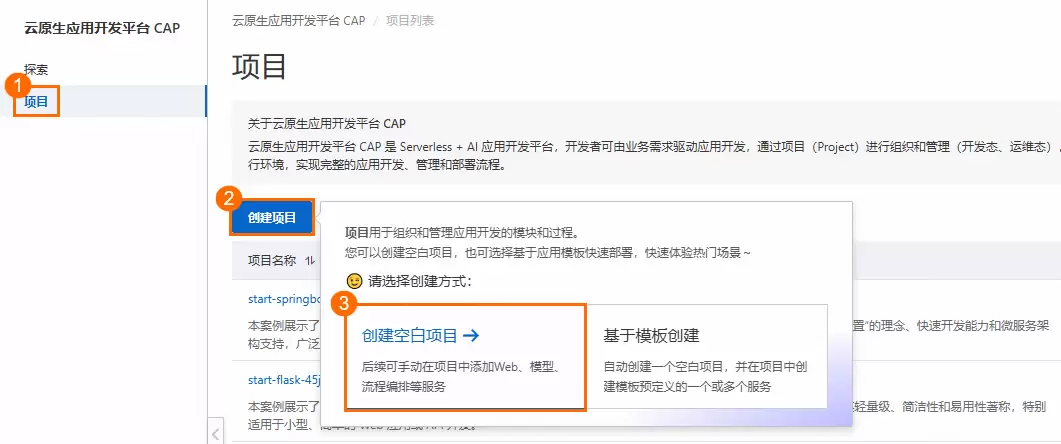
1. 创建空白项目
进入CAP控制台,点击“创建空白项目”,为项目命名即可。
2. 选择模型服务
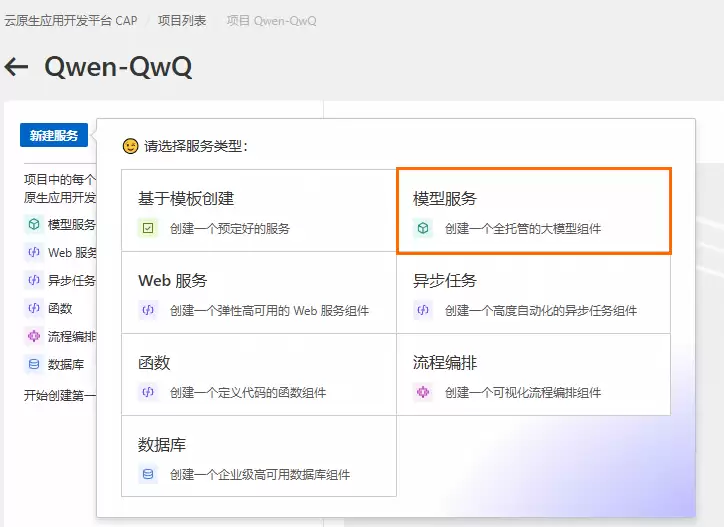
3. 部署模型服务
- 选择模型“QwQ-32B-GGUF”,目前仅支持杭州地域。
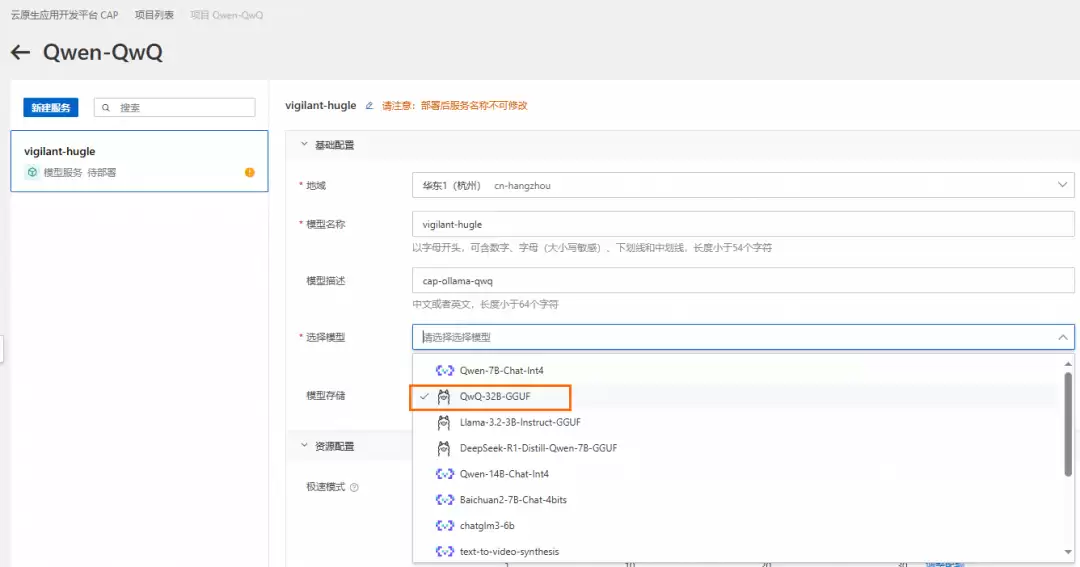
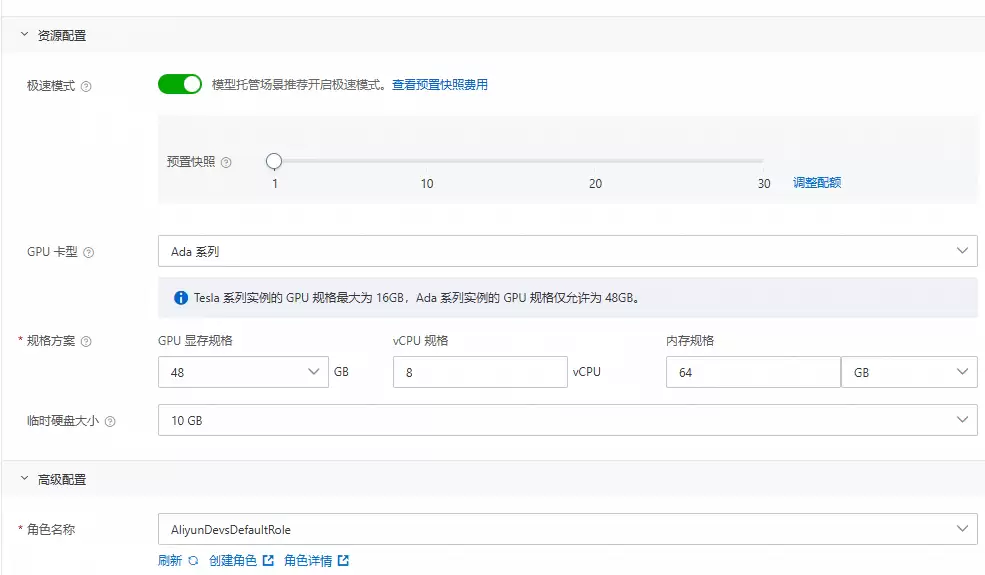
- 点击“资源配置”,推荐使用Ada系列,采用默认配置即可。若有特定需求,也可手动调整卡型与规格。
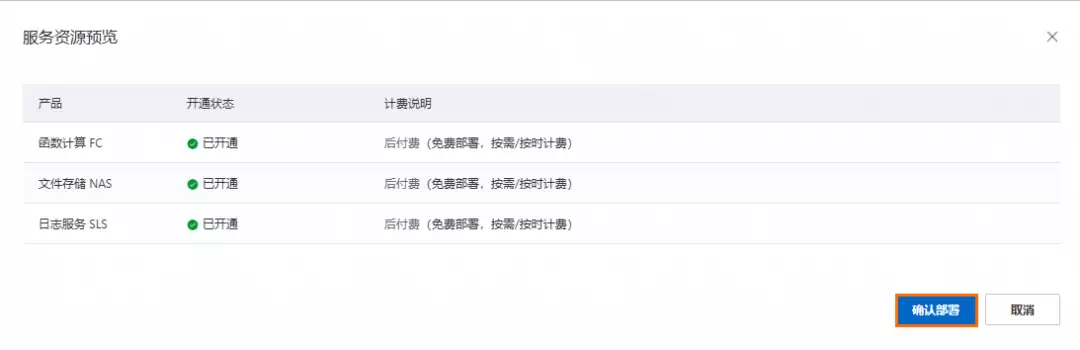
- 点击“预览并部署”,确认计费项后点击“确认部署”。此步骤需下载模型,等待10至30分钟即可完成。
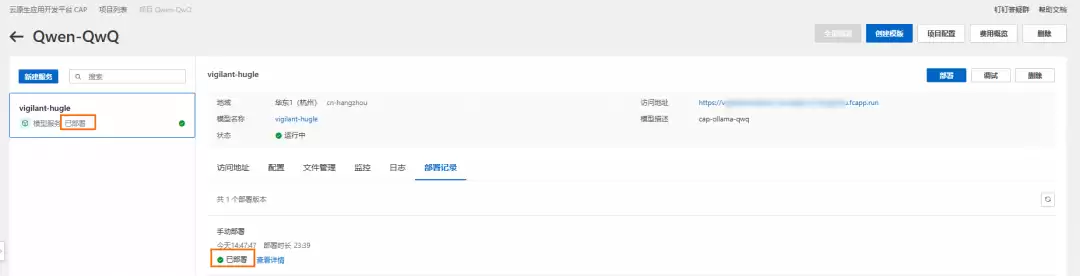
4. 验证模型服务
部署完成后,点击“调试”,即可在该界面直接测试模型调用,验证服务是否正常运行。
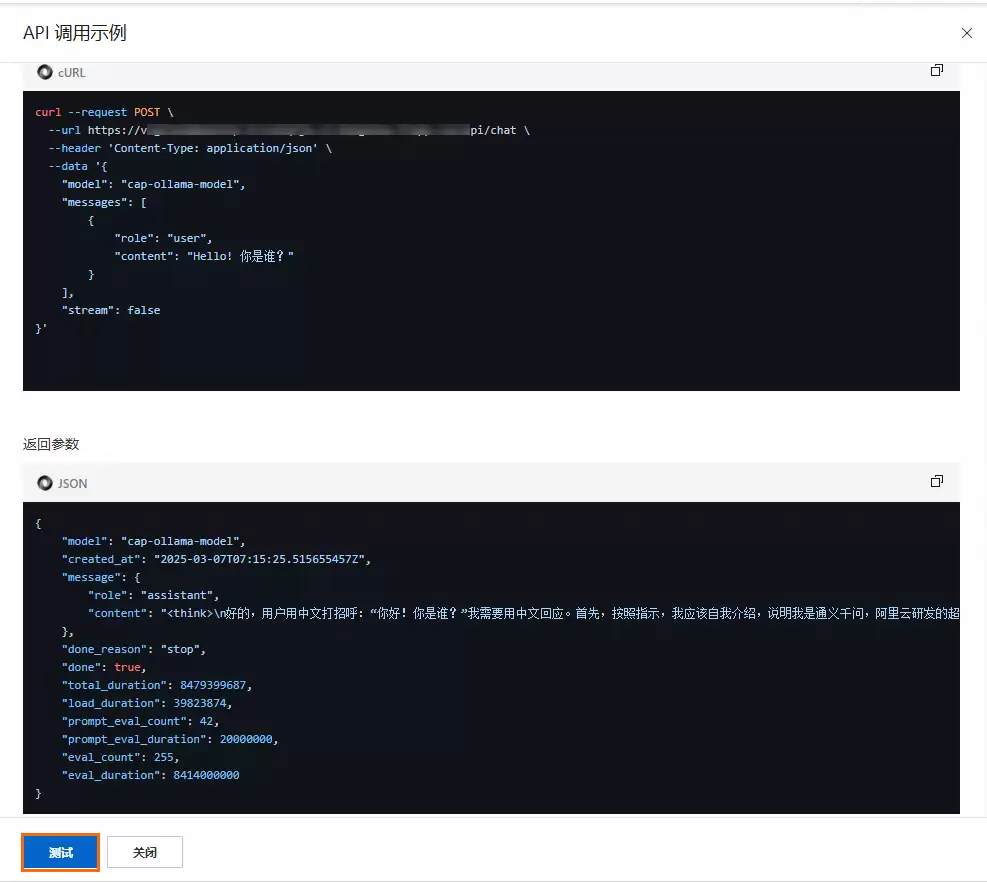
此外,也可直接在本地命令行窗口中通过API进行调用验证。
5. 第三方平台 API 调用
若你偏好在其他平台(如Chatbox等)进行测试,可直接使用此处生成的API进行接入与验证。
删除项目
如果仅是为了体验,测试结束后建议及时删除项目,避免产生不必要的费用。操作方法:进入项目详情,点击“删除”,确认弹出对话框中的资源列表。默认会删除项目下所有服务,若希望保留某些资源,可取消勾选对应服务。确认无误后,勾选“我已知晓...”并点击“确定删除”即可。
以上便是两种部署QwQ-32B模型的方法,步骤清晰直接。希望你能快速搭建并顺利运行起来,尽享AI推理的乐趣。