掌握RAG系统预处理关键技术,对提升知识库检索效率至关重要。坦白说,许多开发者在构建RAG应用时,往往一开始就聚焦于大模型或向量数据库,而忽略了预处理环节。然而实际效果的关键,恰恰取决于文本切片这一步是否扎实。本文就来深入探讨这个容易被忽视却极为重要的前置步骤。
背景
RAG文本切片
文本切片是构建高效RAG系统不可或缺的前置环节,其重要性体现在以下三个方面:
首先,语言模型的上下文窗口容量有限,即便再长的文本也需拆分为语义完整的段落,否则关键信息极易被截断或丢失。其次,精准的切片策略能显著提高向量检索的查准率——试想如果段落中混杂过多无关信息,检索结果便会因语义稀释而变得模糊不清。最关键的是,合理的切片粒度(无论是按句子还是按段落切分)能够保持语义的连贯性,为后续的上下文推理奠定坚实基础。
这种预处理机制直接决定了RAG系统在知识召回精度与生成内容相关性上的最终表现。
文本切片中的常见问题
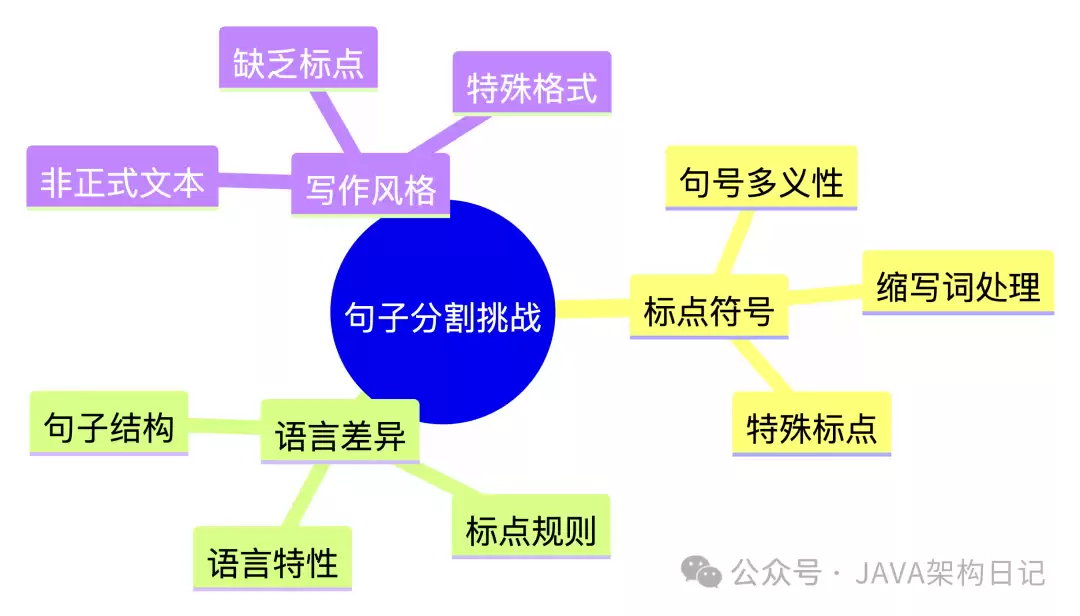
那在实际操作中,切片这活儿到底难在哪儿呢?
- 语义边界模糊:自然语言中的句号并非总是句子结束的标志。例如缩写词中的点、小数点等,都会使简单的标点分割方法失效。
- 语言特定处理:中文缺乏空格作为天然分词依据,日语句尾标记也不明显——每种语言都有其独特语法,需要单独设计分割逻辑。
- 领域术语干扰:医疗缩写如"q.d."、法律条款编号等专业符号常被误判为句子结尾,从而导致分割位置错误。
- 格式噪声干扰:代码片段、数学公式等非自然语言内容,若直接套用通用分割策略,往往会破坏原本完整的逻辑结构。
解决方案
那么,是否存在现成的、开箱即用的解决方案?langchain4j 库中的 DocumentBySentenceSplitter 组件便是一个很好的起点。它能够智能地将文档按句子分割,生成适合后续处理的文本段落,而其背后的核心技术正是 Apache OpenNLP 的句子检测功能。本文将详细拆解该组件的工作原理。
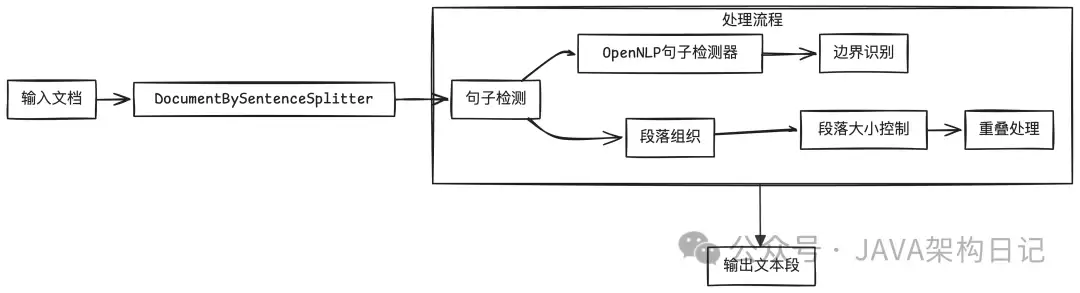
Apache OpenNLP 简介
Apache OpenNLP 是一个基于机器学习的自然语言处理工具包,句子检测仅是其众多功能之一。但仅此一项,就能有效解决常见的文本分割难题。
代码实现示例
在实际操作中,上手过程并不复杂。下面展示引入依赖与核心代码的示例:
dev.langchain4j
langchain4j-easy-rag
1.0.0-beta1
// 初始化token计算器
Tokenizer tokenizer = new HuggingFaceTokenizer();
// 创建分割器实例:最大段落大小为100个词符,无重叠
DocumentBySentenceSplitter splitter = new DocumentBySentenceSplitter(100, 0, tokenizer);
// 准备文档
String text = """
Go ahead with life as it is, with the bumps and pitfalls. However it is, give your best to every moment.
Don't spend your time waiting for the perfect situation, something which is not very likely to come.
Life is not perfect; the way you live can make it perfectly wonderful.
""";
Document document = Document.from(text);
// 执行分割
List segments = splitter.split(document);
总结
当前,langchain4j 基于 OpenNLP 提供了开箱即用的句子分割实现,默认加载英文方言的句子分割模型,足以覆盖大多数通用场景。然而现实世界中的文本远比示例复杂得多。因此在实际应用中,常见的扩展方向主要有两个:
- 自定义模型训练:若处理的是垂直领域文档(如医疗病理报告或法律判决书),可利用领域语料训练专属 OpenNLP 模型,从而显著提升分割准确率。
- 扩展中文NLP工具集成:完全可以参考当前实现思路,接入 HanLP、jieba 等主流中文 NLP 工具。这些工具对中文语义边界的理解更为精准,能有效解决中英文混合场景下的切片痛点。
通过上述扩展与优化,我们完全有能力构建更强大、更灵活的文本分割系统,为 RAG 应用奠定更坚实的数据基础。