GPT-3难以复现的真正原因:PyTorch为何走上一条大弯路
类型:热点整理2026-07-03
2020年,AI领域最震撼的新闻莫过于OpenAI发布了GPT-3。这个拥有1750亿参数的模型在众多NLP任务中超越了人类水平,彻底证明了“大模型才是未来”的方向。然而,训练如此规模的模型所需的算力和存储资源,已经不是单台机器能够胜任的。 根据NVIDIA的估算,即便单台GPU的显存足以容纳全部参
2020年,AI领域最震撼的新闻莫过于OpenAI发布了GPT-3。这个拥有1750亿参数的模型在众多NLP任务中超越了人类水平,彻底证明了“大模型才是未来”的方向。然而,训练如此规模的模型所需的算力和存储资源,已经不是单台机器能够胜任的。
根据NVIDIA的估算,即便单台GPU的显存足以容纳全部参数,使用8张V100显卡训练GPT-3也需要36年;换成512张V100,仍需将近7个月;即使采用1024张80GB的A100,也要整整1个月。硬件投入只是经济账,从技术层面看,训练大模型本质上是一个分布式问题——算力缺口可以通过堆砌机器来解决,但如何协调上千块GPU高效协同工作,才是真正的拦路虎。
目前业界已有的分布式训练方案,即便是顶尖的数据科学家,精通Transformer的所有算法细节,如果不了解分布式训练中上百台服务器之间的通信、拓扑、模型并行、流水并行等技术,也根本无法启动训练。某种程度上,这也解释了为什么GPT-3发布一年多后,只有NVIDIA、微软等巨头能够成功复现。
当前开源的GPT模型库主要有NVIDIA的Megatron-LN和微软深度定制的DeepSpeed。DeepSpeed的模型并行内核实际上源自Megatron,两者都是为PyTorch分布式训练GPT而设计的。但在实际训练中,PyTorch、Megatron、DeepSpeed都走过一条漫长而曲折的道路。更麻烦的是,Megatron的代码几乎只有NVIDIA的分布式训练专家才能复用,对普通的PyTorch算法工程师来说门槛极高——任何想用PyTorch复现分布式大模型的人,都必须先等NVIDIA开发完毕,再使用Megatron提供的接口。
作为新一代深度学习开源框架,OneFlow专注于“大模型分布式”高效开发,用一套通用且简洁的设计轻松解决了GPT模型的分布式训练难题,在已有测试规模上性能甚至超越了NVIDIA的Megatron。这为大规模分布式训练框架提供了一条更优的设计路径。
## 一、PyTorch分布式训练GPT的痛点在哪里?
前不久,NVIDIA发表了一篇重磅论文:Efficient Large-Scale Language Model Training on GPU Clusters。他们使用3072张80GB A100训练GPT,最大模型参数规模达到1T——相当于GPT-3原版的5倍。
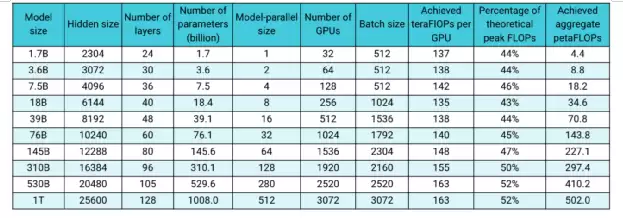
NVIDIA训练GPT-3最大到1T参数规模
论文介绍了分布式训练超大规模模型必须的三种并行技术:
- 数据并行(Data Parallelism)
- 模型并行(Tensor Model Parallelism)
- 流水并行(Pipeline Model Parallelism)
数据并行是最常见的方式。模型并行是对某一层(比如Linear/Dense Layer中的Variable)的模型Tensor进行切分,拆成多个较小的Tensor并行计算。流水并行则是将整个网络分段(stage),不同段部署在不同设备上,像接力一样分批执行。
对1T规模的模型,NVIDIA使用了384台DGX-A100(每台8张80GB A100),机器内部通过超高速NVLink和NVSwitch互联,每台机器配备8个200Gbps InfiniBand网卡——这简直是硬件配置中的顶配。那么这些机器如何协同工作?GPT网络由许多层Transformer Layer组成,每一层内部是MLP和attention机制构成的子图。参数规模1T的GPT有128层Transformer Layer,这个超深网络被分割成64个stage,每个stage运行在6台DGX-A100上,6台机器之间进行数据并行,每台机器内部的8张卡进行模型并行。整个集群的3072张A100按照机器拓扑划分为[6 x 8 x 64]的矩阵,同时使用数据并行、模型并行、流水并行进行训练。
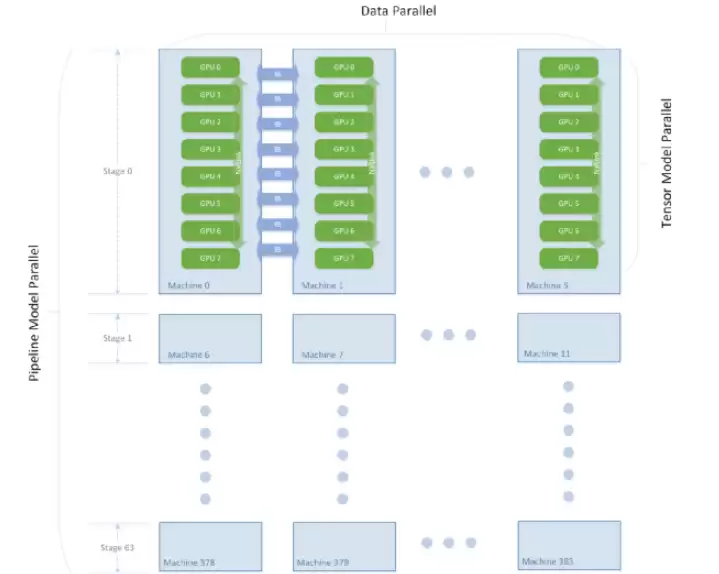
3072张A100集群拓扑
GPipe、梯度累加、重计算(Checkpointing)和1F1B(One Forward pass followed by One Backward pass)是流水并行的核心技术。无论是NVIDIA的Megatron(PyTorch),还是OneFlow、PaddlePaddle、MindSpore,都通过不同的设计实现了相同的功能。
基于PyTorch开发的Megatron,本质上是一个专用于GPT的模型库,所有代码都是Python脚本。NVIDIA为GPT定制了分布式训练所需的算子、流水并行调度器、模型并行通信原语等,在GPU上的性能已经非常出色。可以说,NVIDIA用PyTorch做分布式训练已经做到了极致。但是,用PyTorch做分布式训练真的方便吗?
具体来看,PyTorch在分布式并行设计上存在几个核心困境:
- **只有物理视角,没有逻辑视角**。用户在进行分布式并行时,必须自己推导模型中哪些位置需要与其他物理设备通信,推导通信位置、操作类型、与哪个设备通信。简单的数据并行可以使用DDP或Horovod,但复杂的模型并行、混合并行,门槛极高。
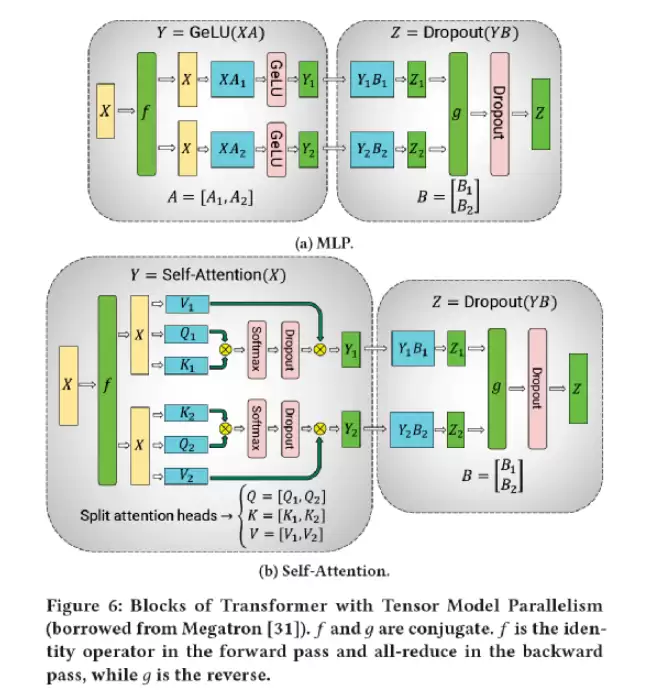
NVIDIA模型并行通信推导
- **没有将算法逻辑和通信逻辑解耦**。用户需要在算子kernel实现、网络脚本中到处插入通信原语,繁琐、易错、不可复用,完全依赖特定模型、特定位置、特定算子的特判。
- **非对称并行(如流水并行)需要人工排线**。用户必须精细控制每个设备的启动和执行逻辑,把前向、反向执行和send/recv通信糅合在一起。即使在规整的Transformer Layer流水并行下也很复杂,扩展到其他模型工作量巨大。
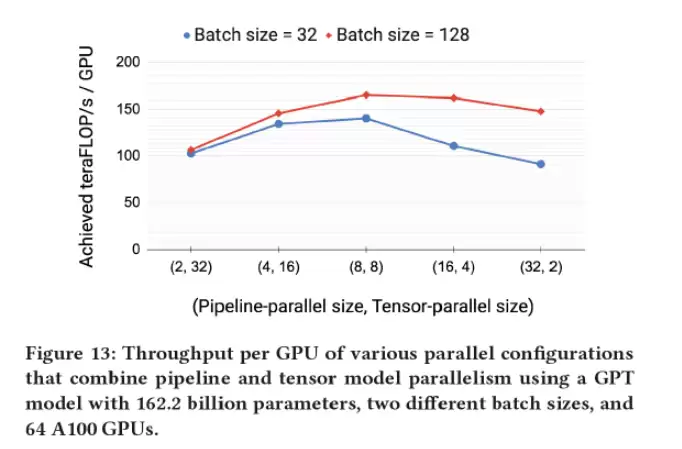
模型并行度和流水并行度对性能的影响
- **没有机制保证分布式训练的正确性和数学一致性**。用户写错通信操作、插错位置、跟错设备,PyTorch也检查不出来。
这些困境让普通算法工程师用PyTorch开发复杂的分布式脚本极其困难。实际上,NVIDIA、微软、PyTorch都被绕进了一个大坑:在没有一致性视角(Consistent View)的情况下做复杂的分布式并行,只能针对具体网络、具体场景、具体算子进行特判,通过简单的通信原语实现分布式。
那么,OneFlow是如何解决这些问题的呢?
## 二、OneFlow用一致性视角轻松填平分布式训练的鸿沟
针对分布式集群环境(多机多卡训练场景),OneFlow将整个分布式集群抽象成一个“超级设备”,用户只需要在这个超级设备上搭建模型即可。这个虚拟出来的超级设备称为**逻辑视角**,实际的多机多卡称为**物理视角**。OneFlow负责维护二者之间的数学正确性,这就是**一致性视角**。
基于一致性视角,OneFlow通过Placement(流水并行)+ SBP(数据和模型混合并行),以非常简洁通用的方式实现了复杂的并行支持。这离不开两大独特设计:
1. 运行时Actor机制
2. 编译期一致性视角,通过Placement + SBP + Boxing解决分布式易用性问题
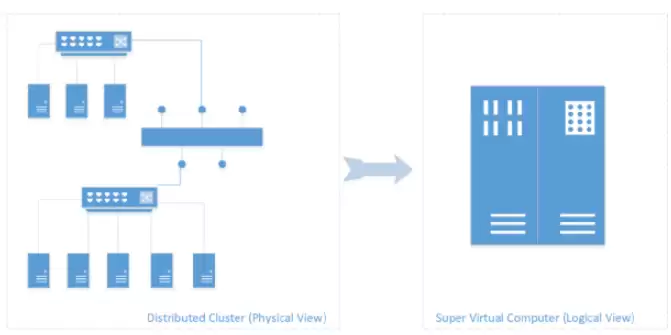
一致性视角(Consistent View)抽象
理想情况下,抽象出来的超级设备(逻辑视角)的算力是所有物理设备算力之和(完全用满就是线性加速比),显存资源也是所有物理设备显存之和。
基于一致性视角的OneFlow分布式具有以下易用性:
- 将多机通信和算法逻辑解耦,用户无需关心分布式细节,降低了使用门槛。
- 通过Placement + SBP机制解决任意并行场景。用户只需配置op的Placement完成流水并行,配置Tensor的SBP实现数据并行、模型并行、混合并行。任何并行方式都是Placement + SBP的一种特例,OneFlow系统层面无需做任何特判——SBP才是各种分布式并行的本质。
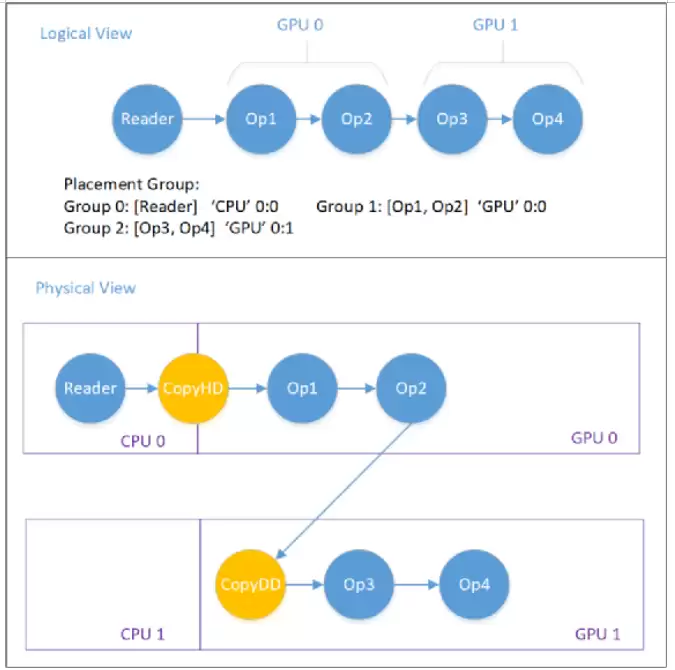
上图展示了一个Placement示例,用于GPU0和GPU1之间的流水并行。图中负责CPU与GPU、GPU与GPU之间数据搬运的Op(CopyH2D、CopyD2D)由系统自动添加。
- 通信逻辑可以复用,不需要为特定网络和算子实现通信逻辑——由Boxing机制完成,与具体算子和模型无关。
- SBP保证了数学上的一致性:对于相同的逻辑模型脚本,使用任意并行方式(数据并行、模型并行、流水并行)、任意集群拓扑,OneFlow都从数学上保证了分布式训练的正确性。
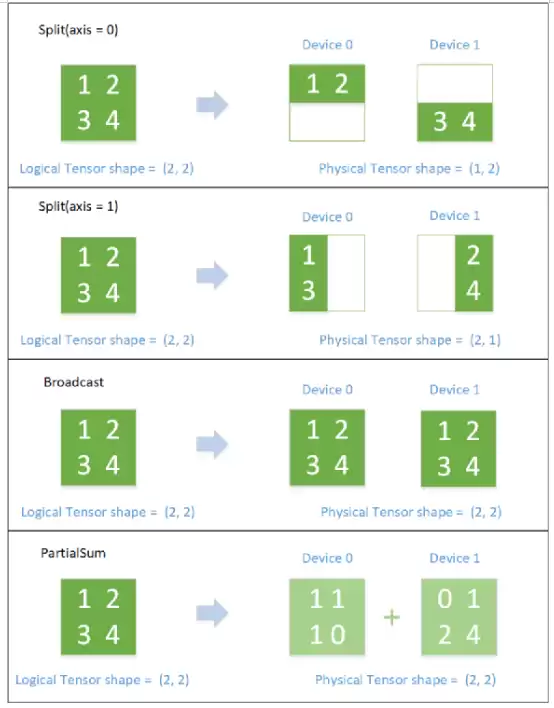
SBP逻辑与物理Tensor的对应关系(SBP全称SbpParallel,三种基础映射:Split、Broadcast、Partial,Partial是reduce操作,包括PartialSum、PartialMin、PartialMax等)
这一套简洁的设计,让每一位算法工程师都有能力训练GPT模型——不需要成为分布式训练专家,只要有硬件资源,任何人都可以训练GPT、开发新的大规模分布式模型。
## 三、为什么分布式深度学习框架要像OneFlow这样设计?
上面从用户角度分析了OneFlow和PyTorch(Megatron)的分布式易用性。那么从框架设计和开发者角度看,OneFlow具体是如何实现分布式并行的?为什么说它更本质?
### 1. OneFlow如何实现流水并行?
OneFlow的运行时Actor机制有以下几个特点:
- 天然支持流水线。Actor通过内部状态机和产出的Regst个数以及上下游的Regst消息机制来解决流控问题(Control Flow)。
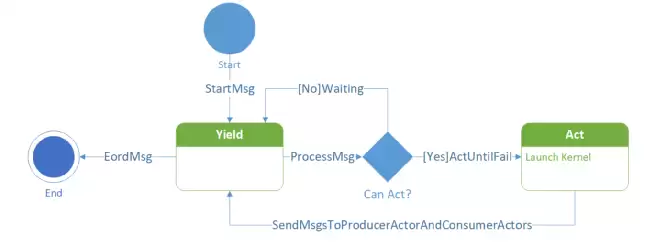
Actor状态机
- Actor组成的计算图运行时调度是去中心化的,每个Actor当前是否可执行只与自己的状态、空闲Regst数量和收到的消息有关。
因此,使用Actor做流水并行,不需要自己定制复杂的调度逻辑。以数据加载的Pipeline为例,一个由Actor组成的数据预处理流程如下:
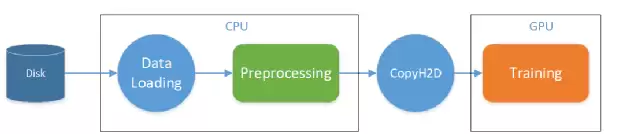
数据预处理流程
当这4个Actor之间的RegstNum均为2时,如果训练时间较长(训练是整个网络的瓶颈),就会得到这样的流水线时间线:
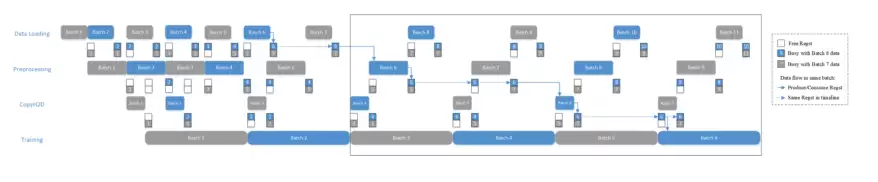
数据预处理pipeline时间线
执行几个Batch后,4个阶段的节奏完全被最长的阶段控制——这就是OneFlow通过背压机制(Back Pressure)解决流控问题。
所以,流水并行问题在OneFlow中就是Regst数量的问题。实际实现中,OneFlow采用了一个更通用的算法实现Megatron的流水并行:插入Buffer Op。在逻辑计算图上,给后向消费前向的边插入一个Buffer Op,Buffer的Regst数量与Stage相关。由于后向对前向的消费经过Checkpointing优化后,每个Placement Group下只有非常少的消费边。
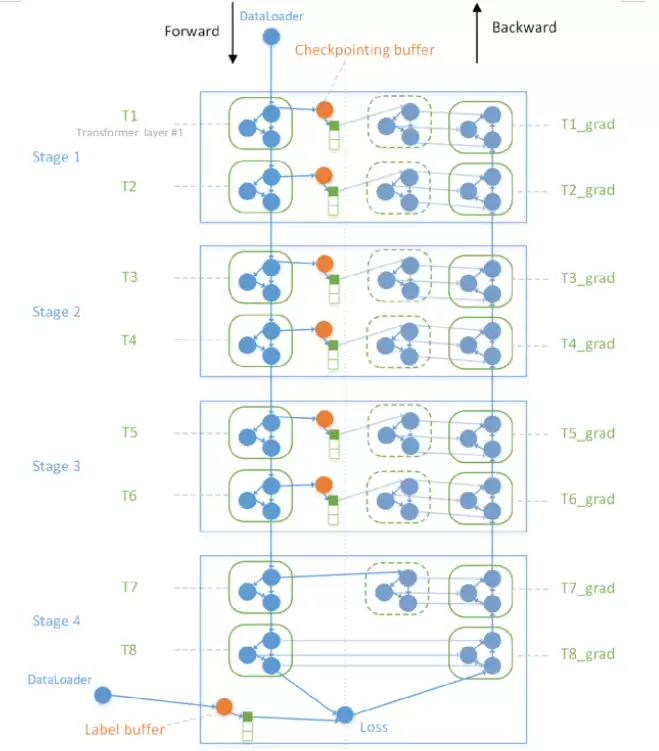
OneFlow通过插入Buffer Op实现流水并行
与Megatron复杂的手写调度器和通信原语相比,OneFlow系统层面只需插入Buffer就能实现流水并行。
### 2. OneFlow如何实现数据+模型的混合并行?
以Linear Layer的数据+模型并行为例。所有数据并行和模型并行的组合,本质上都是SBP描述的Signature。任何并行方式的设备间通信操作,在哪里插入、插什么操作、每个设备与谁通信,都由SBP自动推导,并且保证数学一致性。
OneFlow的设计让算法工程师告别了分布式通信原语。不仅如此,OneFlow的框架开发者绝大多数时候也不需要关心通信原语——SBP这层抽象使算子/网络与分布式通信解耦。
以1-D SBP为例。数据并行下,对于Linear Layer主要是MatMul(矩阵乘法)。假设逻辑视角上是(m, k) x (k, n) = (m, n),m表示样本数,k和n分别是隐藏层神经元数和输出神经元数。
数据并行的逻辑计算图→物理计算图映射如下:
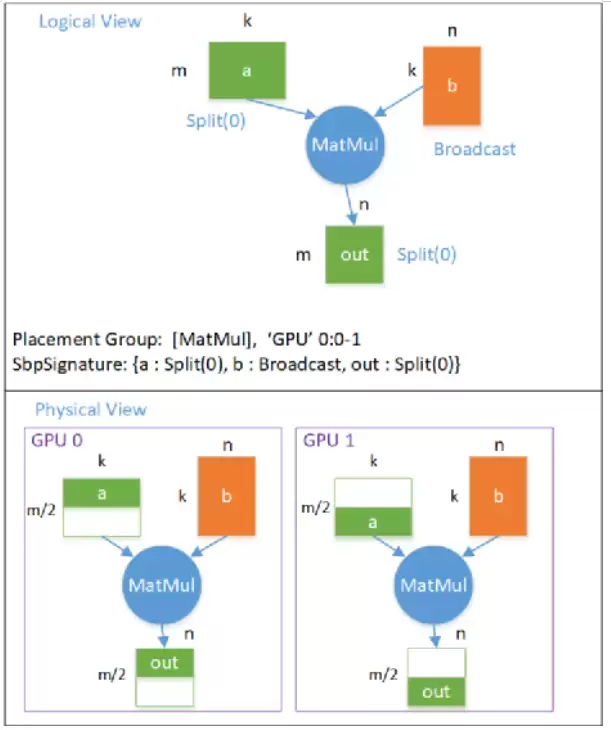
数据并行下逻辑计算图转物理计算图
数据并行下,每个设备拥有完整的模型(Tensor b, Shape=(k, n))。假设两张卡,GPU0上有前一半数据(Tensor a, Shape=(m/2, k)),GPU1上有后一半,则Tensor a的SBP Parallel = Split(0)。输出Tensor out也按第0维切分。
模型并行对Linear Layer有两种方式:切模型Tensor第0维(行切分,对应Megatron的RowParallelLinear)和第1维(列切分,对应ColumnParallelLinear)。
行切分模型并行逻辑图→物理图映射:
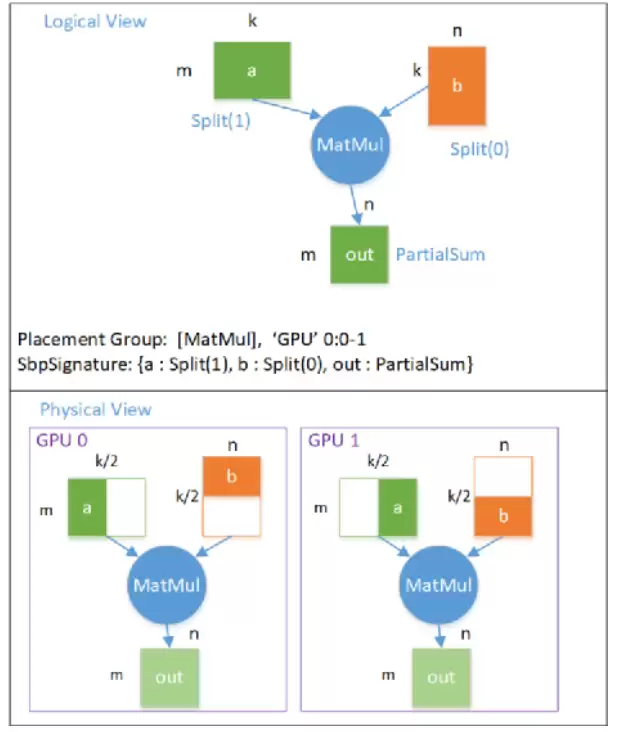
模型并行(行切分)逻辑图转物理图
模型并行下,每个设备只有部分模型。GPU0有前一半模型,GPU1有后一半,Tensor b的Shape=(k/2, n)。每个设备输出Tensor out都是完整大小Shape=(m, n),但每个位置的值是逻辑out对应位置的一部分——out的SBP Parallel = PartialSum。
列切分模型并行逻辑图→物理图:
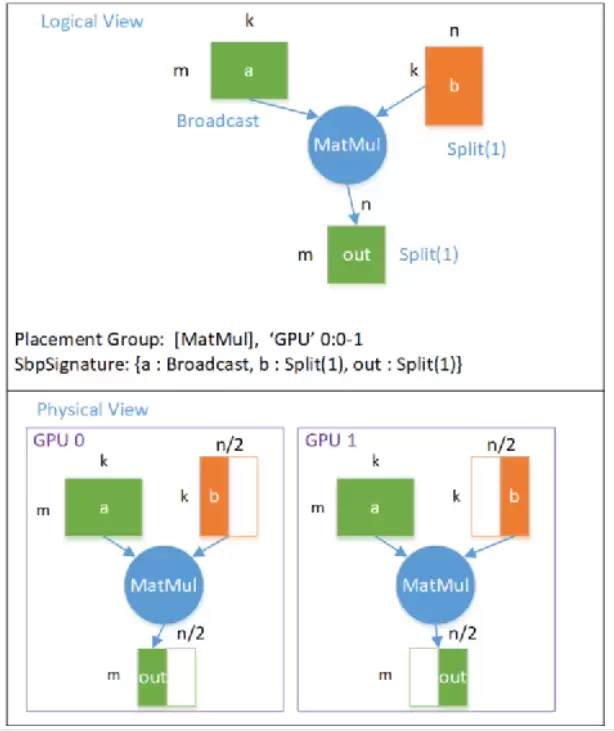
模型并行(列切分)逻辑图转物理图
模型Tensor b按Split(1)切分,输出Tensor out也按Split(1)切分,每个设备需要全部数据。
在GPT网络中,实际模型并行是组合使用RowParallelLinear和ColumnParallelLinear(Column后接Row)。因为Column的输出SBP是Split(1),Row的输入也是Split(1),所以两者之间不需要插入任何通信。但Row的输出是PartialSum,当后面消费该Tensor(如Add操作)的Op需要全部数据(Broadcast)时,就需要插入AllReduce来实现通信——OneFlow中称之为Boxing。当两个逻辑Op对同一逻辑Tensor的SBP Parallel不一致时,系统自动插入通信节点完成数据切分/传输/拼接,使下游Op总能拿到按自己期望SBP切分的Tensor。
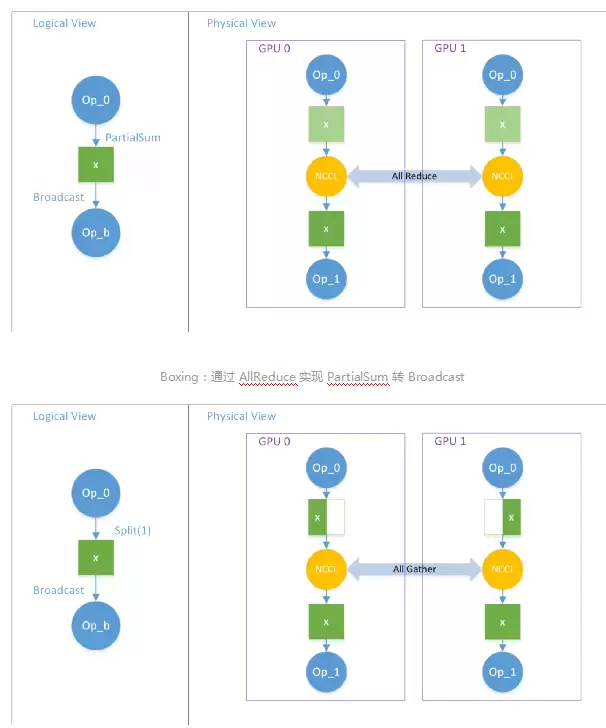
Boxing:通过AllGather实现Split(1)转Broadcast
OneFlow中所有分布式通信操作都基于SBP推导插入,通过Boxing机制实现任意的数据并行和模型并行。
2-D SBP就是把两组1-D SBP按设备拓扑维度拼起来。GPT中用到的2-D SBP只是最简单情形的特例,但通过2-D SBP可以拓展出非常复杂灵活的组合。对于复杂组合,用Megatron的设计很难实现,但对OneFlow来说,难度是一样的——本质上都是用Boxing完成一组2-D SBP变换。
## 四、GPT分布式训练性能对比:OneFlow vs Megatron
与Megatron相比,OneFlow不仅在用户接口和框架设计上更加简洁易用,在4机32卡16GB V100的测试规模下,性能也超过了Megatron。值得一提的是,NVIDIA对Megatron在GPU上的分布式训练性能优化已经接近极致,DeepSpeed也无法与之相比。
以下所有实验数据均在相同硬件环境、相同第三方依赖(CUDA、cuDNN等)、相同参数和网络结构下,对比OneFlow和Megatron在GPT模型上的性能表现。所有结果均可公开复现(GPT模型脚本在Oneflow-Inc/OneFlow-Benchmark仓库,公开评测报告和复现方式稍后在Oneflow-Inc/DLPerf仓库查看)。
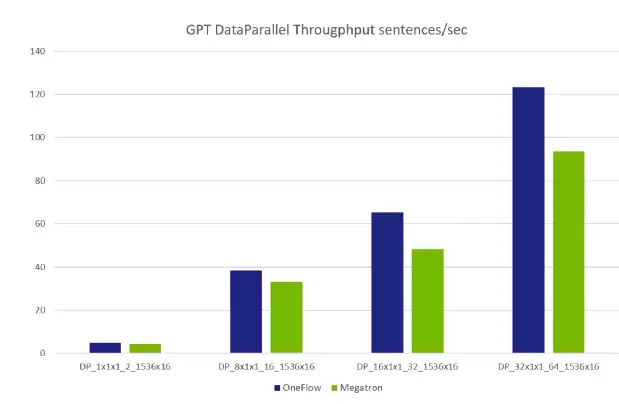
数据并行性能对比
注:每组参数缩略版含义:
- DP 数据并行;MP 模型并行;2D 数据&模型混合并行;PP 流水并行
- dxmxp_B_hxl 其中:
- d = 数据并行度(data-parallel-size)
- m = 模型并行度(tensor-model-parallel-size)
- p = 流水并行度(pipeline-model-parallel-size)
- B = 总的BatchSize(global-batch-size)
- h = 隐藏层大小(hidden-size)
- l = Transformer Layer层数(num-layers)
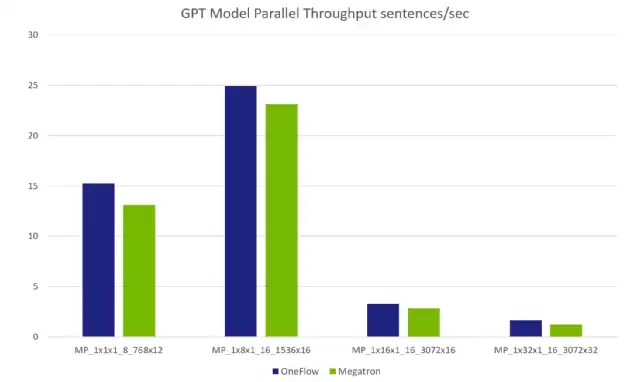
模型并行数据对比
注:由于单卡显存限制,各组模型大小不同,所以不像数据并行那样线性增加。如第4组(MP_1x32x1_16_3072x32)的模型大小是第2组(MP_1x8x1_16_1536x16)的8倍以上。NVIDIA论文中有模型规模与参数的计算公式:
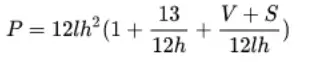
其中l表示num-layers,h表示hidden-size,V表示词表大小(vocabulary size=51200),S表示句子长度(sequence length=2048),P表示参数规模。
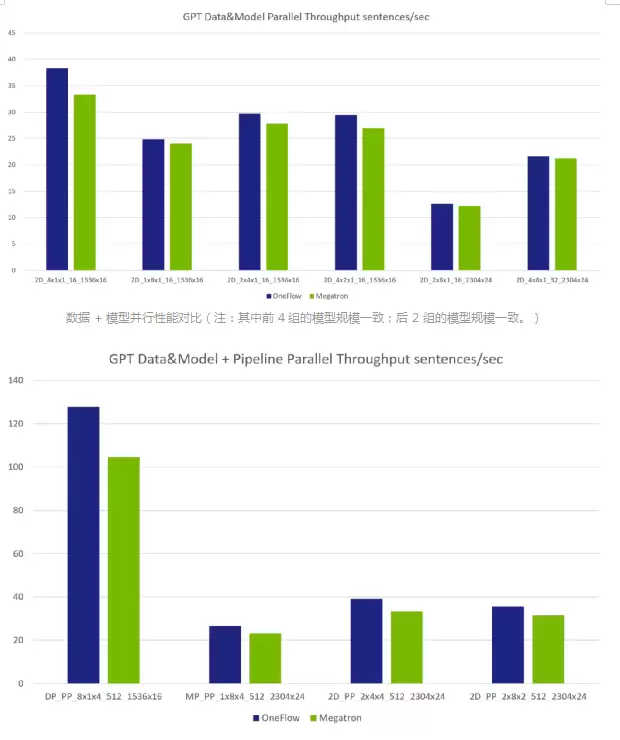
数据+模型+流水并行性能对比(注:第1组模型比后3组小,因为机器内数据并行限制了参数规模)
## 五、小结
在分布式训练领域,OneFlow凭借独特的设计和视角,成功解决了分布式训练中的各种并行难题,使得在大规模预训练模型场景下,使用OneFlow进行分布式训练不仅更易用,也更高效。
同时,OneFlow团队正在全力提升框架的单卡使用体验。据悉,OneFlow即将在5月发布的大版本OneFlow v0.4.0起,将提供兼容PyTorch的全新接口以及动态图等特性。而在v0.5.0版本,OneFlow预计全面兼容PyTorch,届时用户可将PyTorch的模型训练脚本一键迁移为OneFlow的训练脚本。此外,OneFlow还会提供Consistent视角的分布式Eager,用户可以既享受动态图的易用性,又方便地进行各种分布式并行训练。