探索AI大模型微调的多元化策略:为不同需求定制解决方案
在人工智能领域,大模型已成为处理复杂任务的核心工具。然而,直接使用预训练模型往往难以精准满足特定任务的需求——这时就需要微调(Fine-Tuning)登场。微调的本质是在模型已有的通用知识基础上,针对具体任务的数据进行“定向强化”,让它在特定方向上表现更优。但微调并非“一招鲜吃遍天”,任务需求不同、数据规模各异、资源约束也各有差别,相应的方法自然需要灵活选择。下面详细拆解10种主流的大模型微调方法,从全参数微调到适配器微调,从提示微调到知识蒸馏,每种方法都有其独特优势和适用场景。无论你是刚入门的新手,还是经验丰富的从业者,都能从中找到匹配自身需求的策略。
1. 全参数微调(Full Fine-Tuning)
- 通俗理解:好比一个已经掌握大量通用知识的“大脑”(预训练模型),现在需要它专门钻研新任务(如情感分析或机器翻译)。那就让这个大脑把所有知识从头到尾重新梳理一遍。
- 具体方法:
加载预训练模型(比如BERT、GPT)。 准备新任务的数据(比如标注好的情感分析数据集)。 用新数据重新训练模型的所有参数,通常使用较小的学习率(比如1e-5到1e-4),避免破坏预训练的知识。 在验证集上评估模型性能,调整超参数(如学习率、批量大小)。
- 优点:效果通常非常出色,适合任务差异较大的场景。
- 缺点:计算成本高昂,需要大量数据和计算资源。
- 适用场景:任务复杂且与预训练任务差异显著(比如从通用文本理解迁移到医学文本分析)。
2. 部分参数微调(Partial Fine-Tuning)
- 通俗理解:不想改动整个“大脑”,只调整最后几层(比如分类层),前面的知识保持不变。
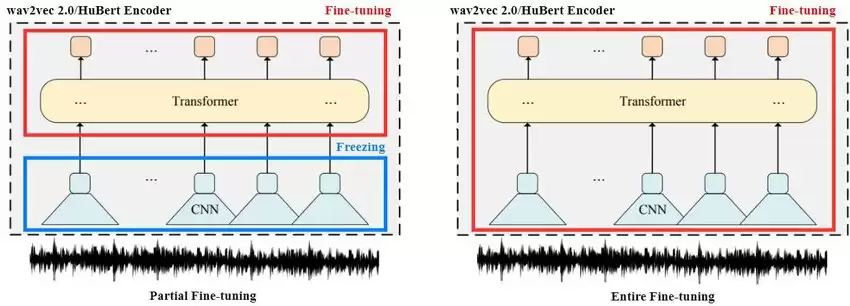
- 具体方法:
加载预训练模型。 冻结模型的前几层(比如BERT的前10层),只解冻最后几层(如分类层)。 用新任务的数据训练解冻的部分。 在验证集上评估性能,必要时调整解冻的层数。
- 优点:节省计算资源,训练速度快。
- 缺点:如果新任务与预训练任务差异过大,效果可能打折扣。
- 适用场景:新任务与预训练任务相似(比如文本分类)。
3. 适配器微调(Adapter Fine-Tuning)
- 通俗理解:不想动原来的“大脑”,而是给它添加一些小插件(适配器)。这些插件专门处理新任务,旧知识纹丝不动。
- 具体方法:
在模型的每一层中插入小型神经网络模块(适配器),通常是一个两层的前馈网络。 冻结预训练模型的参数,只训练适配器模块。 在训练过程中,适配器模块学习如何调整模型的中间表示以适应新任务。
- 优点:非常节省资源,适合多任务学习。
- 缺点:插件可能不够灵活,效果不如全参数微调。
- 适用场景:资源有限,且需要同时处理多个任务(比如多语言翻译)。
4. 提示微调(Prompt Tuning)
- 通俗理解:不想动“大脑”,而是通过改变提问方式(提示词)来引导它给出想要的答案。比如问“这部电影好看吗?”和“这部电影有多好看?”可能会得到截然不同的回答。
- 具体方法:
设计提示词模板(Prompt Template),比如“这部电影的情感是:[MASK]”。 将提示词与输入数据结合,输入到预训练模型中。 让模型填充空白部分(如[MASK]),并根据填充结果判断情感。 可以通过调整提示词的设计来优化模型性能。
- 优点:不需要训练模型,简单直接。
- 缺点:提示词设计依赖技巧,效果可能不稳定。
- 适用场景:少样本或零样本学习(数据很少)。
5. 前缀微调(Prefix Tuning)
- 通俗理解:在输入问题之前添加一段“引导词”(前缀),这段前缀是专门训练过的,用来告诉模型该如何回答。
- 具体方法:
在输入前添加一段可训练的前缀向量(Prefix Vector)。 冻结预训练模型的参数,只训练前缀向量。 前缀向量会引导模型生成符合任务要求的输出。
- 优点:比提示微调更灵活,效果更好。
- 缺点:需要训练前缀,稍微复杂一些。
- 适用场景:生成任务(比如文本生成)。
6. 低秩适应(LoRA, Low-Rank Adaptation)
- 通俗理解:不想动整个“大脑”,而是用一种更高效的方式(低秩矩阵)来调整它的行为。就像用一个小工具来微调机器,而不是拆开整个机器。
- 具体方法:
在模型的权重矩阵中加入低秩矩阵(Low-Rank Matrix)。 冻结原始权重,只训练低秩矩阵。 低秩矩阵通过矩阵分解(如SVD)来减少参数量。
- 优点:节省计算资源,适合大规模模型。
- 缺点:需要一定的数学知识来理解低秩矩阵。
- 适用场景:大规模模型微调(比如GPT-3)。
7. 知识蒸馏(Knowledge Distillation)
- 通俗理解:有一个很厉害的“老师模型”,它教一个“学生模型”如何完成任务。学生模型更小、更快,但效果接近老师。
- 具体方法:
训练一个大型的“老师模型”。 用老师模型的输出(软标签)来训练一个更小的“学生模型”。 学生模型通过学习老师模型的输出分布来模仿其行为。
- 优点:适合资源有限的情况,学生模型更轻便。
- 缺点:学生模型的效果可能不如老师。
- 适用场景:模型压缩或部署到资源受限的设备(比如手机)。
8. 持续学习(Continual Learning)
- 通俗理解:不断学习新任务,但不想忘记以前学过的内容。就像一边学做饭,一边不忘怎么开车。
- 具体方法:
使用正则化技术(如EWC,Elastic Weight Consolidation)来保护重要参数。 使用记忆回放技术,定期复习旧任务的数据。 使用模型扩展技术,为每个任务分配独立的参数。
- 优点:适合需要处理多个任务的场景。
- 缺点:容易遗忘旧知识,需要特殊技巧来避免。
- 适用场景:多任务学习或动态任务环境。
9. 多任务学习(Multi-Task Learning)
- 通俗理解:同时学习多个相关任务,比如学做饭的同时也学怎么买菜。这样可以互相促进,学得更快。
- 具体方法:
设计一个共享的模型架构,多个任务共享部分参数(如BERT的底层)。 为每个任务设计独立的输出层(如分类层)。 同时训练所有任务,通过损失函数加权来平衡任务之间的重要性。
- 优点:适合任务之间有共同点的情况,效果更好。
- 缺点:如果任务差别太大,可能会互相干扰。
- 适用场景:任务之间相关性较强(比如文本分类和情感分析)。
10. 领域自适应(Domain Adaptation)
- 通俗理解:以前学的是做中餐,现在要学做西餐。虽然都是做饭,但调料和做法不一样,所以需要调整一下。
- 具体方法:
使用目标领域的数据微调模型。 使用领域对抗训练,通过对抗网络减少领域差异。 使用领域特定的适配器来调整模型。
- 优点:适合领域差异较大的任务。
- 缺点:需要一定的目标领域数据。
- 适用场景:跨领域任务(比如从新闻文本迁移到医学文本)。