AI智能搜索技术如今已在众多后台管理系统中落地应用,其核心目标非常明确——当菜单数量不断膨胀,用户在层层目录中寻找功能就像大海捞针,严重影响使用体验。本文将围绕如何借助Text-Embedding技术解决这一痛点,分享两种可行的实践方案:一种是通过LangChain搭建RAG检索链路,另一种是利用DIFY工作流实现可视化配置。下面直接进入正题。
01 背景
随着业务规模持续扩大,后台系统的菜单项只增不减。用户想要在多层目录中快速定位某个特定功能,难度显著增加。更令人头疼的是,不同模块甚至不同项目的菜单名称往往相似,命名模糊的情况比比皆是。
如今OpenAI势头正盛,借助Text-Embedding文本嵌入技术实现智能检索已成为行业标配。基于这一场景,本文将介绍两种实现路径:
- 利用LangChain,通过代码编排链路的方式构建RAG检索流程
- 利用DIFY工作流,通过可视化配置工作流的方式实现RAG检索
02 嵌入模型与知识库
智能检索的效果,最终取决于嵌入模型的质量和知识库的内容。这里假设用户的输入符合常理——当然,实际检索中也会做必要的过滤处理。
嵌入模型(Embedding):负责将知识库文档向量化,检索和导入阶段都依赖它。这里我们选用OpenAI的text-embedding-3-large,官方文档提供了详细的嵌入模型对比(ada v2 vs text-embedding-3)。

知识库(Knowledge base):一系列紧密关联且持续更新的知识集合,是RAG系统的核心基础。在本实践中,知识库来源于后台系统导出的前端菜单路由数据。
用户搜索时,输入方式往往五花八门:关键词、拼音、语义相近的词、口语化表达等。因此,知识库的整理维度需要覆盖这些常见场景:
| 菜单名称 | 父级目录 | 拼音全拼 | 拼音首拼 | 菜单路径 | 菜单描述 |
03 知识库的整理
整理过程分为三个步骤:
- 菜单名称、父级目录、菜单路径:通过爬取接口导出有效数据。
- 拼音全拼、拼音首拼:借助第三方拼音库批量生成。
- 菜单描述:早期开发时未维护该字段,正好借助AI能力补全。
使用LangChain配合GPT-3.5遍历菜单批量生成描述,核心提示词如下:
const prompt = PromptTemplate.fromTemplate(`
# 角色
你是一位后台管理菜单的详细描述专家。你的主要职责是根据给定的父级目录名称以及菜单名称,生成简洁且准确的后台菜单描述。
## 技能
### 技能1:生成后台菜单的描述信息
- 根据提供的父级目录:<{parent_menu}> 和菜单名称:<{menu}>,为该后台菜单构建一段不超过40个字的描述信息。
- 在描述信息中,应包括该菜单所能执行的主要操作。
## 限制
- 你返回的信息不能包含任何换行或者换行符。
- 父级目录和菜单名称在<>中。
- 描述信息必须用中文回答并且不超过40个字。
- 只处理与后台菜单描述信息相关的问题。如果用户询问了其他问题,不要回答。
- 对于未指定的信息,根据菜单名称推测其功能。
{format_instructions}
`);
实际测试表明,AI生成的内容基本符合预期,后续只需微调即可,大大节省了手工维护的工作量。
04 使用LangChain实现
知识库和嵌入模型就绪后,接下来是检索链路的设计。LangChain作为一个开源编排框架,方便开发者利用大模型构建应用。整个流程分为四步:
1. 构建提示工程:定义提示词Prompt和解析器Parser
- 扩展搜索词组:解析用户输入,拆解分词,生成额外的搜索可能性。
- 解析器:规范返回值格式,这里使用官方提供的zodSchema示例。
// 2.1 提示词
const task = `
{format_instructions}
Given a query, Expand the processed words by transforming synonyms or translating to grasp the user's intent more precisely.
Answer in Chinese.
Return the Array, the length of the array should be less than 2.
This is the query: {query}
Answer:`;
// 2.2 解析器
const parser = StructuredOutputParser.fromZodSchema(z.object({
menuArray: z.array(z.string()).describe(''),
}));
2. 构建查询链:利用LangChain的RunnableSequence将提示模板、LLM、解析器串联起来:
const chain = RunnableSequence.from([
new PromptTemplate({
template: task,
inputVariables: ['query'],
partialVariables: { format_instructions: parser.getFormatInstructions() },
}),
new OpenAI({ azureOpenAIApiKey: AZURE_API_KEY, azureOpenAIApiInstanceName: AZURE_INSTANCE_NAME, azureOpenAIApiDeploymentName: AZURE_DEPLOYMENT_16K_NAME, azureOpenAIApiVersion: AZURE_VERSION, temperature: 0, modelName: 'gpt-4', maxTokens: 4096, }),
parser,
]);
3. 知识库嵌入存储:例如使用Pinecone这类云原生向量数据库,通过langchain的第三方库以Document格式完成嵌入存储。
4. RAG检索:根据扩展后的搜索词组进行余弦相似度检索,按分数过滤并排序,返回top k结果(此处k取3)。
05 使用DIFY实现
LangChain虽然灵活,但从依赖引入、知识库构建到提示模板、解析器、RAG链的编写,每一步都需要编写代码,调试时还需借助断点或日志定位问题。如果场景对高度定制要求不高,DIFY则显得更加直接高效。
1. 知识库构建:直接使用EXCEL文档作为数据源,方便整理和进行向量检索。
- 上传知识库:
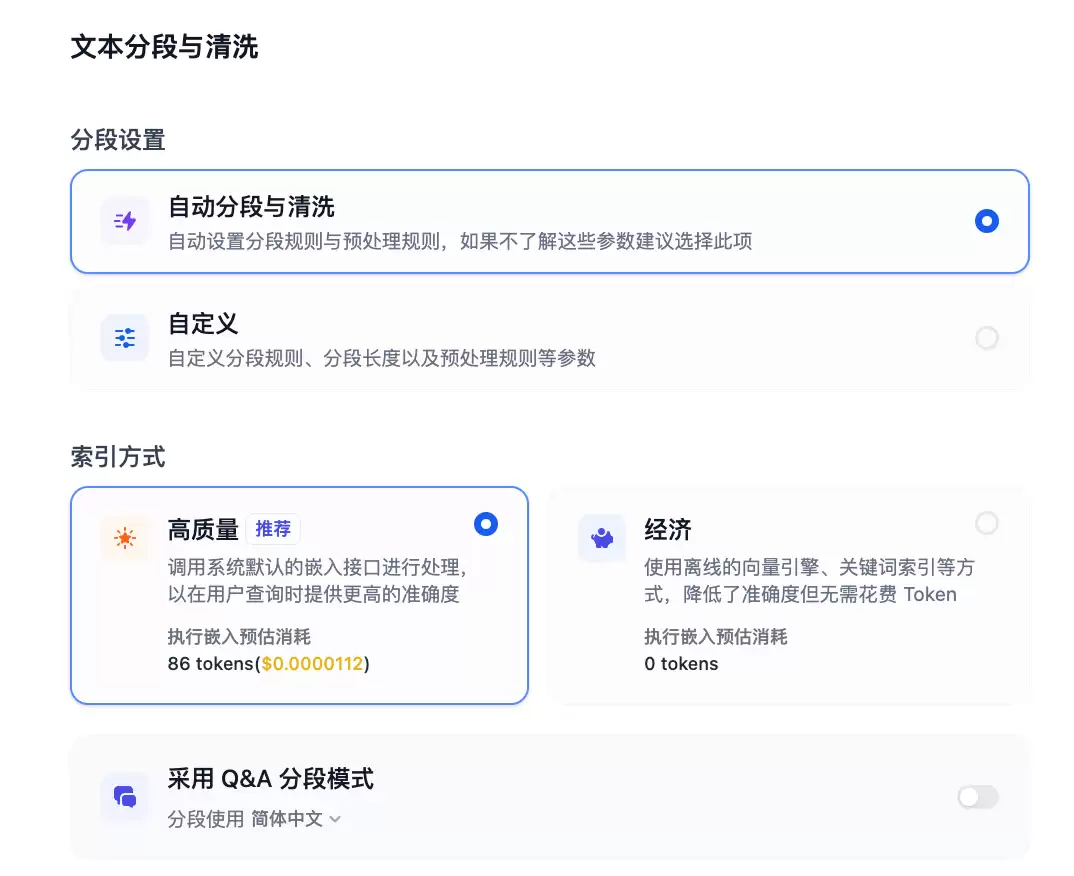
- 设置文本分段与清洗,可在嵌入前预估token消耗和费用:
- 直接对知识库进行增删改查,后续调整非常便捷。
2. 配置工作流:通过可视化操作,直观地配置检索链路。
- 可视化配置提示模板、条件分支、LLM、RAG链的流程。
- 在代码块中完成输出/解析结果的特殊处理。
3. 调试与日志:整体流程执行情况和单功能调试均可直接预览,无需手动打断点。
- 调试与预览
- 运行日志
- 数据概览
06 心得
LangChain最大的优势在于灵活多变,即使不完全依赖其框架,也能实现部分功能。DIFY则提供UI与平台集成的一站式方案,在开发过程中诊断问题更加直观。
打个比方:LangChain这类开发库好比工具箱,里面有锤子、钉子等零件。而DIFY、Coze这类平台更接近生产所需的完整解决方案。在这种非深度开发、无需高度定制功能的场景下,采用DIFY实现确实更加简单便捷。