专为机器学习/人工智能打造的硬件,正在成为一条拥挤的赛道。英伟达凭借GPU和CUDA组合几乎一统江湖,甚至把英特尔甩在了身后。但事情正在起变化——最快今年,慢则两三年内,机器学习的硬件格局可能会被改写。
过去十年,机器学习专用硬件的研究突飞猛进,从训练到推理,从延迟到功耗,每个环节都能感受到硬件优化的力量。目前,英伟达GPU是公认的通用解决方案,这也推高了它的估值。不过,有四个因素正在撼动它的王座。而且摩尔定律的终结,让芯片行业从通用转向专用,这恰好为新的硬件玩家打开了大门。
先看一个典型的机器学习管线:
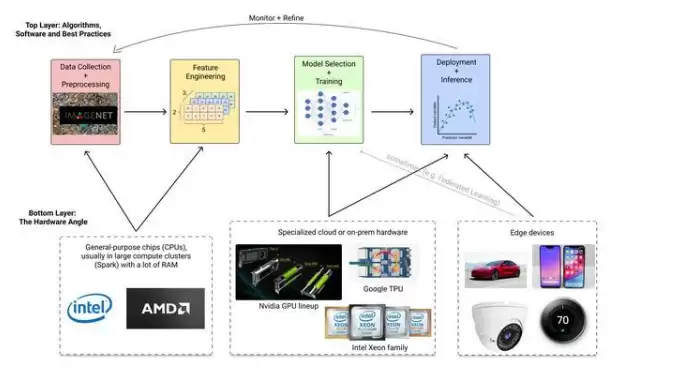
英伟达的崛起颇有戏剧性。上世纪90年代初,它只是一家做游戏显卡的公司,目标是画出更快的3D图像。在与AMD的持续交锋中,它造出了市面上最强的GPU。谁能想到,这些为电子游戏打造的硬件,竟成了深度学习起飞的关键。而CUDA,让英伟达在同行的基础上多了一道护城河。2006年第一个CUDA工具包发布,2009年斯坦福教授吴恩达与合作者发表论文,指出GPU能让大规模无监督深度学习成为可能。一年后,吴恩达和Sebastian Thrun向拉里·佩奇提议组建谷歌深度学习团队——后来的Google Brain。随着Google Brain崛起和“Imagenet时刻”到来,英伟达GPU顺理成章成为AI/ML行业的计算标准。
现状:CUDA筑起的高墙
英伟达能主导深度学习硬件,CUDA功不可没。据福布斯报道,2019年5月,前四大云计算供应商在97.4%的IaaS计算实例中都部署了英伟达GPU,且配备专用翻跟斗。竞争对手也没闲着:谷歌2015年就造出了TPU,专门为神经网络打造,在特定任务上比GPU更快更便宜,但被封闭在GCP生态系统里,仅支持TensorFlow和PyTorch;AWS押注自己的Inferentia芯片,开发者从CUDA切换的难易度决定了它的成败;英特尔2019年花20亿美元收购Habana Labs,上个月AWS宣布将推出基于Habana芯片的EC2实例,宣称比当前GPU实例提供高达40%的价格性能提升;AMD则在2020年收购了发明FPGA的Xilinx,开始切入AI翻跟斗芯片。
对AI算力的需求还在加速。但英伟达的统治地位,正在被四个方向侵蚀。
变化与机遇
1. 学术研究正在变成真正的产品
学术界和工业界的研究人员创办了一批初创公司,它们不再只发论文,而是拿出了真实的硬件原型,指标比商用方案更漂亮。这个领域的芯片种类很多,每个都有活跃的研究社区:
专用集成电路(ASIC):谷歌TPU、AWS Inferentia都是例子。研发成本可能高达5000万美元,但复制边际成本极低,还能做到低功耗。现场可编程逻辑门阵列(FPGA):高频交易者早已熟悉,机器学习方面有微软Brainwa ve、英特尔Arria。单颗FPGA生产成本低,但多颗成本高于ASIC。神经形态计算:试图模仿人脑生物结构,虽然概念可追溯到80年代,但还处于早期。Nature上有篇很好的综述。
值得关注的初创公司:Blaize在2019年宣称开发出可编程低功耗处理器,延迟降低10倍,系统效率最高提升60%;SambaNova Systems由斯坦福教授和前甲骨文高管创立,获得谷歌风投和英特尔资本投资,刚发布一个完整集成的软件硬件系统平台;Graphcore是英国初创,红杉、微软、宝马、DeepMind创始人领投。
2. 摩尔定律终结,专用硬件是必然方向
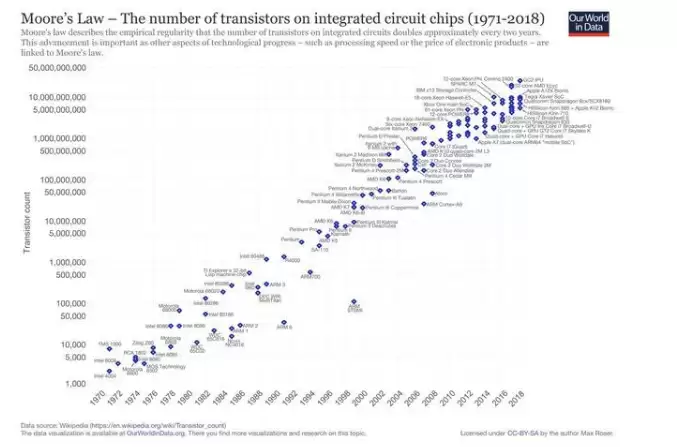
摩尔定律说芯片上的晶体管每两年翻一番,这维持了将近半个世纪的进步。但现在,“缩小芯片越来越难,且好处今非昔比”。英伟达创始人黄仁勋直言“摩尔定律已不再可能”。麻省理工学院经济学家Neil Thompson在《MIT科技评论》上解释:软件和专业架构的进步将开始针对特定问题和商业机会,只对资金充足的玩家有利,而不是像摩尔定律那样“水涨船高”地普惠所有人。这意味着计算硬件将分裂成“快车道”和“慢车道”——前者用强大定制芯片,后者被卡在通用芯片上,进展缓慢。
分布式计算常被当作解决方案——用大量廉价资源替代昂贵芯片。但连这种方案也越来越贵,分布式梯度下降的复杂性更是雪上加霜。2018年CMU的研究人员在Nature上发表论文,认为私营部门追求短期盈利,难以为摩尔定律找到通用继承者,呼吁公私合作。但更现实的未来是:计算硬件将是一组专用芯片的集合,协同工作时比现在的CPU更通用。苹果向自研芯片的转型已经迈出这一步——软硬件集成系统优于传统芯片。特斯拉也在自动驾驶中使用自有硬件。我们需要大量新玩家涌入硬件生态,让专用芯片的好处大众化,而不再局限在昂贵的笔记本、云服务器和汽车上。
3. 成本上涨让创始人和投资者焦虑
Andreessen Horowitz的Martin Casado和Matt Bornstein在去年初指出,AI业务与传统软件不同,说到底一切都与利润有关。云计算基础设施对AI公司是巨大成本,有时还是隐性成本。训练一个模型可能花费数千美元(如果是OpenAI就得数百万),但成本远不止这些。AI系统需要持续监控和改进。离线训练的模型容易出现概念漂移——现实世界的数据分布随时间变化,比如用户试图欺骗信用风险算法时。一旦出现,就必须重新训练。虽然业界在努力研究减少概念漂移的方法,以及创建更小但性能相当的模型,但另一面,行业正在推动更大的模型和更大的计算支出。更便宜、更专业的AI芯片无疑能降低这些成本。
4. 训练大模型的气候变化代价
马萨诸塞大学阿默斯特分校的研究发现,训练一个现成的自然语言处理模型,碳排放量相当于从旧金山飞往纽约的一次航班。三大云计算供应商中,只有谷歌的数据中心超过50%的能源来自可再生能源。现有芯片耗电量过大,而FPGA、超低能耗芯片(如谷歌TPU Edge)在机器学习中能更节能。甚至连地理位置都能影响碳排放——斯坦福研究人员估算,在主要依赖页岩油的爱沙尼亚举办一次会议,碳排放量是在水力发电为主的魁北克举办的30倍。
减少AI的碳排放不需要再多解释。关键在于,更高效的专用硬件可以大幅降低能源消耗。谷歌最近申请了一项专利,用强化学习确定跨多个硬件设备的机器学习模型操作位置,背后是Google Brain负责机器学习硬件/系统登月计划的研究员Azalea Mirhoseini。这或许只是个开始。