在机器学习领域,决策树算法既备受欢迎又极具实用性,堪称分类算法中的经典代表。如其名称所示,它的运作方式与人类决策过程高度相似——根据已有数据,逐步挑选出最具区分能力的特征,将数据集划分为不同分支,整个逻辑与人类的思维路径极为贴近。
要高效构建一棵决策树,通常需借助熵(信息增益)与基尼不纯度这两个核心概念。今天我们将重点解析基尼不纯度,阐述其本质,并探讨如何利用它来搭建决策树模型。
基尼不纯度究竟指什么?
简而言之,基尼不纯度是决策树算法中用于确定根节点(以及后续节点)如何进行分裂的一种评估指标。它是一种最常见且最直观的分裂方法,由于仅支持二分叉,因此仅适用于分类任务。
其数学表达式如下:
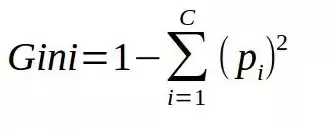
该值越低,表示节点内部的纯度越高。一个纯节点(即所有样本均属于同一类别)的基尼不纯度等于0。接下来,我们借助一个实际数据集进行演算。
假设有18名学生,其中8名男生和10名女生。根据课堂表现,将他们划分为两类:高于平均水平与低于平均水平。
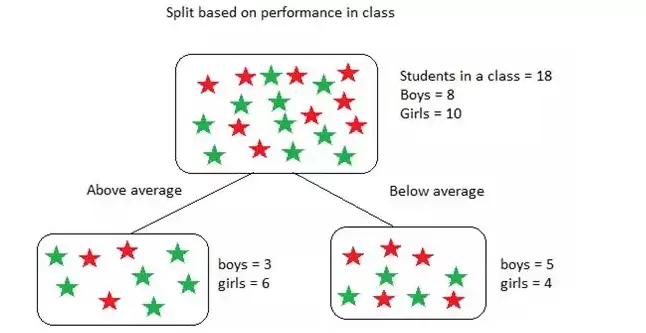
基尼不纯度的具体计算方法如下所示:

在计算过程中,为了得到某个分裂(例如根节点)的加权基尼不纯度,需要用到子节点中学生数量的比例。“高于平均值”与“低于平均值”两个子节点的人数恰好均为9人,因此概率同为9/18。尽管每个节点中男生与女生的人数因表现不同而有所差异,但由于公式中使用的是人数占比,最终结果自然相同。
基于基尼不纯度构建决策树的步骤
此流程与基于熵/信息增益的思路大体一致:
- 第一步:针对每一次可能的分裂,分别计算每个子节点的基尼不纯度。
- 第二步:将各子节点的基尼不纯度按加权平均合并,得到该分裂的整体基尼不纯度。
- 第三步:选择基尼不纯度最低的那个分裂方案。
- 第四步:重复上述步骤,直至每个节点都成为纯节点。
基尼不纯度小结
- 它能够帮助我们确定根节点、中间节点以及叶节点,从而完成整棵决策树的构建。
- CART(分类与回归树)算法在进行分类任务时,正是采用基尼不纯度作为分裂标准。
- 当一个节点中所有样本均属于同一类别时,基尼不纯度达到最小值(0)。
值得注意的是,在实际应用场景中,基尼不纯度往往比熵/信息增益更受青睐。原因在于其公式简洁,无需涉及对数运算,计算量显著更小。尤其在处理大规模数据集时,这一优势显得尤为实用。