当提及AI应用开发时,许多开发者的本能反应往往是:
是否必须转型为算法工程师?
是不是需要从头学习训练框架、研读论文、进行微调、攻克分布式训练?
这些技能固然重要,但对大多数正在编写业务系统、后端服务、前端产品、测试平台以及从事工程交付的开发者而言,更切实的转型方向并非“从零开始成为算法研究员”。
而是将已有的工程判断力,迁移到AI应用这种新型系统上。
先给出一个核心观点:AI应用工程并非抛弃软件工程经验,而是对其进行升级。
考虑一个常见需求。产品团队提出:我们要开发一个智能客服。
第一版可以快速搭建:接入一个模型API,编写一段prompt,准备几份FAQ,前端增加一个聊天框。Demo看起来已经可用。
然而一旦面对真实用户,熟悉的问题便会涌现:
- 用户提问方式不可控
- 模型回答不稳定
- FAQ更新后旧答案仍在生效
- 某些问题需要查询订单、权限、工单
- 单次回答失败后是否需要重试
- 多个模型供应商之间如何切换
- 用户数据能否放入prompt
- 成本突然激增应归因到哪个功能
- 线上事故如何回滚
- 某个回答到底算不算正确
这些问题表面上属于AI范畴,但仔细分析就会发现,它们非常像传统软件工程问题——接口、缓存、消息、数据库、网关、日志、指标、权限、测试、发布、回滚。只不过现在中间多了一个大模型。
这个模型能力很强,但不确定性也很突出。它能生成自然语言,能理解上下文,能调用工具,能辅助写代码。但它也会漂移、遗忘、产生幻觉、受上下文影响,还会把成本隐藏在token中。
因此,开发者转向AI应用工程,真正需要迁移的不是某个框架API,而是过去在工程实践中磨练出的判断力。
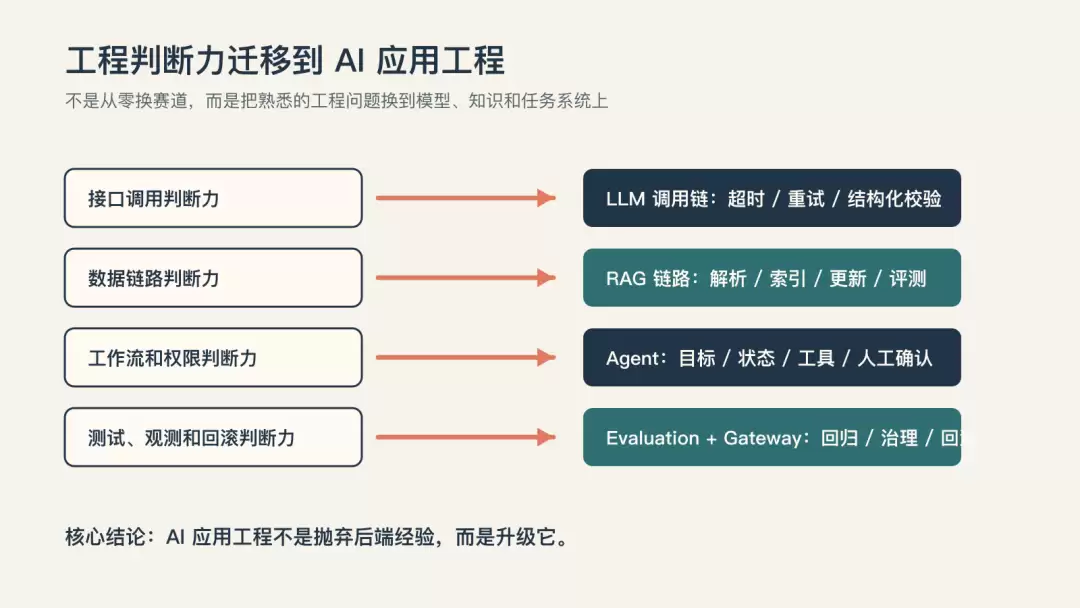
一、别把AI应用开发误解为“转算法岗”
有一个值得保留的定位:它并非只面向算法同学,而是面向后端、前端、测试、架构师、技术管理者以及产品技术同学。这一定位至关重要。
如今很多开发者一听到AI应用开发,就自动脑补另一条路径:先学数学,再学深度学习,再学训练框架,再看论文,最后才能做AI项目。这条路线确实存在,但它并非所有人进入AI应用工程的唯一入口。
如果你的目标是训练基础模型、从事算法研究、优化模型架构,那么确实需要深厚的算法和训练能力。但如果你的目标是将AI融入真实产品、实际业务系统、真实研发流程,那么你首先面临的是另一组问题:
- 模型调用链路如何设计
- 私有知识如何注入模型
- 工具调用如何控制权限
- 长任务状态如何保存
- 回答质量如何评测
- 多模型如何路由和降级
- 成本如何归因
- 线上行为如何观测
- 出错后如何回滚
这些问题不是靠背诵几篇论文就能解决的,它们更接近工程本质。也正因如此,普通开发者并非没有优势。过去在接口设计、系统重构、数据库优化、消息队列、缓存一致性、灰度发布、线上排障、CI/CD、代码review等方面的经验,都可以迁移过来。
AI应用工程不是另起炉灶,而是在软件系统中接入一个新型能力层。
二、LLM API仍然是一条服务调用链
许多AI项目的第一步是调用模型。这一步很容易让人产生错觉,因为模型API看起来太像聊天框了——传入一段messages,返回一段answer。于是团队很容易将其视为“更聪明的字符串函数”。
但一旦进入生产系统,它仍然是一条服务调用链,就会遇到老问题:超时、重试、限流、取消、幂等、降级、日志、监控、费用、错误分类。
只不过这条链路多了一些AI特有的问题:上下文窗口可能被截断、采样参数影响稳定性、JSON可能不合法、Function Calling可能选错工具、流式输出中途可能断开、同一个prompt在不同模型上表现不同、token成本需要单独记录。
此时,有经验的后端开发者会自然地问:这个调用有没有超时策略?返回结构在哪里校验?失败后是重试、fallback,还是直接报错?用户取消请求时,后端是否中断下游调用?模型返回半截内容时,状态如何处理?
这些问题一点也不“AI炫技”,但它们决定了AI功能能否进入生产环境。所以,学习LLM API时,不要只学“怎么调通”,要把它看作一条新型RPC。调用对象不是数据库,不是搜索服务,不是支付网关,而是模型。但工程纪律并未消失。
三、RAG最像数据工程,不是向量库采购
第二个容易被误解的是RAG。很多人一提到RAG,就立刻想到向量数据库——选Milvus还是pgvector?Embedding用哪个模型?相似度阈值设多少?这些当然重要。但RAG在实际项目中更像一条数据工程链路。
你需要先回答:文档从哪里来?PDF、网页、表格、图片、Markdown、工单、会议纪要如何解析?脏数据如何清洗?Chunk如何切分?元数据如何保留?文档更新后如何增量同步?旧版本如何下线?用户问法变化时,query是否需要改写?关键词检索和向量检索如何混合?召回结果要不要rerank?答案引用如何追溯到原文?
RAG答非所问时,很多团队的第一反应是换模型。但工程上更靠谱的做法,是先排查链路:是不是文档解析出了问题?是不是Chunk切得太粗?是不是召回了相似但不相关的段落?是不是缺少关键词检索?是不是上下文组织把关键材料挤掉了?
这很像传统数据系统。一个报表算错,不一定是数据库不行,可能是ETL错了、字段口径错了、维表没更新、数据延迟,或者查询条件写偏了。RAG也是一样——向量库只是中间一环,真正的工程能力,是能把知识进入模型这条链路拆开、观测、评测、修复。

四、Agent最需要的不是自由,而是责任边界
Agent是最容易让人兴奋的一层,因为它看起来终于不是“问一句答一句”了。它能规划、能调工具、能读文件、能查资料、能写代码、能循环推进任务。但从工程角度看,Agent越能做事,就越需要明确责任边界。
一个Agent能否删除文件?能否发送邮件?能否修改数据库?能否调用付款接口?能否将用户隐私放入第三方模型?能否绕过测试直接提交代码?这些都不是模型能力问题,而是权限、审计、状态和人工确认问题。
在传统系统里,一个服务能做什么,通常由接口权限、角色、配置、审批流和审计日志控制。Agent也一样,只不过它的行动空间更大。如果不设计边界,它可能会用看似合理的方式把任务推进到危险位置。
所以,Agent工程里最重要的不是“让它更自由”,而是让它在合适的边界内持续推进。它需要明确:目标是什么、哪些工具可用、哪些数据不能碰、中间状态保存在哪里、失败后如何恢复、哪些节点必须等待人工确认、最后要留下什么轨迹供review。
这和我们过去做工作流、审批、任务系统、CI/CD很像。区别在于,以前流程节点大多是确定代码,现在节点里多了模型判断。模型判断可以提升效率,也会放大不确定性,因此更需要工程结构兜底。
五、Context Engineering是新的信息架构能力
Prompt Engineering曾经是很多人学习AI的入口,但越往后做,越会发现prompt只是其中一小块。真正影响模型输出的,是它在这次调用前看到了什么:项目规则、用户目标、历史状态、检索材料、工具结果、错误日志、验收标准、安全限制。
这些东西如何组织,决定了模型表现。所以Context Engineering其实很像新的信息架构能力。开发者需要判断:哪些信息应该常驻?哪些应该按需加载?哪些应该只保留摘要?哪些应该用结构化格式给模型?哪些过期信息应该移出上下文?哪些约束应该写进项目规则,哪些只该放在本次任务里?
这和传统工程里的配置、文档、缓存、状态管理并不陌生,只是对象变了——以前我们给人组织信息,现在还要给模型组织信息。如果上下文太少,模型会缺失关键事实;如果上下文太多,模型会被噪声稀释;如果上下文过期,模型会沿着旧状态继续错;如果上下文没有结构,模型会把重要约束当成普通背景。
学AI应用工程不能只学prompt技巧,真正要练的是:在有限token预算里,把当前任务最该看的信息放到最清楚的位置。
六、评测和网关,是demo到生产的分水岭
一个demo能跑,不代表一个AI应用能上线。这句话对所有工程系统都成立,AI应用只是更明显——因为它的输出不像传统函数那样稳定。传统接口如果返回错,通常可以用断言、单测、集成测试、日志和错误码定位。AI输出错的时候,团队经常只剩一句话:感觉不太对。
这就是评测要解决的问题。你需要Golden Set,需要LLM-as-Judge,需要人工抽检,需要Trace回放,需要RAG召回评测,需要Agent过程指标,需要把关键样本放进CI或发布前回归。评测不是给AI打个分,评测是AI应用的回归系统。
同样,网关也不是锦上添花。只要AI功能接入业务流量,就会遇到:多模型供应商、模型路由、fallback、限流、Token预算、成本归因、缓存、审计、安全策略、数据隔离。这些问题不解决,AI功能就会停在“能演示”;解决了,才有机会进入“能运营”。
所以可以把评测和网关看成生产分水岭——前者回答“这个系统质量能否被持续判断”,后者回答“这个系统运行能否被持续治理”。
七、AI Coding也在考验同一套工程判断力
AI Coding是另一条很重要的支线。Claude Code、Codex、Cursor、Trae、Qoder,各种工具越来越强,但真正拉开差距的常常不是“哪个工具最强”,而是开发者怎么用它。
同一个模型,有人让它一口气改几百行代码,然后自己在diff里迷路;有人会先写清楚任务范围,再给相关文件,再让它小步修改,再跑测试,再review,再提交。结果完全不一样。
AI Coding表面看是写代码,底层还是研发流程。你需要判断:这个任务适合交给CLI还是IDE?现在该让AI写代码,还是先让它读代码?任务范围能不能再拆小一点?哪些上下文必须给,哪些会干扰?测试应该先补还是后补?diff有没有越界?提交是不是可回滚?失败以后应该继续修,还是回退到上一步?
这些判断,都是工程判断力。AI没有让它们消失,只是让它们更早、更频繁、更集中地出现。
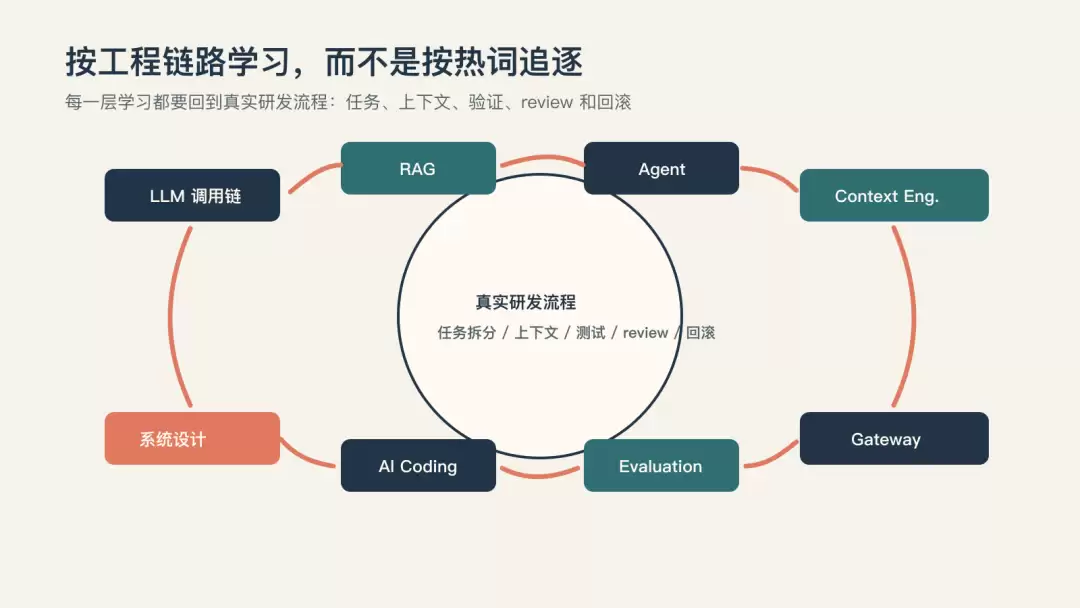
八、下一步怎么学:按工程链路补齐,不按热词追逐
如果你是普通开发者,想系统转向AI应用工程,建议不要按热词追。不要今天学一点RAG,明天学一点Agent,后天看一个MCP,过几天又被新工具带走。更好的方式,是按工程链路补齐。
第一步,学LLM调用链。理解token、上下文窗口、采样参数、结构化输出、Function Calling、流式响应、超时、重试和服务端校验。
第二步,学RAG。不要只学向量库,要学文档解析、切分、索引、混合检索、rerank、知识库更新和RAG评测。
第三步,学Agent。不要只看工具调用,要理解目标、状态、记忆、权限、人工确认、失败恢复和trace。
第四步,学Context Engineering。把prompt、项目规则、检索材料、工具结果、历史状态和验收标准放进同一个信息供给系统里看。
第五步,学Evaluation。从Golden Set、Trace回放、LLM-as-Judge、人工抽检、CI回归和灰度开始,把体感改成可重复判断。
第六步,学Gateway和系统设计。补齐多模型路由、fallback、限流、配额、成本、审计、安全和可观测。
第七步,学AI Coding。不是为了让AI替你写完所有代码,而是把任务拆分、上下文、测试、review和回滚重新组织起来。
这条路线看起来长,但它有一个好处:每一步都能连接你已有的软件工程经验。你不是从零开始,你是在把旧能力迁移到新对象上。
九、收束一下:AI应用工程的主角仍然是工程
回到最初的话题。学AI应用开发,别只背概念;学AI应用工程,也别只追工具。工具会换、模型会换、框架会换,但一些判断不会那么快过时。
用户输入不可信、外部调用会失败、数据口径会漂移、权限要收紧、日志要能查、成本要能归因、测试要能回归、发布要能灰度、变更要能回滚、高风险节点要有人确认。这些东西,放在传统后端系统里成立,放在AI应用里也成立。只是AI应用让它们更难,也更重要。
所以,开发者转向AI应用工程,不要先否定自己过去的积累。真正要做的,是把已有的工程判断力迁移过来:从接口迁移到模型调用,从数据链路迁移到RAG,从工作流迁移到Agent,从配置和文档迁移到Context Engineering,从测试回归迁移到AI Evaluation,从API Gateway迁移到LLM Gateway,从研发流程迁移到AI Coding Workflow。
AI应用开发不是让开发者变成另一个物种,而是让开发者重新理解自己已经掌握的工程能力。