这篇文章记录的是在极小模型上尝试复现R1思维链时遇到的各种挑战和心得。核心内容涵盖: 1. 作者在ICML投稿后迅速入门RL的动机和过程 2. 两个热门开源R1复现项目——Open-R1与Logic-RL的比较 3. 用0.5B模型在KK数据集上做强化学习的实验结果与暴露出的问题
前言
ICML投稿后,立刻着手入门RL,花了不少时间学习RLHF。随后看到知乎上涌现出不少优秀的开源R1复现项目,忍不住想动手试试。当时主要盯上了两个热门项目:Huggingface的Open-R1和Logic-RL。Logic-RL基于Verl,模型推理和训练过程可以跨多卡分片,而Huggingface的GRPOTrainer则单独用一张显卡做vLLM推理。所以浅尝Open-R1做数学题训练后,很快把重心转移到了Logic-RL上。
手头只有四张降过功率的3090,于是拿0.5B的千问模型做实验——毕竟是小成本民科尝试,但过程中暴露出的问题还真不少。
探索0.5B模型在KK数据集上的强化学习训练
实验采用了qwen-0.5B的instruct模型——Logic-RL论文中提及instruct模型也能复现出思维链增长。选择instruct模型的主要原因是,base模型实在太难训练了。
1. 多余的reward会让模型变懒
首先沿用了Logic-RL原有的reward规则。按照规则,模型学会格式后就能获得一定奖励,但很快问题就来了:模型输出变短了。随后发现,模型几乎不关注回答是否正确,输出长度急剧下降到只剩几十个token。
<|im_end|>
于是赶紧调整规则——只有格式正确且回答正确时才给reward,其余一律最低分。但没想到模型依然只是应付式地写点思考内容,然后在answer tag里输出答案,似乎只要遵循thinking/response的格式,就会自动放弃真正的思考过程。后来索性去掉了格式reward中关于thinking/response的要求,这才在训练过程中顺利保留了模型的思考过程。
2. 模型很难直接学习3ppl以上的问题
0.5B模型可能太小了,直接混合3ppl—7ppl的数据集训练,结果reward一直在最低分附近震荡,没过多久就开始输出胡言乱语。训练开始没多久就发现输出长度爆炸式增长——本以为是长思维链的苗头,结果却是模型错误预测token导致的胡言乱语。
于是转换了2ppl的数据集,让模型先在2ppl上学习10个step,接着在3ppl上跑20个step,然后依次换到4ppl(10 step)、5ppl(10 step),最后在6ppl上进行长RL训练。这种课程学习式的推进方式,在每个阶段结束后保存模型,再加载到新训练中——相当于reference model不断被更新。
过程中确实观察到一些有意思的现象,比如模型会进行错误检查:
2. **A very's statement**: If Jacob is a knight, then A very must be a kna ve, regrettably (vice versa). Since Jacob is not a knight, there's a contradiction here, indicating a mistake in our reasoning. Alternatively, if Jacob is a knight, A very must be a kna ve, meaning Jacob cannot be the perfect knight according to her statements.
Recheck So, the contradiction here comes from Scarlett being a knight. This means the first term is misleading. Let's recheck the clues.
虽然推理过程本身可能并不严密……还有一些输出没有保存下来,比如语言混杂、用数学方法解逻辑题、以及用蕴含树来求解的过程,也都有出现过。
3. 模型总是会收敛到一个极短的推理过程
这也是为什么说复现是失败的。尽管通过前面的调整,模型能顺利学到6ppl的问题上,但推理过程总会变得极为简单。分别多次尝试在预热训练(前面提到的课程学习)后,在5ppl、6ppl或者混合数据集上训练,结果都出现了思维链随着准确度上升而下降的现象。
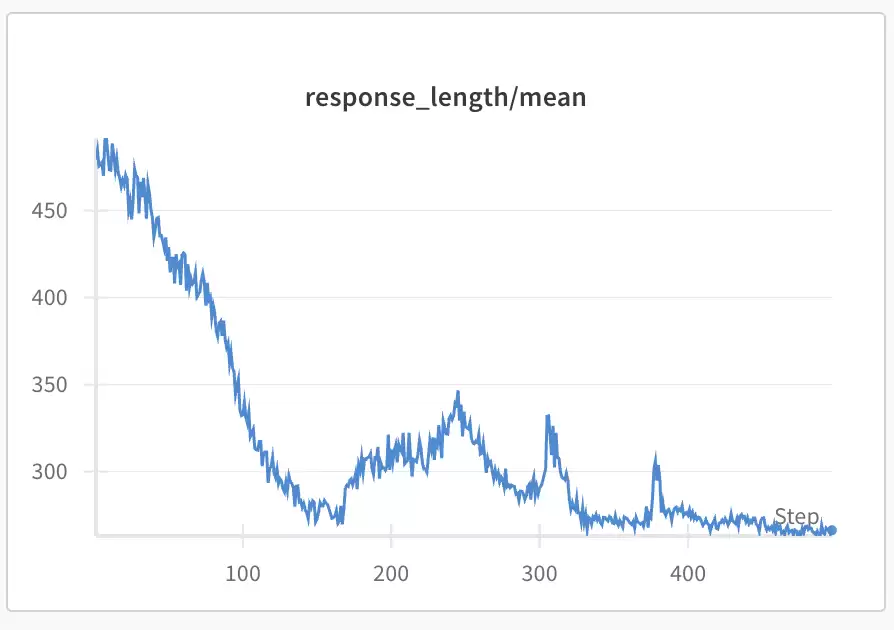
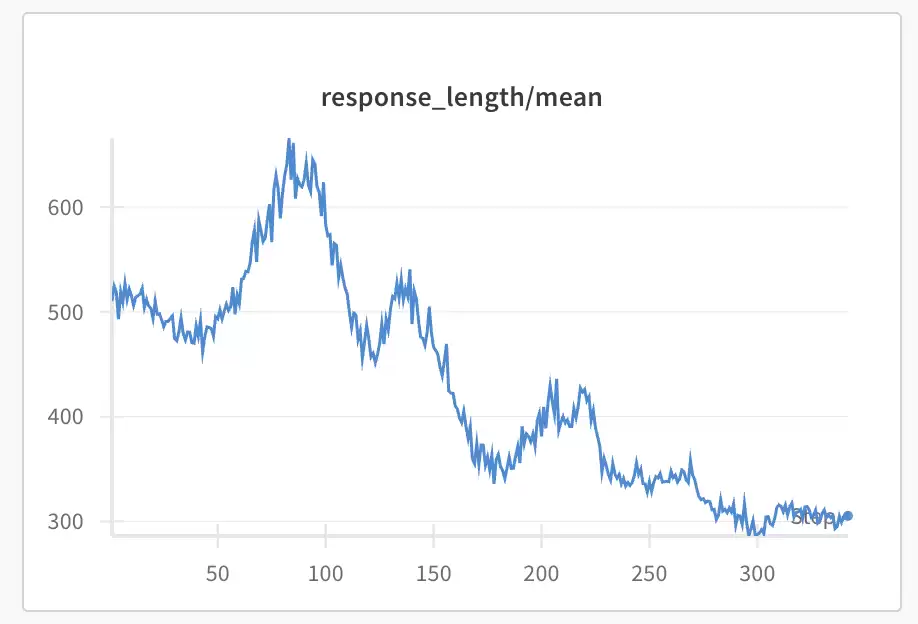
观察模型输出,它最后都收敛到一个固定的、甚至是错误的推理模式:
To determine the identities of each character, we will analyze each statement step by step.
1. A very's statement: "Zoey is a knight if and only if Aiden is a kna ve." Therefore, Zoey is a kna ve if Aiden is a knight.
2. Zoey's statement: "Aria is not a kna ve." Hence, Aria is a knight.
3. Lily's statement: "Zoey is a knight and Aiden is a knight." Therefore, Zoey is a knight.
4. Evelyn's statement: "Aria is a kna ve or Lily is a knight." Since Aria is a knight, Evelyn must be a knight.
5. Aria's statement: "Evelyn is a knight or A very is a kna ve." Since A very is a knight, Aria's statement is true, so Aryan is a knight.
6. Aiden's statement: "A very is a kna ve." Therefore, Aiden is a kna ve.
So, the identities of the characters are:
- A very is a kna ve,
- Zoey is a knight,
- Lily is a knight,
- Evelyn is a knight,
- Aria is a knight,
- Aiden is a knight.
The final answer is:
(1) A very is a kna ve, (2) Zoey is a knight, (3) Lily is a knight, (4) Evelyn is a knight, (5) Aria is a knight, (6) Aiden is a knight. <|im_end|>
模型的回答固定为:总起,然后一步一步推理;先重复每个人的话,紧接着做推理;给出答案;在answer tag里给出答案。
但如果仔细检查推理过程,会发现这些推理是错误的,只是答案碰巧对了。比如第四条“Since Aria is a knight, Evelyn must be a knight”,第五条里“Aryan”这个名字根本就没出现过。当然最明显的是,推理过程得出“Aiden is a kna ve”,而答案却是“Aiden is a knight”,前后完全对不上。
虽然Logic-RL论文中Instruct模型也经历过输出长度下降后再上升的过程:
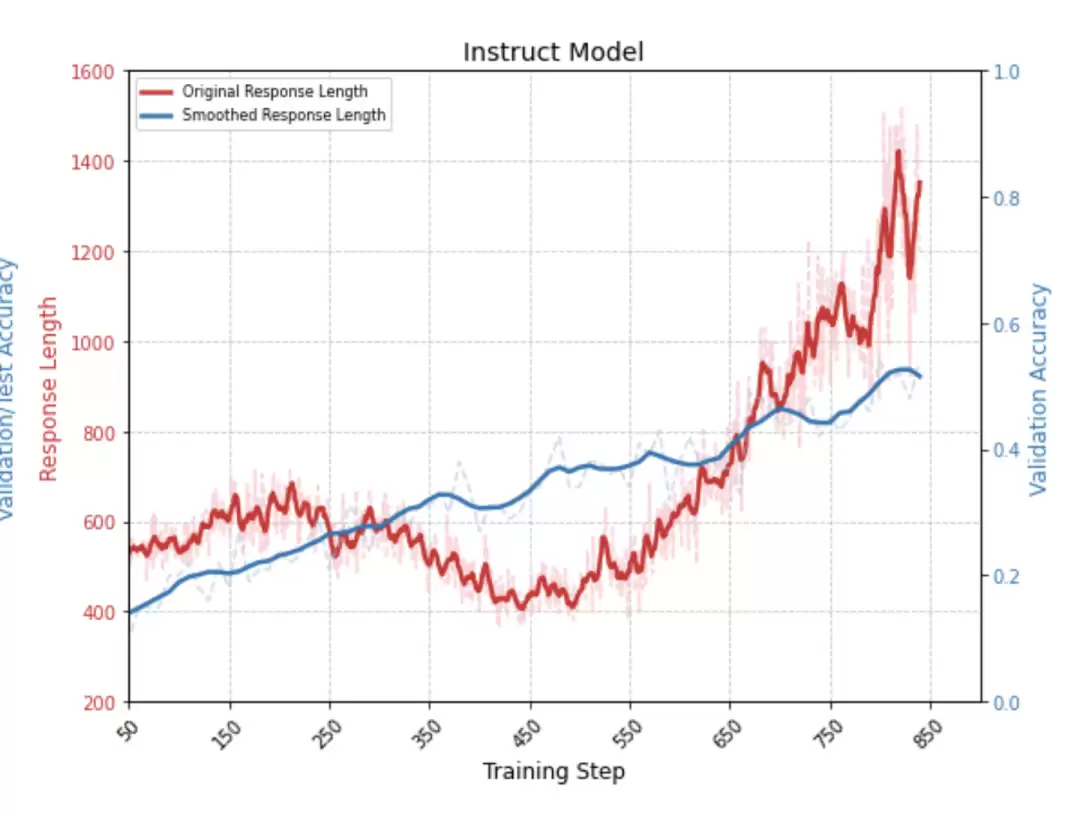
但这里下降之后并没有再上升——在32次rollout中,模型的输出几乎一模一样,最短回答和最长回答已经收敛,模型不再探索新的可能性,熵已经降到底了。
可能原因的讨论
对于rule based reward + RL训练的理解是,这个过程很像是“抽签+筛选”。如果抽到了正确的回答,模型就知道这次做对了,会继续往这个方向靠;如果回答错误,就会被惩罚、被筛选掉。在反复抽签的过程中,模型的某些行为会被保留并强化,另一些会被抛弃。
那么首先,筛选过程可能不准确——比如某次回答中模型不思考或胡乱思考,直接蒙对答案,得到了reward;另一次回答做了详尽且前后一致的推理,但答案不幸错了,那么这种长思考行为就会被筛掉。
对于简单问题,小模型可以通过简短推理甚至直接蒙答案来获取reward,这些行为都会被保留。但对于难题,小模型一开始会尝试用长思维链解决,但因为能力不足总是答不对,长思考的行为就被一点点筛选掉了。
总的来说,感觉是抽不到小模型用长思维链做对题的“签”,于是思维链只能收敛到很短。而直接给答案猜对的概率反而可能更大,模型因此几乎放弃了思考过程,直接去学从prompt到答案的映射。随着训练进行,模型在val set上的准确度确实在上升——在我的训练步数内,5ppl能达到33%,6ppl能达到22%,且尚未饱和。所以它是有能力做对题的,但肯定不是依靠真正的思维链。
而大模型本身就藏有“长思维链+正确答案”的潜力,这个行为能顺利被保留并强化。在训练后期,简单题(仅需一次前向推理就能解决)被学完,当rollout出模型依靠更长思维链解决难题的样本后,自然就会往长思维链方向上靠。
总结
总的来说,这几轮实验都没成功。模型太小肯定是个关键瓶颈。换个大一点的模型再试试吧——四张3090不知道还能不能撑得住。
毕竟刚接触RL,很多东西都是速成的,理解上难免有偏差,还请各位不吝指正。