掌握RAG优化策略,提升智能问答系统性能
本次分享的核心内容,将围绕以下三个关键方面展开:
深入探讨RAG技术在具体实践中面临的挑战,以及切实可行的优化方向。
结合DB-GPT框架,对RAG核心流程的源码实现进行深度解读。
分享知识加工与检索细节的优化方法论,从而有效提升召回准确率。
简而言之,本文将以DB-GPT应用开发框架为依托,探讨在实际落地场景中,如何做好RAG优化工作。
背景
在过去的两年里,检索增强生成(RAG)技术已成为提升智能体能力的关键组件。它通过整合检索与生成的双重能力,引入外部知识,为大模型在复杂场景中的应用开辟了更广阔的前景。
然而,在实际落地过程中,问题也随之涌现:检索精度不足、噪音干扰显著、召回结果不完整、专业深度欠缺……这些问题最终都会导致大模型产生严重的“幻觉”。因此,本次分享的重点,将聚焦于RAG在实际场景中的知识加工与检索细节,探讨如何优化整个RAG Pipeline链路,最终达成提升召回准确率的目标。
坦率地说,快速搭建一个RAG智能问答应用并不困难,但若要将其真正落地到业务场景中,背后需要投入的精力和细节优化工作则非常庞大。
这篇文章,正是对围绕DB-GPT应用开发框架,进行RAG落地优化的一次实战复盘。
一、RAG关键流程源码解读
这部分主要介绍在DB-GPT中,知识加工和RAG流程的关键源码是如何实现的。
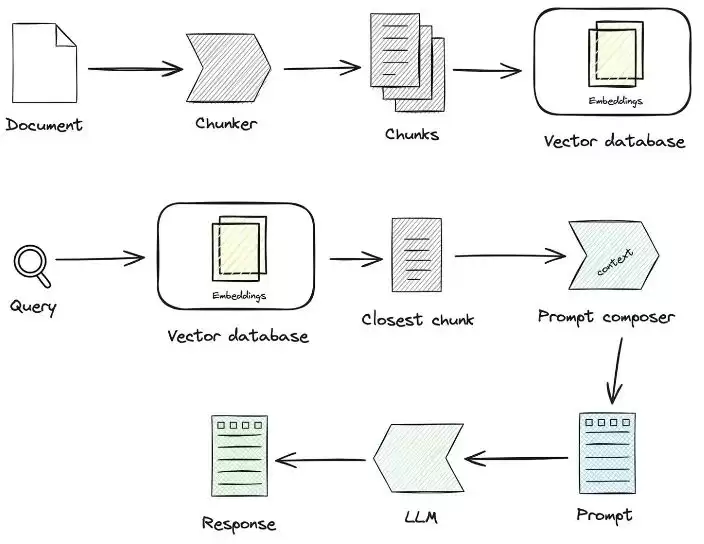
1.1 知识加工
知识加工这条线,可以简要梳理为:知识加载 -> 知识切片 -> 信息抽取 -> 知识加工(embedding/graph/keywords) -> 知识存储。
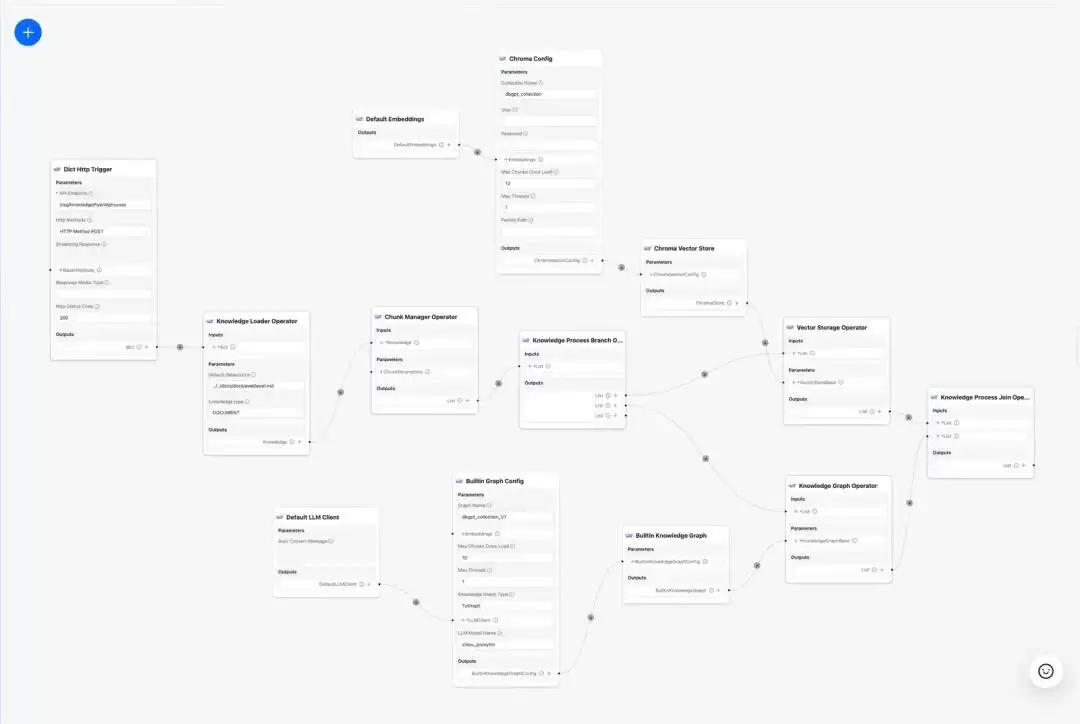
知识加载
这一步是通过“知识工厂”这个类,将各种不同格式的非结构化文档实例化出来。
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
如何进行扩展?方法并不复杂:只需继承Knowledge接口,并实现load()、support_chunk_strategy()、default_chunk_strategy()这些方法即可。
class Knowledge(ABC):
def load(self) -> List[Document]:
"""Load knowledge from data loader."""
@classmethod
def document_type(cls) -> Any:
"""Get document type."""
def support_chunk_strategy(cls) -> List[ChunkStrategy]:
"""Return supported chunk strategy."""
return [
ChunkStrategy.CHUNK_BY_SIZE,
ChunkStrategy.CHUNK_BY_PAGE,
ChunkStrategy.CHUNK_BY_PARAGRAPH,
ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER,
ChunkStrategy.CHUNK_BY_SEPARATOR,
]
@classmethod
def default_chunk_strategy(cls) -> ChunkStrategy:
return ChunkStrategy.CHUNK_BY_SIZE
知识切片
这个流程的核心角色是ChunkManager。它获取已加载的知识数据后,会根据用户指定的分片策略和参数,将任务路由到对应的切片处理器进行处理。
class ChunkManager:
def __init__(
self,
knowledge: Knowledge,
chunk_parameter: Optional[ChunkParameters] = None,
extractor: Optional[Extractor] = None,
):
self._knowledge = knowledge
self._extractor = extractor
self._chunk_parameters = chunk_parameter or ChunkParameters()
self._chunk_strategy = (
chunk_parameter.chunk_strategy
if chunk_parameter and chunk_parameter.chunk_strategy
else self._knowledge.default_chunk_strategy().name
)
self._text_splitter = self._chunk_parameters.text_splitter
self._splitter_type = self._chunk_parameters.splitter_type
如果你想在界面上自定义一个全新的分片策略,需要完成两件事:
- 新增一个切片策略枚举
- 新增一个对应的Splitter实现逻辑
class ChunkStrategy(Enum):
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[...],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[...],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[...],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
知识抽取
目前支持三种抽取方式:向量抽取、知识图谱抽取、关键词抽取。
向量抽取 -> embedding,需要实现
Embeddings接口。@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: return await asyncio.get_running_loop().run_in_executor(None, self.embed_documents, texts) async def aembed_query(self, text: str) -> List[float]: return await asyncio.get_running_loop().run_in_executor(None, self.embed_query, text)在配置层面,你可以选择OpenAI、通义千问、文心一言等不同的embedding模型。
知识图谱抽取 -> knowledge graph,核心是利用大模型来提取“(实体, 关系, 实体)”这种三元组结构。
class TripletExtractor(LLMExtractor): def __init__(self, llm_client: LLMClient, model_name: str): super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT) TRIPLET_EXTRACT_PT = ( "Some text is provided below. ..." "Text: {text}\n" "Triplets:\n" )倒排索引抽取 -> keywords分词,既可以使用ES自带的默认分词库,也可以利用其插件模式来自定义分词。
知识存储
所有知识持久化工作,统一遵循IndexStoreBase接口。目前提供了三种实现:向量数据库、图数据库、全文索引。
- VectorStore: 向量数据库的核心逻辑主要在
load_document()中,包括创建索引schema、分批写入向量数据等。
- VectorStoreBase
- ChromaStore
- MilvusStore
- OceanbaseStore
- ElasticsearchStore
- PGVectorStore
class VectorStoreBase(IndexStoreBase, ABC):
@abstractmethod
def load_document(self, chunks: List[Chunk]) -> List[str]:
"""Load document in index database."""
@abstractmethod
async def aload_document(self, chunks: List[Chunk]) -> List[str]:
"""Load document in index database."""
@abstractmethod
def similar_search_with_scores(self, text, topk, score_threshold, filters) -> List[Chunk]:
"""Similar search with scores in index database."""
- GraphStore: 提供了三元组写入的实现,通常需要调用具体图数据库的查询语言来完成。例如,
TuGraphStore会根据三元组生成Cypher语句并执行。
- GraphStoreBase
- TuGraphStore
- Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
...
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n1:{self._node_label} {{id:'{obj}'}})"
rel_query = (f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})")
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: 通过构建ES索引,利用ES内置的分词算法进行分词,再由ES构建从keyword到doc_id的倒排索引。
{
"analysis": {"analyzer": {"default": {"type": "standard"}}},
"similarity": {
"custom_bm25": {"type": "BM25", "k1": self._k1, "b": self._b}
},
}
self._es_mappings = {
"properties": {
"content": {"type": "text", "similarity": "custom_bm25"},
"metadata": {"type": "keyword"},
}
}
在全文索引方面,目前提供了对Elasticsearch的接口,并同时定义了OpenSearch的接口。
- FullTextStoreBase
- ElasticDocumentStore
- OpenSearchStore
1.2 知识检索
知识检索的流程可以概括为:question -> rewrite -> similarity_search -> rerank -> context_candidates。
目前社区的检索逻辑大体上遵循这些步骤。如果你配置了查询改写参数,大模型会先对用户问题进行润色。接着,系统会根据你之前采用的知识加工方式,路由到对应的检索器。例如,使用向量加工,则走EmbeddingRetriever;通过知识图谱构建,则按图谱方式检索。最后,若配置了Rerank模型,系统会对粗筛出的候选结果进行精筛,以提升它们与用户问题的关联度。
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever):
def __init__(self, index_store, top_k=4, query_rewrite=None, rerank=None, retrieve_strategy=None):
...
async def _aretrieve_with_score(self, query, score_threshold, filters):
queries = [query]
new_queries = await self._query_rewrite.rewrite(origin_query=query, context=context, nums=1)
queries.extend(new_queries)
candidates_with_score = [
self._similarity_search_with_score(query, score_threshold, filters, ...)
for query in queries
]
...
new_candidates_with_score = await self._rerank.arank(new_candidates_with_score, query)
return new_candidates_with_score
这个检索器的几个关键参数:
index_store:具体的向量数据库实例。top_k:返回的候选chunk数量。query_rewrite:查询改写的函数实现。rerank:重排序函数。query:用户的原始查询。score_threshold:相似度得分阈值,低于此值的上下文将被过滤。filters:元数据过滤器,可用于根据属性信息前置筛选掉不匹配的候选内容。
class FilterCondition(str, Enum):
AND = "and"
OR = "or"
class MetadataFilter(BaseModel):
key: str = Field(...)
operator: FilterOperator = Field(default=FilterOperator.EQ)
value: Union[str, int, float, List[str], ...] = Field(...)
- Graph RAG
首先通过大模型进行关键词抽取。这里既可以使用传统的NLP技术分词,也可以利用大模型来完成。然后对关键词进行同义词扩展,获得一个候选列表。最后,根据这个候选列表调用explore方法来召回局部子图。
KEYWORD_EXTRACT_PT = (
"A question is provided below. ..."
"Text: {text}\n"
"Keywords:\n"
)
def explore(self, subs, direct=Direction.BOTH, depth=None, fan=None, limit=None) -> Graph:
"""Explore on graph."""
- DBSchemaRetriever
这部分是ChatData场景下的schema-linking检索。其核心思想是通过两阶段相似度检索:首先找到最相关的表,再找到最相关的字段。
这样做有一个明显的好处:能够有效解决社区反馈的大宽表体验问题。
def _similarity_search(self, query, filters):
table_chunks = self._table_vector_store_connector.similar_search_with_scores(query, self._top_k, 0, filters)
not_sep_chunks = [chunk for chunk in table_chunks if not chunk.metadata.get("separated")]
separated_chunks = [chunk for chunk in table_chunks if chunk.metadata.get("separated")]
if not separated_chunks:
return not_sep_chunks
tasks = [lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks]
separated_result = run_tasks(tasks, concurrency_limit=3)
return not_sep_chunks + separated_result
这里,table_vector_store_connector负责检索最相关的表,而field_vector_store_connector则负责检索最相关的字段。
二、知识加工与知识检索优化思路
目前,RAG智能问答应用存在几个明显的痛点:
- 知识库文档数量增多时,检索噪音变大,召回准确率随之下降。
- 召回不全面,完整性不足。
- 召回的内容与用户问题的意图相关性不高。
- 仅能回答静态数据,无法动态获取知识,导致应用显得僵化、不够智能。
2.1 知识处理优化
非结构化、半结构化和结构化数据的处理水平,直接决定了RAG应用的效果上限。因此,首先需要在知识处理和索引阶段,进行大量精细的ETL工作。主要的优化思路有两点:
- 非结构化 -> 结构化:将知识信息组织得清晰有序。
- 提取更丰富、更多元的语义信息。
2.1.1 知识加载
目的: 对文档进行精确解析,能够识别出更多不同类型的数据。
优化建议:
- 建议将docx、txt等文本格式预先转换为PDF或Markdown,以便利用更优秀的识别工具提取内容。
- 提取文本中的表格信息。
- 保留Markdown和PDF的标题层级信息,为后续构建层级关系树等索引方式做准备。
- 保留图片链接、公式等信息,并统一处理成Markdown格式。
2.1.2 切片Chunk尽量保持完整
目的: 保持上下文的完整性和相关性,这直接关系到回复的准确率。
需要确保分块大小在大模型的上下文限制范围内,保证输入给LLM的文本不会超过其token限制。
优化建议:
- 图片 + 表格 单独抽取成Chunk,并将表格和图片的标题保留在metadata元数据中。
- 文档内容尽量按标题层级或Markdown Header进行拆分,尽可能保证chunk的完整性。
- 如果有自定义分隔符,可以按自定义分隔符进行切分。
2.1.3 多元化的信息抽取
除了对文档进行Embedding向量抽取,其他多元化的信息抽取能够对文档进行数据增强,显著提升RAG的召回效果。
知识图谱
- 优点:解决了原生RAG完整性缺失和幻觉的问题。对知识的准确性、边界完整性和语义清晰性有更好的保障,是对相似度检索能力的一种语义补充。
- 适用场景:适用于医疗、运维等严谨的专业领域。在这些领域,知识的准确性需要受到约束,且知识之间能够建立清晰的层级关系。
- 如何实现:
1. 依赖大模型提取(实体, 关系, 实体)三元组。
2. 依赖前期高质量、结构化的知识准备、清洗和抽取,通过业务规则或自定义SOP流程来构建知识图谱。
Doc Tree
- 适用场景:解决了上下文完整性不足的问题,同时能够依据语义和关键词进行匹配,减少噪音。
- 如何实现:以标题层级构建chunk的树形节点,形成一个多叉树结构。每个非叶子节点只存储文档标题,叶子节点存储具体文本内容。利用树的遍历算法,如果用户问题命中了相关的非叶子标题节点,就能将相关的子节点数据全部召回。这样就不会出现chunk完整性缺失的问题。
(这部分功能将在明年初开放到社区)。
提取QA对
- 适用场景:适用于FAQ场景,或召回应完整性不够的场景。能够直接命中问题并召回答案。
- 如何实现:
1. 预定义:预先为每个chunk添加一些问题。
2. 模型抽取:给定上下文,让模型进行QA对抽取。
元数据抽取
- 如何实现:根据业务数据特点,提取数据的特征并保留,例如标签、类别、时间、版本等。
- 适用场景:检索时能够预先根据元数据属性过滤掉大部分噪音。
总结提取
- 适用场景:解决“这篇文章讲了什么”、“总结一下”等全局性问题。
- 如何实现:通过mapreduce等方式分段抽取,由模型为每段chunk生成摘要信息。
2.1.4 知识处理工作流
目前,DB-GPT知识库已提供文档上传、解析、切片、Embedding、知识图谱三元组抽取、向量和图数据库存储等能力,但尚不具备对文档进行复杂、个性化的信息抽取功能。因此,可以通过构建知识加工工作流模板,来完成复杂、可视化、用户可自定义的知识抽取、转换和加工流程。
2.2 RAG流程优化
RAG流程的优化分为两部分:静态文档的RAG和动态数据获取的RAG。目前,大部分RAG仅覆盖了非结构化的文档静态资产,但在实际业务中,许多问答场景需要通过工具获取动态数据,并结合静态知识数据来共同回答。这要求RAG不仅要检索静态知识,还要同时检索工具资产库中的工具信息,并执行工具以获取动态数据。
2.2.1 静态知识RAG优化
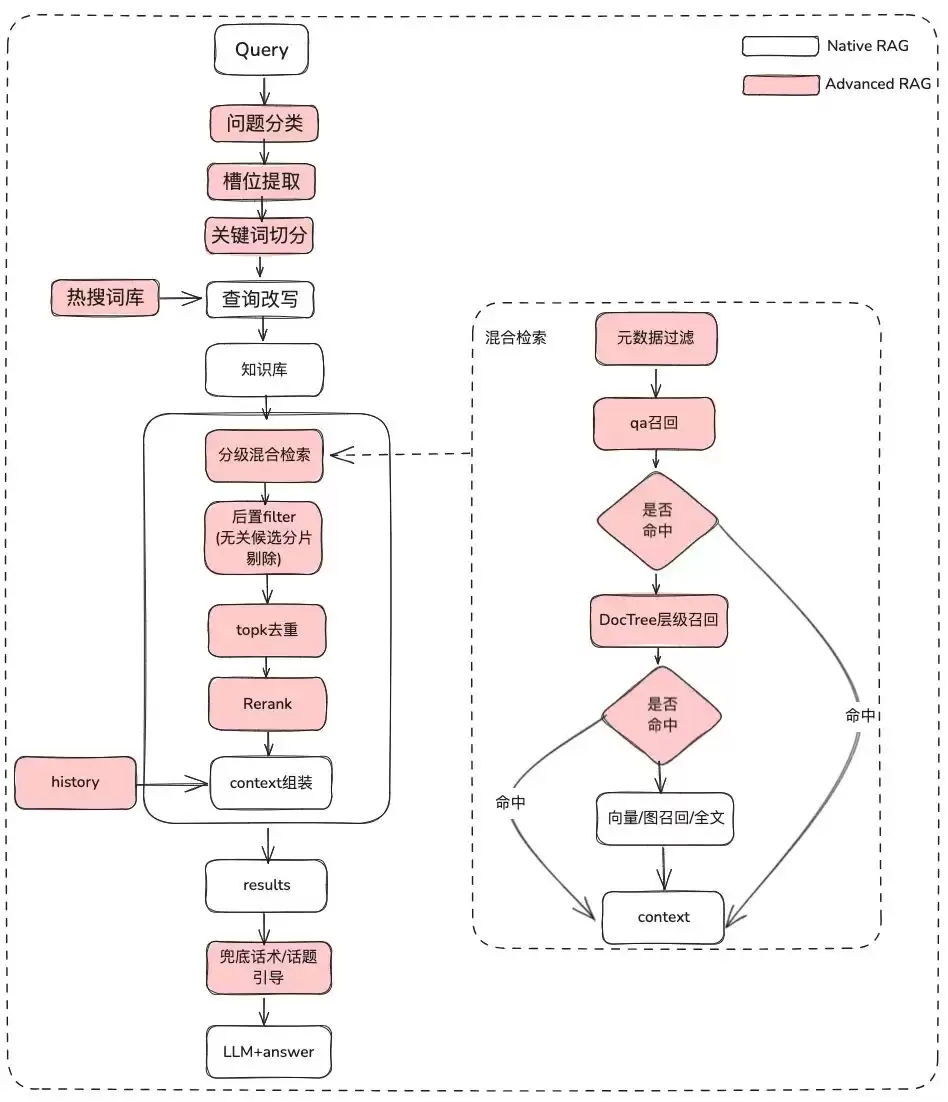
2.2.1.1 原始问题处理
目的: 澄清用户语义,将模糊、意图不清的原始问题,优化成一个语义更丰富、更便于检索的Query。
原始问题分类:通过问题分类可以实现:
- LLM分类 (LLMExtractor)
- 构建embedding + 逻辑回归双塔模型 (text2nlu)
- Tip: 需要高质量的Embedding模型,推荐bge-v1.5-large。
反问用户:如果语义不清晰,可以将问题再抛回给用户,通过多轮交互来澄清意图。
通过热搜词库:根据语义相关性,向用户推荐可能想询问的问题候选列表。
槽位提取:获取用户问题中的关键slot信息,例如意图、业务属性等。
问题改写:
- 通过热搜词库进行改写。
- 通过多轮交互进行改写。
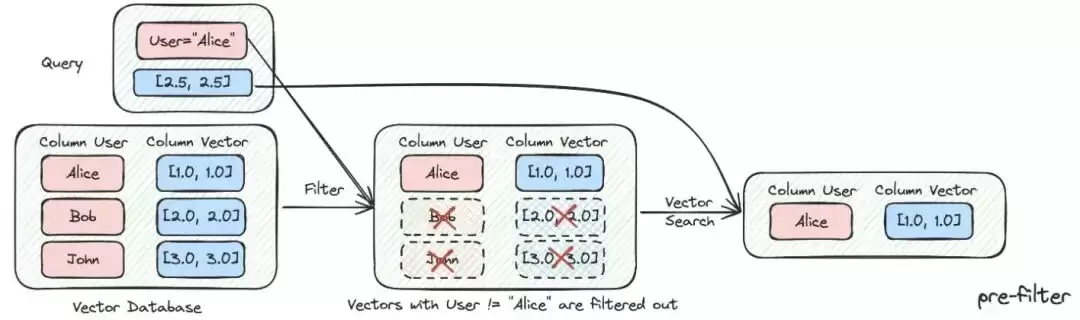
2.2.1.2 元数据过滤
当索引被切分成众多chunks,并存储在同一个知识空间时,检索效率就会成为问题。例如,用户询问“浙江我武科技公司”的信息时,自然不希望召回其他公司的信息。因此,如果能通过公司名称这个元数据属性先进行过滤,就能显著提升效率和相关度。
async def aretrieve(self, query, filters=None) -> List[Chunk]:
"""Retrieve knowledge chunks."""
return await self._aretrieve(query, filters)
2.2.1.3 多策略混合召回
按优先级召回:为不同的检索器定义优先级,一旦检索到内容就立即返回。
可以将不同的检索器(如qa_retriever, doc_tree_retriever)放入一个队列中,利用队列先进先出的特性来实现优先级召回。
class RetrieverChain(BaseRetriever): def __init__(self, retrievers=None, executor=None): self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores(...) if candidates_with_scores: return candidates_with_scores多知识索引/空间并行召回:通过知识的不同索引形式,采用并行召回的方式获取候选列表,从而保证召回的完整性。
2.2.1.4 后置过滤
粗筛获得候选列表后,如何通过精筛来过滤噪音?
- 无关的候选分片剔除:包括时效性剔除、业务属性不满足剔除。
- topk去重。
- 重排序:仅靠粗筛召回还不够,需要借助一些策略对检索结果进行重排序。例如,结合相关度、匹配度等因素进行重新调整,以获得更符合业务场景的排序。毕竟这一步之后,结果就要交给LLM做最终处理,因此这部分结果至关重要。
- 使用相关重排序模型进行精筛,可以使用开源模型,也可以使用带有业务语义微调的模型。
## Rerank model #RERANK_MODEL=bce-reranker-base #RERANK_TOP_K=5
- 根据不同索引召回的内容,进行业务RRF加权综合打分剔除。
score = 0.0
for q in queries:
if d in result(q):
score += 1.0 / ( k + rank( result(q), d ) )
return score
2.2.1.5 显示优化+兜底话术/话题引导
- 让模型使用Markdown格式输出。例如,在prompt中要求模型:如果已知信息包含图片、链接、表格、代码块等特殊标签,必须原样包含在答案中,不得丢弃或修改。
2.2.2 动态知识RAG优化
文档类知识相对静态,无法回答个性化和动态的信息,例如“今天天气怎么样”。这就依赖于一些第三方平台工具。基于这种情况,我们需要动态RAG的方法,其流程包括:工具资产定义 -> 工具选择 -> 工具校验 -> 工具执行获取动态数据。
2.2.2.1 工具资产库
构建企业领域的工具资产库,将散落在各个平台的工具API、工具脚本整合起来,为智能体提供端到端的使用能力。例如,除了静态知识库,我们还可以通过导入工具库的方式来处理工具。
2.2.2.2 工具召回
工具召回沿用了静态知识RAG的思路,再结合完整的工具执行生命周期来获取执行结果。
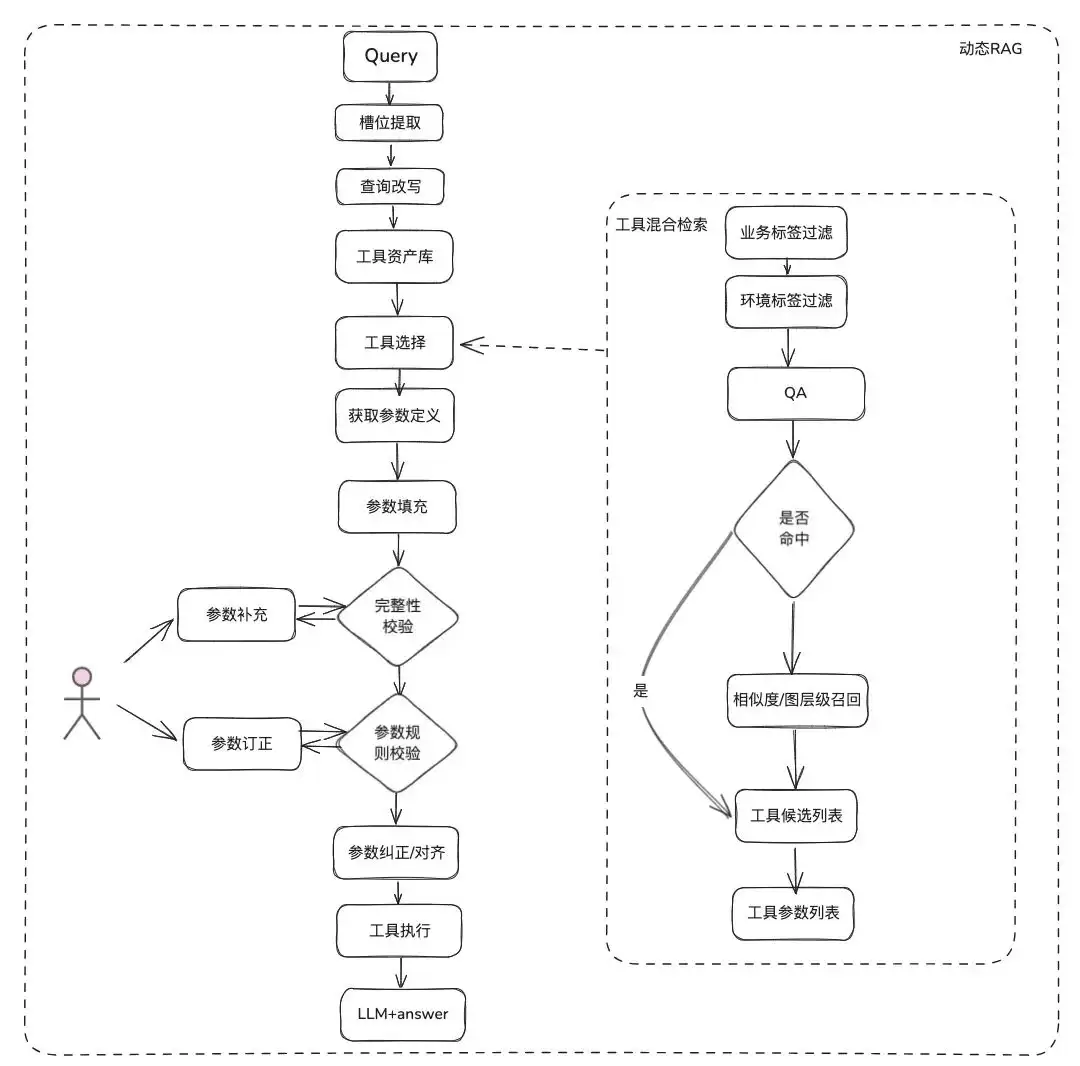
- 槽位提取:通过传统NLP或LLM,解析用户问题,提取常用的业务类型、标签、领域模型参数等。
- 工具选择:沿用静态RAG的召回思路,分为两层:工具名召回和工具参数召回。这与TableRAG的思路类似,先召回表名,再召回字段名。
- 参数填充:根据召回的工具参数定义,与槽位提取出的参数进行匹配。既可以通过代码填充,也可以让模型填充。
- 参数校验:包括完整性校验(参数个数是否齐全)和规则校验(参数名类型、参数值、枚举等)。
- 参数纠正/对齐:主要目的是减少与用户的交互次数,自动化完成参数错误纠正,例如大小写规则、枚举规则等。
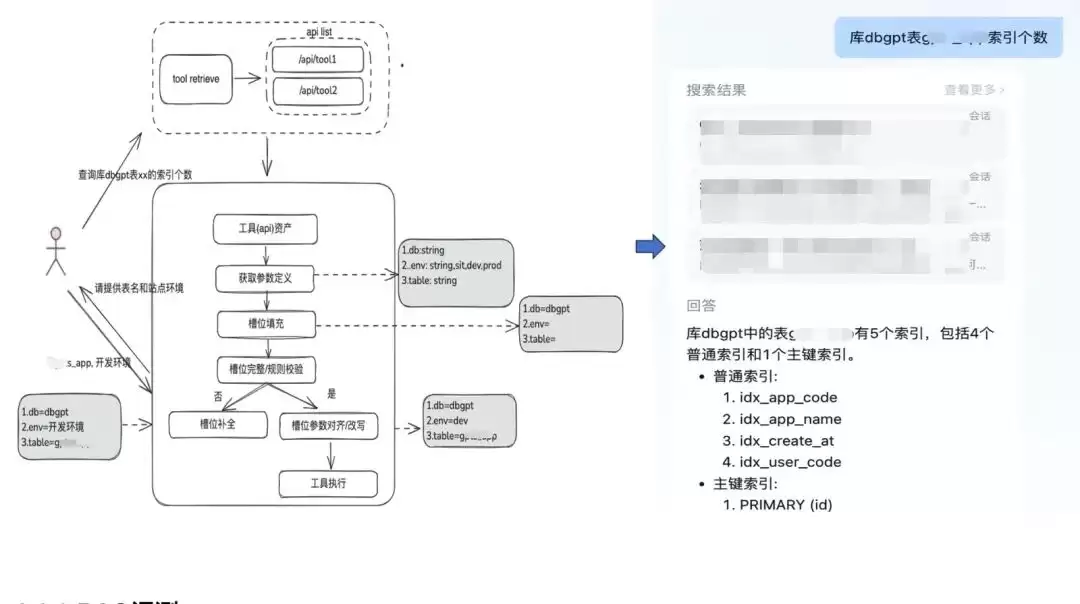
2.2.3 RAG评测
在评估智能问答流程时,需要单独评估召回相关性准确率和模型问答的相关性,然后综合判断RAG流程在哪些方面还需要改进。
评价指标:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
- RAG召回指标:
- RetrieverHitRateMetric:命中率,衡量RAG检索器召回到出现在前top-k个文档中的比例。
- RetrieverMRRMetric:平均倒数排名,通过分析最相关文档在检索结果中的排名来计算每个查询的准确性。
- RetrieverSimilarityMetric:相似度指标,计算召回内容与预测内容的相似度。
- 模型生成答案指标:
- AnswerRelevancyMetric:答案相关性指标,衡量智能体答案与用户提问的匹配程度。
三、RAG落地案例分享
3.1 数据基础设施领域的RAG
3.1.1 运维智能体背景
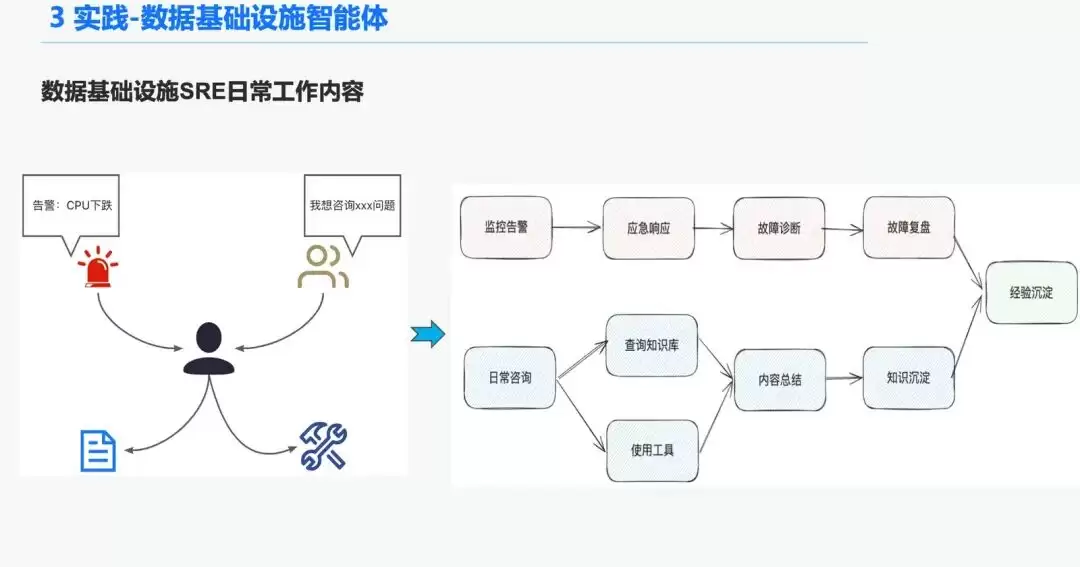
在数据基础设施领域,运维SRE每天会接收大量告警。他们大部分时间需要响应应急事件、进行故障诊断、复盘和沉淀经验。另一部分时间需要响应用户咨询,运用他们的知识和三方平台工具经验进行答疑。
因此,我们希望打造一个数据基础设施的通用智能体,来解决告警诊断和答疑这些问题。
3.1.2 严谨专业的RAG
传统的RAG + Agent技术可以解决通用、确定性不高、单步的任务场景。但面对数据基础设施领域的专业场景,整个检索过程必须是确定、专业和真实的,并且需要逐步推理。
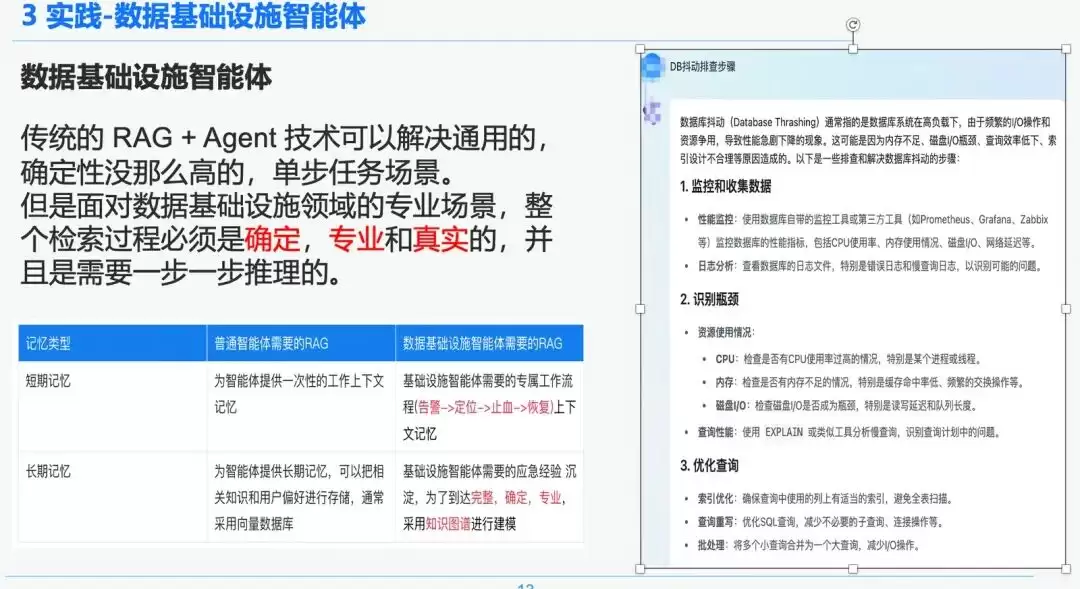
例如,右侧是通过原生RAG得到的一个泛泛而谈的总结。对于一个不了解专业领域知识的普通用户可能有用,但对于数据基础设施领域的专业人士来说,基本没有价值。因此,我们对比了通用智能体和数据基础设施智能体在RAG上的区别:
- 通用智能体:对知识的严谨性和专业性要求不高,适用于客服、旅游、平台答疑机器人等场景。
- 数据基础设施智能体:RAG流程是严谨和专业的,需要专属的RAG工作流程。上下文包括“DB告警->根因定位->应急止血->故障恢复”,并且需要对专家沉淀的问答和应急经验进行结构化抽取,建立层次关系。因此,我们选择知识图谱作为数据承载。
3.1.3 知识处理
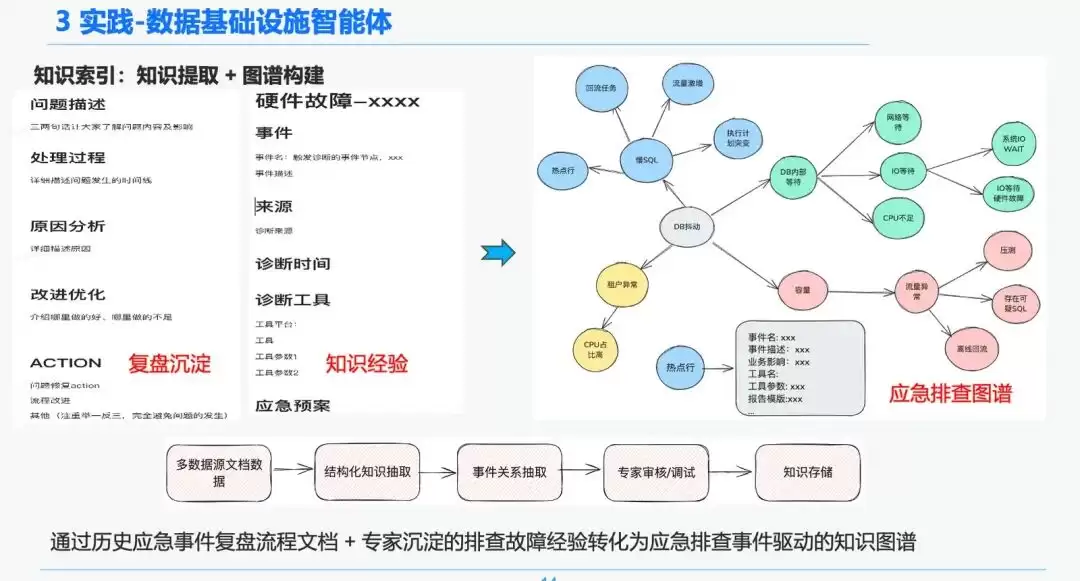
基于数据基础设施的确定性和特殊性,我们选择通过知识图谱来承载诊断应急经验。我们利用SRE沉淀下来的应急排查事件知识经验,结合应急复盘流程,建立了DB应急事件驱动的知识图谱。以DB抖动为例,影响DB抖动的事件包括慢SQL问题、容量问题等,我们在各个应急事件间建立了层级关系。
最后,通过规范应急事件规则,我们逐步建立了一套标准化的知识加工体系:多源知识 -> 知识结构化抽取 -> 应急关系抽取 -> 专家审核 -> 知识存储。
3.1.4 知识检索
在智能体检索阶段,我们使用GraphRAG作为静态知识检索的承载。当识别到DB抖动异常后,就能找到与DB抖动异常节点相关的节点作为分析依据。由于在知识抽取阶段,每个节点还保留了事件的元数据信息(事件名、事件描述、相关工具、工具参数等),我们可以通过执行工具的执行生命周期链路来获取返回结果,拿到动态数据作为应急诊断的排查依据。
这种“动静结合”的混合召回方式,比纯朴素的RAG召回,更能保障数据基础设施智能体执行的确定性、专业性和严谨性。
3.1.5 AWEL + Agent
最后,通过社区AWEL+AGENT技术,利用AGENT编排的范式,打造了从意图专家 -> 应急诊断专家 -> 诊断根因分析专家的流程。
每个Agent的职能各不相同:
- 意图专家:负责识别解析用户意图和告警信息。
- 诊断专家:通过GraphRAG定位需要分析的根因节点,并获取具体的根因信息。
- 分析专家:结合各个根因节点的数据 + 历史分析复盘报告,生成诊断分析报告。
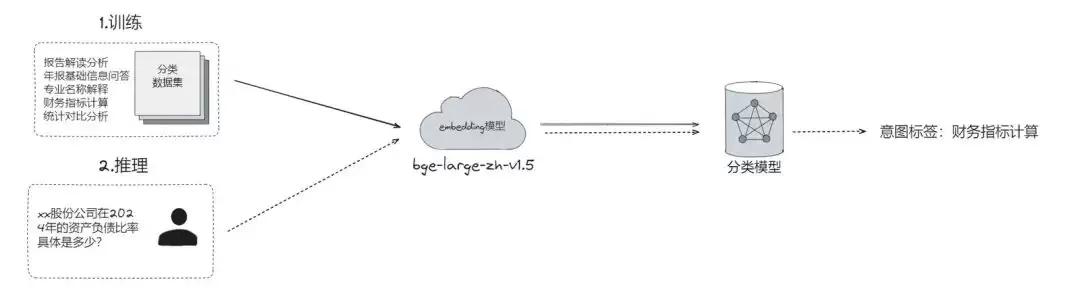
3.2 金融财报分析领域的RAG
基于DB-GPT的财报分析助手也是一个典型的应用场景。
四、总结
最后总结一下,建议围绕各自的领域,构建属于自己的一整套领域资产库,包括知识资产、工具资产和知识图谱资产。
- 领域资产:包括领域知识库、领域API、工具脚本、领域知识图谱。
- 资产处理:整个资产数据链路涉及加工、检索和评估。
- 非结构化 -> 结构化:有条理地归类,正确地组织知识信息。
- 提取更加丰富的语义信息。
- 资产检索:
- 希望是有层级、有优先级的检索,而非单一的检索。
- 后置过滤很重要,最好能通过业务语义规则进行过滤。