AI领域再添重磅选手:Anthropic发布首个混合推理模型Claude 3.7,同步推出智能编码工具Claude Code
北京时间凌晨三点,Anthropic丢出一枚“冲击波”——正式发布全球首个混合推理大模型Claude 3.7 Sonnet。同时,还推出一款让开发者群情沸腾的智能编码工具Claude Code。这两件事放在一起,就很有意思了。先列几个核心看点。
One More Thing
主观重点
1、Claude 3.7——首次融合通用模型与推理模型的混合架构
注意看下面的交互逻辑:标准模式提供快速响应,扩展思考模式则可实现逐步推理。不过这个交互设计有点意思——为什么不让用户像DeepSeek R1那样直接触发推理,而是多一步选择?多一步就多一秒消耗,OpenAI和Grok 3的做法反倒更干脆。
2、Claude Code——智能编码工具,瞄准终端开发者
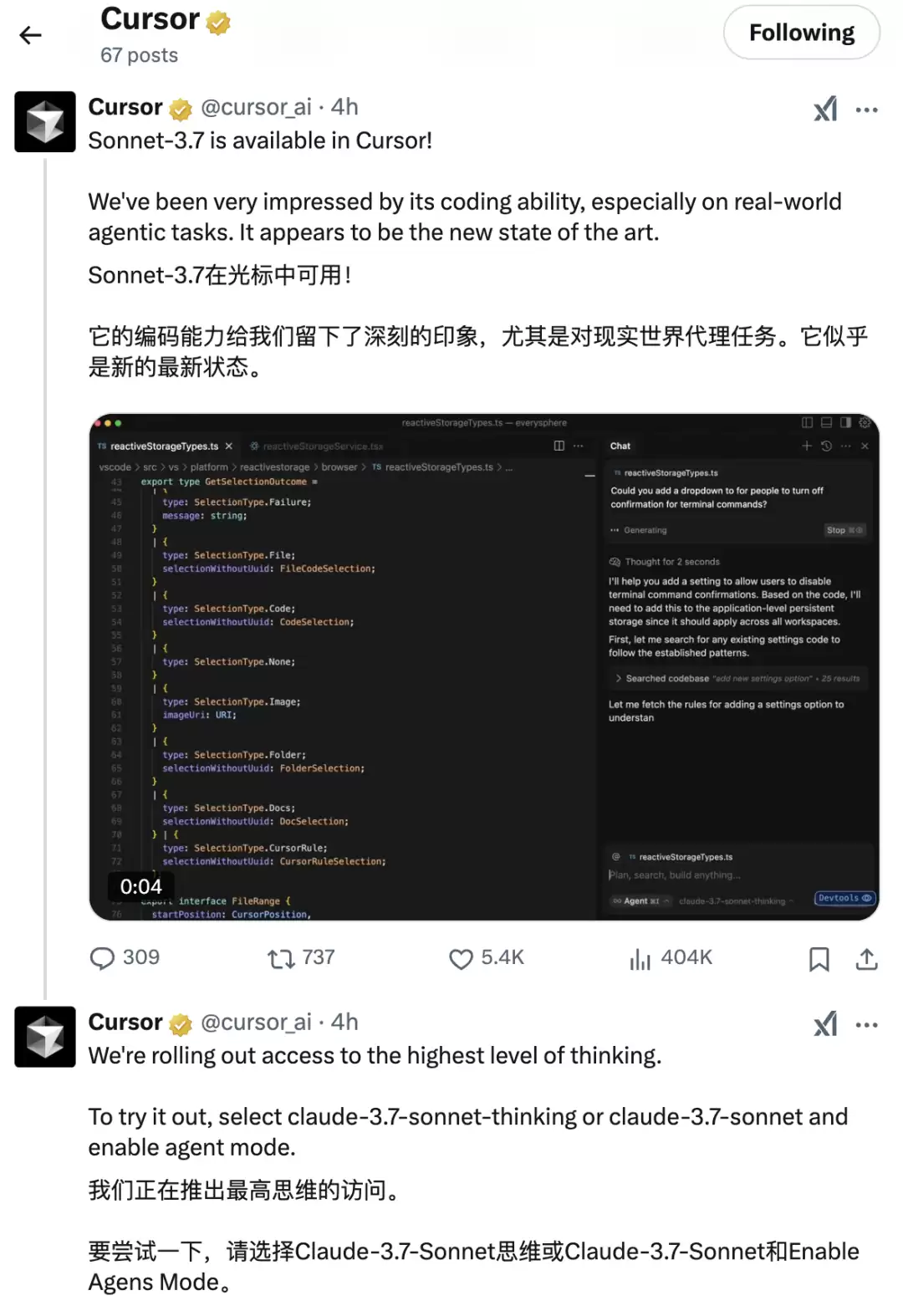
业内都清楚,Claude 3.5一直是全球开发者的首选,连风靡全球的Cursor也依赖于它。这回Anthropic亲自下场,推出了命令行工具Claude Code(目前作为有限研究预览版)。开发人员可以直接在终端将大量工程任务交给Claude处理。有分析认为,Anthropic或许是看到了Cursor的日活和收入,决定自己做一个编码工具。至于它能否撼动Cursor?还要看实际能力。但看官网文档和评测数据,Anthropic似乎正全力朝AI编码方向冲刺。X平台上第一时间出现了Cursor的回应:
3、通过API控制思考时长,兼顾速度、成本和精度
DeepSeek R1虽然火,但在某些场景下“思考过度”是个硬伤——尤其在B端应用中,不能控制思维链过程会导致响应慢、体验差、成本高。Claude 3.7针对这一点,允许开发者设置一个“thinking budget”,来控制模型思考的上限。通过API使用时,你可以告诉Claude“思考不超过N个token”,输出限制为128K token。这就让用户在速度(和成本)与答案质量之间做权衡。当然,这一切的前提还是模型底层推理能力要够强——推理能力不行,再雕花也是白搭。
4、一些其他
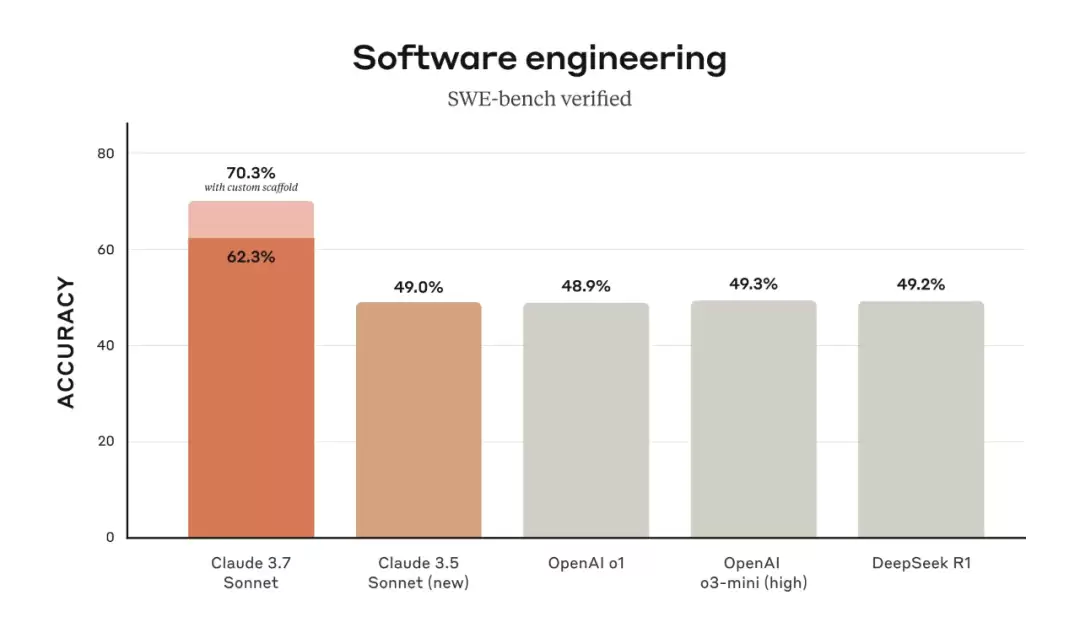
在开发自家推理模型时,Anthropic选择了一条差异化路线:对数学和计算机竞赛问题的优化较少,而将重点转向更能反映企业实际使用LLM方式的现实任务。来看基准测试结果——在SWE-bench Verified(评估LLM解决GitHub真实软件问题的数据集)上,Claude 3.7 Sonnet实现了SOTA性能,远远超过Claude 3.5 Sonnet、OpenAI的o3-mini(high)和o1、DeepSeek R1。
在TAU-bench(评估LLM在复杂真实场景中用户与工具交互能力的基准测试平台)上,Claude 3.7 Sonnet同样实现SOTA,超过Claude 3.5 Sonnet和OpenAI的o1。
当然,Claude 3.7 Sonnet在指令遵循、通用推理、多模态能力和智能编码方面表现出色,扩展思考在数学和科学上有显著提升,但在部分指标上仍不及OpenAI的o3-mini(high)、Grok-3 Beta等。
目前Claude 3.7已全量上线。如果你的付费账户没被封禁,可以直接体验;也可以通过亚马逊平台调用API使用。个人用户方面,Cursor、Monica等应该会很快接入。
下面是官方基于扩展思考模式向用户解释“三门问题”的示例:
Anthropic的发展规划
下图展示了Anthropic的路线图——2025年对应OpenAI所说的L3智能体(不仅能思考还能行动的AI系统),2027年则对应L5组织者(可完成组织工作的AI)。谁能先到达L5?拭目以待。