人工神经网络:从模仿大脑机制到解决现实复杂问题
人工神经网络(Artificial Neural Network,ANN),简单来说,是从信息处理的角度模仿人脑神经元网络而构建的一种数学模型。通过不同的连接方式,形成了多种网络结构,这些网络在语音识别、计算机视觉、自然语言处理等领域已取得突破性成果。那么,这样一个强大工具的基本单元长什么样?它又是如何工作的呢?
神经元——神经网络的基本计算单元
在神经网络中,神经元是计算的基本单位,也常被称为节点或单元。它从其他节点或外部接收输入,经过计算后产生输出。每两个节点之间的连接都对应一个加权值,这个值被称为权重(weight)。神经元会对输入的加权和施加一个函数f(定义如下),具体如下图所示。
该网络接收数值输入X1和X2,以及对应的权重w1、w2,还有一个特殊的输入权重b,称为偏置。偏置的作用稍后会详细说明。
神经元的输出Y的计算方式如上图所示。函数f是非线性的,被称为激活函数。它的核心作用是将非线性引入神经元的输出中,使神经元能够学习非线性的表达方式,从而适应真实世界中复杂的数据分布。
每个激活函数都会对输入的数字执行特定运算。在实际应用中,最常见的激活函数有以下几种:
- Sigmoid函数:σ(x) = 1 / (1 + exp(−x))
- tanh函数:tanh(x) = 2σ(2x) − 1
- ReLU函数:f(x) = max(0, x)
下面是这几个激活函数的图像。

这里必须强调偏置的重要性:如果没有偏置,所有决策边界都只能经过原点,但现实问题远没有那么“听话”——很少有数据刚好在原点附近就能够线性可分。偏置就是那个让你能够自由平移决策边界的关键参数。
前馈神经网络——最经典的网络结构
前馈神经网络是人工神经网络家族中最简单也最经典的一种。神经元从输入层开始,接收前一层的输出,然后往后传递到下一层,直至到达输出层。整个网络没有反馈连接,可以用有向无环图来表示。
前馈神经网络的结构如下图所示。
它由三种类型的节点组成:
- 输入节点:输入阶段负责将外部信息提供给网络,这些节点统称为“输入层”。输入节点不执行任何计算,只是将信息传递给隐藏层。
- 隐藏节点:隐藏节点与外界没有直接联系(因此得名“隐藏”)。它们执行计算,并将信息从输入节点传递到输出节点。隐藏节点的集合形成“隐藏层”。一个前馈网络可以没有隐藏层,也可以包含多个隐藏层。
- 输出节点:输出节点统称为“输出层”,负责计算并将最终结果传输到外界。
前馈网络有两个经典实例:
- 单层感知器:最简单的形式,没有任何隐藏层。
- 多层感知器:含有一个或多个隐藏层。在实际应用中,多层感知器更为常见,因此我们重点讨论它。
多层感知器——具备非线性学习能力的关键模型
多层感知器(Multi-Layer Perceptron,MLP)包含一个或多个隐藏层(除了一个输入层和一个输出层)。单层感知器只能学习线性函数,而多层感知器能够学习非线性函数——这才是其真正的价值所在。
下图展示了一个单隐藏层的多层感知器。注意,所有连接都有对应的权重,但为了清晰,图中只标出了三个权重(w0, w1, w2)。
输入层:输入层包含三个节点。偏置节点的值固定为1,另外两个节点接收外部输入X1和X2(数值来自训练数据集)。输入层不做计算,所以三个节点的输出就是1, X1, X2——这些值被直接传递给隐藏层。
隐藏层:隐藏层也有三个节点。其中偏置节点的输出为1,另外两个节点的输出取决于输入层传来的值(1, X1, X2)以及连接它们的权重。
下图展示了其中一个隐藏节点的输出计算过程。同理,可以计算出另一个隐藏节点的输出。这些输出随后被反馈到输出层。
输出层:输出层有两个节点,它们从隐藏层接收输入,并执行与隐藏节点相似的计算。最终得到Y1和Y2——这就是多层感知器的输出。
给定一组特征X=(x1, x2, ...)和一个目标y,多层感知器就能学习特征与目标之间的关系——无论是用于分类还是回归任务。
为了更好地理解,咱们看一个学生成绩预测的例子。假设有以下数据集:
| 学习小时数 | 期中分数 | 期末通过(1)/失败(0) |
|---|---|---|
| 35 | 67 | 1 |
| ... | ... | ... |
两列输入分别表示学生学习的小时数和期中成绩。最后一列是标签:1表示通过期末测试,0表示未通过。例如,一个学习35小时、期中67分的学生,最终通过了期末测试。
现在,我们希望预测一个学习25小时、期中70分的学生能否通过。这是一个典型的二元分类问题。多层感知器可以从给定的训练数据中学习,然后对新数据点进行预测。那么它是怎么学习的呢?
训练多层感知器:前向传播与反向传播
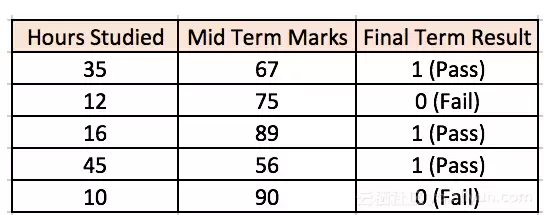
下图中的多层感知器,输入层有两个节点(除了偏置),分别接收“学习小时数”和“期中分数”。隐藏层也有两个节点(除了偏置)。输出层同样有两个节点:上层输出“通过”的概率,下层输出“失败”的概率。
在分类任务中,输出层通常使用Softmax函数作为激活函数,以确保输出的概率是有效的(数值在0到1之间,且总和为1)。因此:
P(通过) + P(失败) = 1
第1步:前向传播
网络中的所有权重首先随机初始化。假设隐藏层中有一个节点标记为V。从输入到该节点的连接权重为w1, w2, w3(如图所示)。
现在,我们输入第一个训练样本(已知:输入35小时、67分时,通过概率应为1)。
输入 = [35, 67]
期望输出 = [1, 0]
节点V的输出可以这样计算(f是激活函数,比如Sigmoid):
V = f(1*w1 + 35*w2 + 67*w3)
同理,计算隐藏层中另一个节点的输出。两个隐藏节点的输出再作为输出层两个节点的输入,最终得到输出概率。
假设输出层得到概率为0.4和0.6(因为权重随机,输出也随机)。这与期望的[1, 0]相差甚远,说明网络当前的输出是“错误的”。
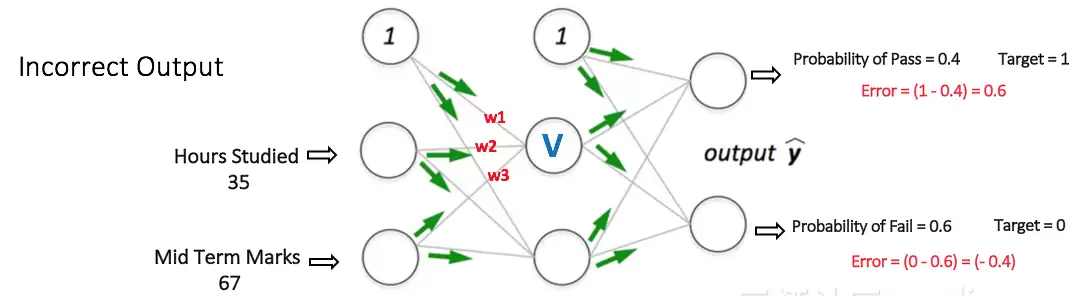
第2步:反向传播与权重更新
计算输出节点的总误差,然后利用反向传播将误差传回网络,计算出梯度。接着使用梯度下降等优化方法来更新权重,以减小误差。如下图所示。
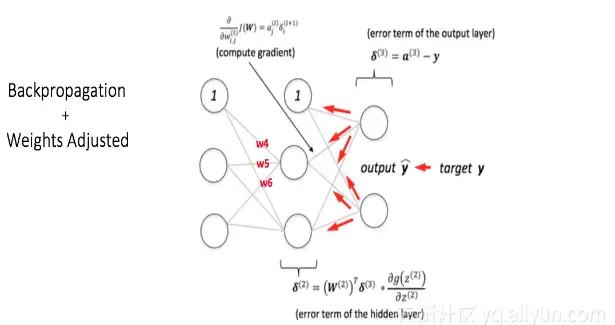
假设更新后,与节点V相关的新权重变为w4, w5, w6。
现在,我们再次向网络输入相同的样本,由于权重已经调整过,网络的表现应该比之前好。如图所示,输出节点的误差从[0.6, -0.4]降低到了[0.2, -0.2]。这意味着神经网络已经学会了正确分类第一个训练样本。
对数据集中所有训练样本重复这个过程,神经网络就能学会全部样本的分布模式。
如果现在要预测学习25小时、期中70分的学生,只需再走一遍前向传播,就能得到通过和失败的概率。
多层感知器的三维可视化——直观理解网络内部
Adam Harley曾创建了一个非常酷的可视化示例:在MNIST手写数字数据集上训练了一个多层感知器(使用反向传播算法)。网络将784个像素值作为输入(对应28×28的图像),第一个隐藏层有300个节点,第二个隐藏层有100个节点,输出层有10个节点(对应0-9十个数字)。
虽然这个网络比我们刚才讨论的要大得多(更多的隐藏层和节点),但前向传播和反向传播的计算原理完全一样——每个节点都在执行相同的操作。
在可视化中,颜色越亮表示节点的输出值越高。输入层中,亮节点代表接收较高像素值的节点。输出层中,唯一亮起的节点对应数字5(它的输出概率为1,其他九个节点概率为0),说明MLP正确识别了输入的图像数字。强烈推荐去体验这个可视化示例,观察不同层级节点之间的连接,效果非常直观。