在机器学习领域,十大经典算法是每一位数据科学从业者必须掌握的核心知识。这些算法涵盖了回归分析、分类任务、聚类分析、集成学习等多个方向,既包括简单直观的线性模型,也包含高效强大的树模型与集成方法。下面我们将逐一深入解析这些算法,探讨各自的特点、适用场景及注意事项。
1. 线性回归
线性回归是统计与机器学习领域最广为人知、也是最容易上手的算法之一。其核心思想简单明了:用一条直线(或超平面)来拟合输入变量与输出变量之间的关系。标准的线性回归公式为 y = B0 + B1 * x,学习算法的目标在于找到最优的系数 B0 和 B1,使得这条直线能最好地描述数据分布。
预测建模通常更关注准确率而非可解释性,但线性回归恰恰能在两者之间取得不错的平衡。它拥有超过200年的历史,在数据预处理方面,一个实用经验是:尽量移除高度相关的变量,同时清除噪声数据。线性回归运算速度快,适合作为初学者迈入机器学习的第一把钥匙。
2. Logistic回归
Logistic回归虽然名称中带有“回归”,但实际上是解决二分类问题的首选算法。与线性回归类似,它需要为每个输入变量寻找权重系数,区别在于输出值会通过一个名为“Logistic函数”(形状类似大写字母S)的非线性变换,映射到0和1之间的概率值。通过设定一个阈值(例如0.5),即可决定样本所属类别。
更为强大的是,Logistic回归不仅输出分类结果,还能给出属于某个类别的概率,这在需要额外解释的场景下非常实用。它同样对无关特征和强相关特征敏感,删除这些冗余项能显著提升效果。由于学习速度快,它已成为二分类问题中的常青树。
3. 线性判别分析
当面临多分类问题时,Logistic回归往往力不从心,此时线性判别分析(LDA)便成为理想选择。LDA的表示非常直观:它为每个类别计算均值,并假设所有类别的方差相同。预测时,只需计算每个类别的判别值,选择最大值作为输出。
LDA假设数据符合高斯分布(钟形曲线),因此建模前最好剔除异常值。它是一种简单而有效的多分类方法,特别适合解释性要求高的场景。
4. 分类和回归树
决策树是一类至关重要的预测建模算法,其底层结构为一棵二叉树。每个节点代表一个输入变量及其分割点(例如某个数值阈值),叶子节点则存放最终的输出值。预测时,从根节点一路向下遍历,直至到达叶子节点,输出结果。
决策树学习速度快,预测也快,且无需对数据进行过多预处理。在许多实际问题中,其准确率相当可观,是集成方法理想的基学习器。
5. 朴素贝叶斯
朴素贝叶斯是一种简单却异常强大的算法。它基于贝叶斯定理,直接从训练数据中计算出两类概率:每个类别的先验概率,以及每个特征值在各类别下的条件概率。对于连续特征,通常假设其符合高斯分布来估算这些概率。
之所以称为“朴素”,是因为它假设所有输入变量相互独立——这一假设在真实数据中几乎不可能成立,但奇迹般地,它在大量复杂问题中仍表现优异。计算效率高,特别适合高维度文本分类任务。
6. K最近邻算法
K最近邻(KNN)可能是最直观易懂的算法。其模型就是整个训练数据集,无需显式训练过程。当新数据点出现时,算法在训练集中搜索与它最相似的K个实例(近邻),然后根据这些近邻的输出来做预测——回归问题取均值,分类问题取众数。
关键问题在于如何定义“相似”。如果所有特征尺度一致,欧氏距离是最常用的度量标准。缺点是当特征维度较高时,距离度量会失效(即维数灾难),因此需要精心选择特征。此外,KNN需要存储全部训练数据,内存开销较大,但可以通过在线更新来保持准确率。
7. 学习向量量化
KNN的一个显著缺点是需要记住整个训练集,而学习向量量化(LVQ)则有效解决了这一问题。LVQ从训练数据中学习一组“码本向量”,这些向量初始时随机初始化,经过多轮迭代后,能够最好地总结数据的分布规律。
预测时,LVQ与KNN类似,通过计算新数据与每个码本向量的距离,找到最匹配的单元并返回其类别或数值。为了获得更好的结果,建议将数据缩放到统一范围(如0到1)。如果你发现KNN效果不错但内存吃紧,LVQ是一个不错的替代方案。
8. 支持向量机
支持向量机(SVM)是近年来讨论热度最高的算法之一。其目标是在特征空间中找到一个“超平面”(在二维中是一条直线),将不同类别的点尽可能分开。关键在于,这个超平面不仅要能分开数据,还要使离它最近的数据点(支持向量)之间的距离(间隔)最大化。
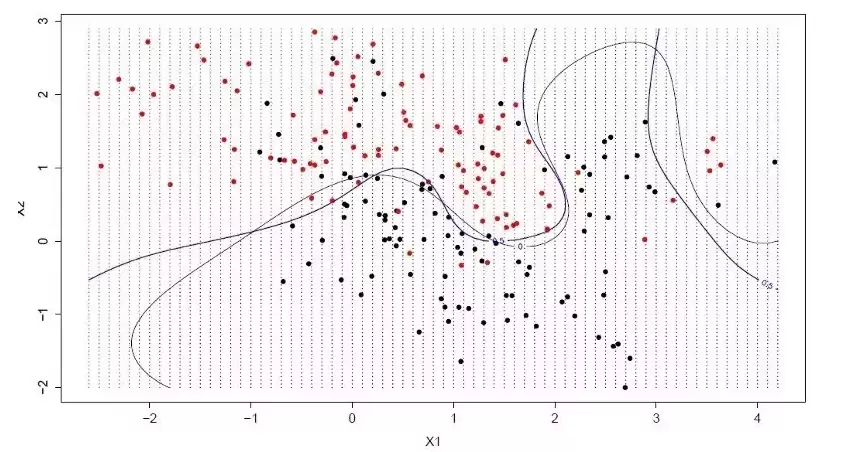
SVM通过优化算法找到这个最大间隔的超平面,只有支持向量点才参与定义。它可以说是目前可以直接使用的最强大的分类器之一,尤其在中小规模数据上表现亮眼。
9. 袋装法和随机森林
随机森林是集成学习领域的一颗明星,其本质是将多个决策树组合起来。基础是“自助法”(Bagging):从原始数据中多次有放回地采样,每个样本训练一棵树,预测时对所有树的输出取平均。
随机森林进一步引入了随机性:在构建每棵树时,不选择最优分割点,而是随机选取一部分特征进行次优分割。这样做出的树虽然单个可能不够精准,但多样性更高,组合后的整体准确率往往非常惊人。如果你用单棵决策树已经获得了不错的结果,试试Bagging,通常会更好。
10. Boosting和AdaBoost
Boosting是另一种集成学习思路,它通过依次训练多个弱分类器来构建一个强分类器。第一个模型拟合原始数据,第二个模型专门纠正第一个模型犯的错误,以此类推。AdaBoost是这一思想的经典实现,专注于二分类问题。
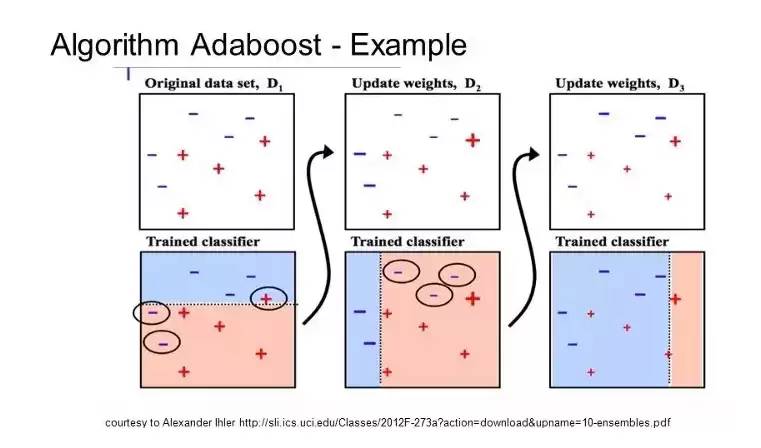
AdaBoost通常使用浅层决策树。每训练完一棵树,它会根据当前模型对每个训练样本的表现来调整权重:预测错误的样本权重增加,正确的样本权重降低。下一棵树会重点学习那些难以预测的样本。所有树训练完成后,预测时根据每棵树的准确率加权投票。由于算法对错误样本的执着,数据清洗时务必剔除异常值,否则它会把大量精力花费在噪声上。