机器学习算法中有许多关键参数和核心概念,深入理解这些内容对于模型调优至关重要。下面系统梳理了几个重要知识点,从经典的SVM参数设置到模型评估指标,逐一进行详细解读。
1. 支持向量机(SVM)的C参数
SVM中的C参数主要用于控制模型对错误分类的容忍程度。当C值设置得比较小时,模型对分错样本的惩罚力度相对较弱,此时决策边界会显得更加“宽容”,允许出现较多的分类错误,但能够换取更大的分类间隔。反之,如果C值很大,模型就会极力避免任何分错的情况,追求尽可能少的误分类,导致决策边界变得非常紧凑、间隔缩小。值得注意的是,这种惩罚并非一视同仁,而是与数据点到决策边界的距离成正比——数据点偏离得越远,受到的惩罚就越重。
2. 具有RBF内核的SVM的Gamma参数
对于采用RBF核函数的SVM而言,Gamma参数控制着单个训练样本的影响力辐射范围。Gamma值较低时,意味着相似半径较大,许多数据点会被归为同一类别;Gamma值较高时,则表明只有彼此距离非常近的点才被视为同一类。需要特别警惕的是,如果Gamma值设置得过大,模型很容易出现过拟合——它只会识别那些紧挨在它身边的数据点。
3. 是什么使逻辑回归成为线性模型
逻辑回归的基础是逻辑函数(也就是Sigmoid函数),它能够将任意实数映射到0到1之间,从表面上看这体现出一种非线性关系。但逻辑回归本身却是一个线性模型,这究竟是什么原因呢?
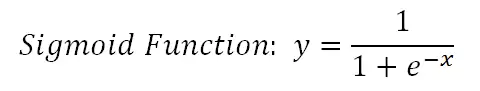
我们可以从Sigmoid函数出发,推导出其中的线性关系:
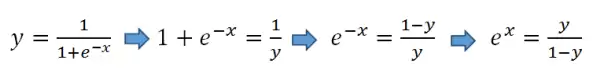
对等式两边取自然对数:
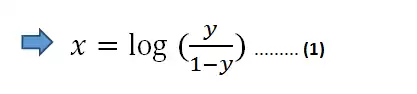
在公式(1)中,我们可以用线性方程z来替代x:
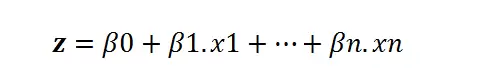
于是等式(1)可以改写成:
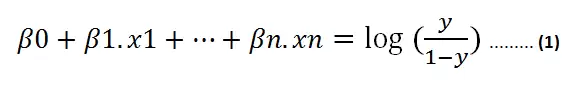
假设y是正类的概率,当这个概率等于0.5时,右边的值就变成了0——这时候我们实际上得到了一条需要求解的线性方程。逻辑回归的“线性”本质就体现在这里。
4. PCA中的主要组成部分
主成分分析(PCA)是一种经典的线性降维算法,其目标是在减少特征数量的同时,尽可能多地保留原始数据中的信息。信息量的多少通常用方差来衡量:方差越高的特征,往往携带了更有价值的数据分布信息。主成分本质上就是原始数据特征的一个线性组合。
5. 随机森林
随机森林通过装袋(Bagging)方法进行构建,每一棵决策树都是并行工作的独立评估器。这个算法之所以表现出色,很大程度上归功于它使用了彼此不相关的决策树——如果所有树都高度相似,那么集成结果只能得到一个和单棵树差不多的效果。随机森林通过自助采样和特征随机选择两种策略,有效确保了树与树之间的多样性。
6. 梯度增强决策树(GBDT)
GBDT采用提升(Boosting)方法将多棵决策树串联起来,把若干个弱学习器按顺序组合成一个强学习器。每一棵新树都会去拟合前一棵树留下的残差。与装袋方法不同,提升方法并不依赖自助采样,每加入一棵树,它面对的始终是初始数据集的一个修正版本。
7. 增加随机森林和GBDT中的树的数量
在随机森林中增加树的数目,通常不会引发过拟合问题——当树的数量达到一定程度后,准确率不再提升,但也不会因为树太多而变差。当然,考虑到计算资源的限制,也不建议无限制地增加树的数量。但GBDT的情况则有所不同:树的个数是影响过拟合的关键变量,树太多会直接导致过拟合,因此必须在适当的时候停止生长。
8. 层次聚类 vs K-均值聚类
层次聚类不需要提前指定聚类的数量,而K-均值算法必须预先设定K值。层次聚类每次运行都能得到相同的结果,而K-均值则可能因为质心初始化的不同而产生不同的聚类结果。此外,层次聚类的计算速度要慢得多,尤其是当数据集规模较大时,运行起来非常耗时。
9. DBSCAN算法的两个关键参数
DBSCAN是一种能够处理任意形状聚类的算法,同时也是检测异常值的有力工具。它的两个关键参数是:
- eps:邻域半径,如果两个数据点之间的距离小于或等于eps,就认为它们是邻居关系。
- minPts:定义为一个集群所需的最小数据点数目。
10. DBSCAN算法中的三种不同类型的点
根据eps和minPts的设定,DBSCAN将数据点划分为三种类型:
- 核心点:在自己的eps半径区域内至少包含minPts个点(包括自身在内)。
- 边界点:可以从核心点到达,但自身周围的数据点数目少于minPts。
- 离群点:既不是核心点,也无法从任何核心点到达。
假设minPts=4,图中红色点属于核心点,因为周围半径eps内至少有4个点;黄色点是边界点,它们虽然能够连接到核心点,但自身周围少于4个点(比如点B和C周围只有两个点,包括自身);N则属于离群点。
11. 为什么朴素贝叶斯被称为朴素?
朴素贝叶斯算法假设所有特征之间相互独立,彼此之间没有关联。然而在现实数据中,这种假设几乎很难成立——正是这种天真的假设,使得算法获得了“朴素”的名称。不过,也正是这种简化让朴素贝叶斯的运行速度非常快,在某些应用场景下,速度比精度更为重要。它特别适合处理高维数据,例如文本分类和垃圾邮件检测等任务。
12. 什么是对数损失?
对数损失(也称为交叉熵损失)是机器学习和深度学习领域中最常用的成本函数之一。交叉熵用于比较两个概率分布之间的差异:在监督学习任务中,我们将目标变量的真实分布与模型预测的分布进行对比,由此得到的交叉熵损失就是对数损失。
13. 如何计算对数损失?
对于每一个预测结果,取真实类别预测概率的负自然对数,然后将这些值累加起来。举个例子:在一个四类分类问题中,模型对某个样本的预测概率如下:
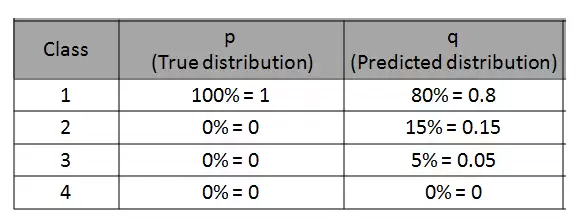
该样本的真实类别是第一个(概率为0.8),那么它的对数损失就是 -log(0.8) = 0.223。
14. 为什么我们使用对数损失而不是分类准确性?
在计算对数损失时,惩罚的重点是预测概率的置信程度。假设预测正确,概率越高(即模型越确信),损失就越低:-log(0.9)=0.105,而-log(0.8)=0.223。相比之下,传统的分类准确率、精确率和召回率只关注最终类别的匹配情况,并不关心模型有多确定。用一个只有5个样本的小例子来说明:
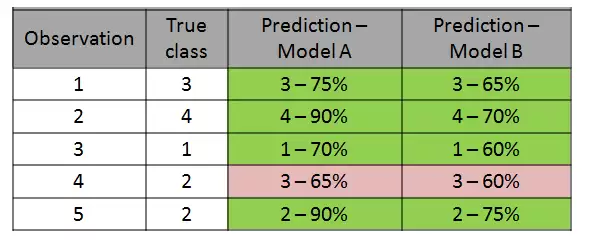
两个模型都正确分类了全部5个样本,准确率完全一样,但模型1的概率更高、更为确信。对数损失能够捕捉到这种细微的差异,因此对于分类模型能够给出更精确、更有说服力的评估。
15. ROC曲线和AUC
ROC曲线通过综合所有可能阈值下的混淆矩阵来展示模型的整体性能,而AUC则将曲线下的面积转化为一个0到1之间的数值。AUC值越高,说明模型区分正类和负类的能力越强。
16. 精确率和召回率
精确率和召回率比单纯使用分类准确率更进一步,提供了更加细粒度的评估视角。精确率衡量的是模型“预测为正”时的可靠程度——在那些被预测为正的样本中,到底有多少是真正的正类?召回率则关注实际正类中有多少被模型成功识别出来。选择侧重哪一个指标,完全取决于具体任务的目标和需求。
小结
以上系统梳理了机器学习算法中的一些基本概念和容易混淆的细节。有些要点并不仅仅针对某一种特定的算法(比如对数损失),评估模型和实现模型同样重要。每一种算法都有自己擅长的适用领域,根据手头的具体任务,选择恰当的算法并深入理解其参数含义,才是取得成功的关键。