搜索结果的精确度,通常是决定用户体验优劣的核心分水岭。本文重点探讨的是博查在语义排序领域的最新进展。先给出几个关键判断:无论是在RAG应用还是传统搜索场景下,二次排序环节正变得日益重要,其价值已远不止于简单追求召回率。
一、博查语义排序模型概述
博查近日正式发布了语义排序模型(bocha-semantic-reranker)及其配套排序API(Rerank API)。这套工具能够无缝嵌入现有搜索应用或RAG工作流中,显著提升最终呈现给用户的结果质量。
二、什么是博查语义排序模型(Bocha Semantic Reranker)?
通俗地讲,Bocha Semantic Reranker是一种基于文本语义的排序模型。它的核心职责并非从头检索,而是在已有初步排序结果的基础上进行“精加工”。
在典型的搜索推荐系统中,通常先借助关键词(如BM25)、向量检索或混合检索获取一批候选结果。随后,Bocha Semantic Reranker接手——从Top-N候选列表中,利用语义信息对文档执行二次排序。它不局限于关键词是否命中,而是深入理解查询语句与文档内容之间的深层语义匹配关系,为每个文档打分并重新排定次序。正因为是二次优化,所以称为“Reranker”。
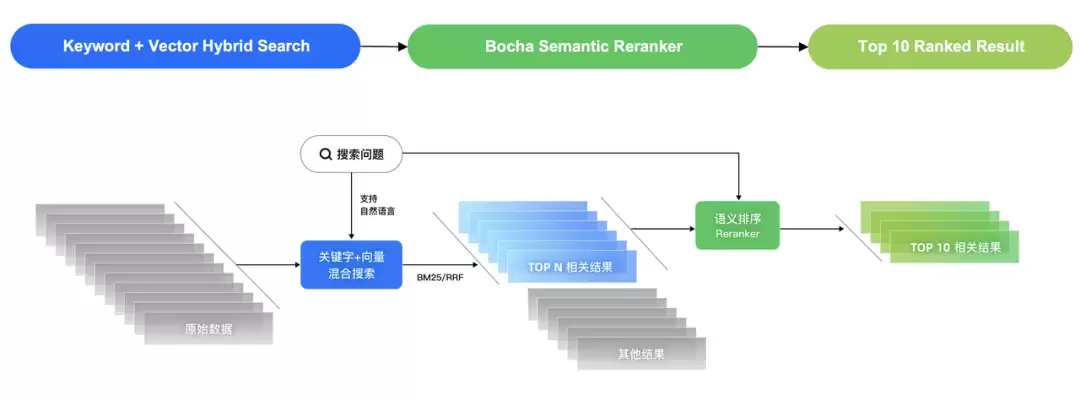
三、为什么需要语义排序模型?
传统检索方法如BM25的最大短板,在于关键词匹配的局限性。例如搜索“苹果的财报”,它可能更偏重“苹果”和“财报”这两个字面词,却忽略了“iPad的销量”与“苹果公司的营收”在语义上的高度相关性。这种表面匹配在面对复杂查询时往往力不从心。
这一短板在RAG应用兴起后尤为突出。RAG的工作流是“先检索、再生成”。如果检索到的文档本身与用户真实意图存在偏差,那么后续的生成任务即便再出色,答案也容易偏离方向。语义排序正是为了弥补这一缺口——通过深度学习与自然语言处理技术,让系统不再仅依赖关键词,而是理解查询的真实背景与用户需求。
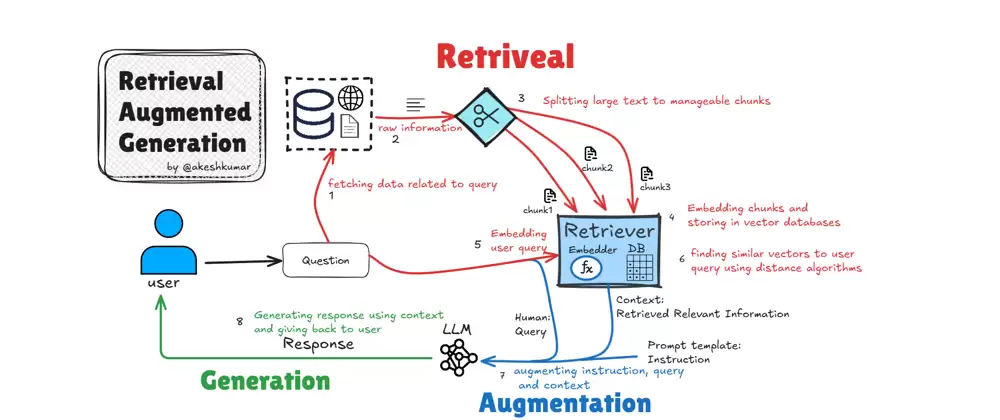
引入语义排序机制后,搜索系统能够更准确地评估文档与查询之间的语义契合度,从而为后续的生成任务提供更有价值的输入。这直接关系到最终问答质量与用户的实际体验。
四、博查语义排序模型如何评分?
评分过程非常清晰。模型会接收用户的查询语句,以及与之匹配的一组文档内容(当前支持最多512个tokens)。
评估语义相关性: 模型逐一判断每个文档是否能够回答用户的问题,或者与查询意图的匹配程度有多高。
分配Rerank Score: 每个文档会获得一个0到1之间的分数。分数越高,表示语义相关性越强。1分接近完美匹配,0分意味着几乎不相关。具体划分见下方表格:
| Score | Meaning |
|---|---|
| 0.75~1 | 高度相关,文档完整回答了问题,尽管可能包含额外信息。 |
| 0.5~0.75 | 与问题相关,但缺乏使其完整的细节。 |
| 0.2~0.5 | 有一定相关性,部分回答了问题或只涉及某些方面。 |
| 0.1~0.2 | 与问题相关,但仅回答了一小部分。 |
| 0~0.1 | 与问题无关紧要。 |
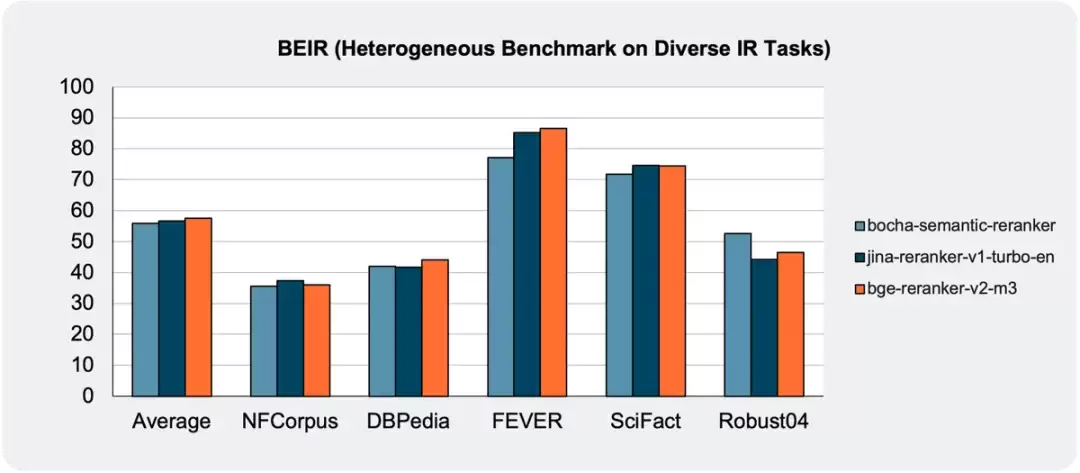
五、博查语义排序模型效果(Bocha Semantic Reranker)
在模型架构上,Bocha Semantic Reranker基于Transformer,参数规模控制在80M。别看参数量不大,其排序效果却能接近目前一线280M甚至560M参数的模型。这意味着它拥有更快的推理速度和更低的成本,在同类产品中性价比相当突出。
六、如何使用博查排序API(Bocha Semantic Reranker API)?
使用步骤
注册开发者账户: 访问博查AI开放平台,扫码登录并创建账户。平台目前提供Web Search API、AI Search API、Agent Search API以及Semantic Reranker API。
获取API KEY: 在首页右上角或左侧菜单找到“API KEY管理”,新建一个KEY并妥善保存。调用API时需要用到。
查看支持的模型列表: 目前支持三种模型:
bocha-semantic-reranker-cn、bocha-semantic-reranker-en(需邀测使用)和gte-rerank(可直接使用)。调用博查排序API: 下面是一个调用示例,展示了如何传入查询和文档数组,并指定返回Top结果。
import requests
import json
url = "https://api.bochaai.com/v1/rerank"
payload = json.dumps({
"model": "gte-rerank",
"query": "阿里巴巴2024年的ESG报告",
"top_n": 2,
"return_documents": true,
"documents": [
"阿里巴巴集团发布《2024财年环境、社会和治理(ESG)报告》(下称“报告”),详细分享过去一年在 ESG各方面取得的进展。报告显示,阿里巴巴扎实推进减碳举措,全集团自身运营净碳排放和价值链碳强度继续实现“双降”。集团亦持续利用数字技术和平台能力,服务于无障碍、医疗、适老化和中小微企业等普惠发展。阿里巴巴集团首席执行官吴泳铭在报告中表示:“ESG的核心是围绕如何成为一家更好的公司。25年来,我们与ESG相关的行动所构成的公司底色,与创造商业价值的阿里巴巴一样重要。在集团明确‘用户为先’和‘AI 驱动’的两大业务战略的同时,我们也明确ESG作为阿里巴巴基石战略之一的定位不变。阿里巴巴在减少碳排放上取得扎实进展。",
"ESG的核心是围绕如何成为一家更好的公司。今年是阿里巴巴成立25年。25年来,阿里巴巴秉持“让天下没有难做的生意”,协助国内电商繁荣发展;坚持开放生态,魔搭社区已开放了超3800个开源模型;助力乡村振兴,累计派出了29位乡村特派员深入27个县域;推动平台减碳,首创了范围3+减碳方案;坚持全员公益,用“人人3小时”带来小而美的改变……这些行动所构成的公司底色,与创造商业价值的阿里巴巴一样重要。我希望这个过程中,每一个阿里人都能学会做难而正确的选择,保持前瞻、保持善意、保持务实。一个更好的阿里巴巴,值得我们共同努力。阿里巴巴二十多年来坚持不变的使命,是让天下没有难做的生意。今天,这一使命被赋予了新的时代意义。"
]
})
headers = {
'Authorization': 'Bearer YOUR-API-KEY',
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
响应示例: 返回结果清晰明了,包含了每个文档的索引、原文(如果设置返回)以及相关性得分。
{
"code": 200,
"log_id": "56a3067f9b92dfd0",
"msg": null,
"data": {
"model": "gte-rerank",
"results": [
{
"index": 0,
"document": {
"text": "阿里巴巴集团发布《2024财年环境、社会和治理(ESG)报告》..."
},
"relevance_score": 0.7166407801262326
},
{
"index": 1,
"document": {
"text": "ESG的核心是围绕如何成为一家更好的公司..."
},
"relevance_score": 0.5658672473649548
}
]
}
}
接口网址
https://api.bochaai.com/v1/rerank
请求方式
POST
请求参数
请求头
| 参数 | 取值 | 说明 |
|---|---|---|
| Authorization | Bearer {API KEY} | 鉴权参数,示例:Bearer xxxxxx,API KEY请先前往博查AI开放平台 > API KEY 管理中获取。 |
| Content-Type | application/json | 解释请求正文的方式。 |
请求体
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| model | String | 是 | 排序使用的模型版本。 当前版本模型:
|
| query | String | 是 | 用户的搜索词。可以是自然语言,例如:告诉我阿里巴巴2024年ESG报告的重点 |
| documents | Array | 是 | 需要排序的文档数组。最多50个文档。 |
| top_n | Integer | 否 | 排序返回的Top文档数量。默认与documents数量相同。 |
| return_documents | Boolean | 否 | 排序结果列表是否返回每一条document原文。 默认:False |
响应定义
| 参数 | 类型 | 说明 |
|---|---|---|
| code | Integer | 状态码。200 代表调用成功。 |
| log_id | String | 请求id。 |
| msg | String | 状态信息。 |
| data | Object | 返回的结果。 |
| data.model | String | 排序使用的模型。 |
| data.results | Array | 排序结果。 |