先梳理一下基础问题:什么叫模型参数?参数数量跟模型性能到底有多大关系?这其实是个挺值得聊的话题。我们常听说“这个模型有7B参数”“那个有175B参数”,这些数字背后到底是什么含义?它们怎么算出来的?参数跟Token又是什么关系?参数越多是不是就一定代表模型越强?下面一点点拆解。
什么是模型参数?
在AI领域,模型参数可以理解为模型内部用来学习和理解数据的核心“调节因子”。它们决定了模型怎么处理输入信息、怎么生成输出结果。
简单说,参数就是模型从数据里提取规律的关键,也是它完成各种任务的基础。为了让模型表现更好,这些参数需要在训练中不断调整和优化。每个参数都对应着模型的一部分行为——比如怎么解读输入内容、怎么生成答案。调整参数的过程,其实就是模型学习的方式。通常,参数越多,模型能捕捉到的规律和细节就越丰富,但这也意味着需要更多的计算资源和训练时间。
模型参数大体上分两类:
- 权重(Weights):这是模型最核心的参数,用来表示不同输入特征的重要性。比如在判断一句话的情感时,“开心”这个词可能比“天气”更重要,所以“开心”的权重会更高。
- 偏置(Bias):这是一个额外的调整值,用来微调模型的预测结果。它就像给公式加了一个“校正项”,让模型更灵活地适应不同情况。
为了更直观地理解,不妨用个做菜的例子:
- 权重好比你对每种食材的重视程度。盐、糖、酱油的比例决定了菜的味道——盐多了菜就咸,糖少了就不够甜。AI模型里的权重也是这个道理,决定了每个输入特征的重要性。
- 偏置就像调味时加的那一点点柠檬汁或辣椒粉,不是主角,却能起到微妙的平衡作用。在AI模型中,偏置是个固定数值,用来调整输出,避免模型过于自信或偏差。
总结一下:权重和偏置共同决定了模型的能力,两者缺一不可。没有权重,模型无法正确处理输入;没有偏置,模型可能过于依赖输入数据,导致预测不准确。
- 权重:决定了输入数据对结果的影响程度。
- 偏置:为模型提供了一个基准调整值,让它更灵活。
不过,要准确计算权重和偏置的数量,还需要先了解一些辅助概念,比如节点之间的连接数。这些概念本身不是参数,但却是推导参数数量的基础。接下来讲计算方法。
参数总数是怎么算出来的?
当我们说某个模型有“7B参数”时,这实际是指模型中所有权重和偏置的总和。“B”是Billion(十亿)的缩写,所以“7B参数”意味着模型里有70亿个需要学习和调整的变量。那么,这70亿个参数是怎么来的?
在回答这个问题前,得先弄明白为什么要计算模型参数:
- 模型的复杂度如何?参数数量直接反映复杂程度。参数越多,模型越强大,能捕捉更复杂的数据模式;但过多参数也可能导致过拟合或增加计算成本。
- 信息如何流动?神经网络的核心机制是通过节点之间的连接传递信息。连接的数量和强度(权重)决定了信息流动能力。
- 模型的学习能力如何?权重和偏置是学习的关键。权重表示连接的重要性,偏置提供基准调整值。
- 计算资源需求如何?参数越多,需要的存储空间、计算能力和训练数据就越大。
计算模型参数需要分步进行:
- 计算节点之间的连接数:确定权重的数量。连接数描述了信息流动的路径数。
- 计算每条连接的权重数量:权重数等于连接数。
- 计算每个节点的偏置数量:偏置数等于节点数。
- 汇总某一层的总参数数:包括该层所有权重和偏置。
- 计算整个模型的总参数数:将所有层的参数数相加。
注意,虽然“连接数”等概念不是核心参数,但它们是计算权重数量的基础。下面逐一展开。
1. 计算节点之间的连接数
为什么要计算连接数?连接数是信息流动的基础,直接决定了权重数量。每条连接对应一个权重,所以需要先计算两层之间的连接数。连接数如果不足,模型可能无法捕捉复杂模式;如果过多,可能导致资源浪费或过拟合。
计算公式:在神经网络中,每一层的节点会与下一层的所有节点建立连接。连接数等于第一层节点数N乘以下一层节点数M,即N×M。
用快递员送包裹来类比:假设有N个入口(第一层节点),M个出口(下一层节点),每个入口要送包裹到所有出口,需要的路线数就是N×M。在神经网络里,这些“路线”就是节点间的连接线。
2. 计算每条连接的权重数量
权重表示每条连接的强度值,决定了信息传递的重要性。权重数量等于连接数,即两层之间的权重数量为N×M。
还是快递的例子:如果有12条路线,每条路线需要一个“优先级系数”(比如1到10之间的数字),那么就需要12个这样的系数。神经网络里,N×M条连接就需要N×M个权重。
3. 计算每个节点的偏置数量
偏置为每个节点提供了一个基准调整值,帮助模型适应不同任务。偏置数量等于该层的节点数M。
继续用快递的例子:每个出口都有一个“调节按钮”来调整包裹分发的速度或顺序。如果有M个出口,就需要M个调节按钮。在神经网络里,偏置数等于该层节点数M。
4. 计算某一层的总参数数
某一层的总参数数是该层所有权重和偏置的总和,反映了该层的复杂程度和计算需求。计算公式为:N×M + M。其中N×M是权重数量,M是偏置数量。
如果某一层有12条路线(12个权重)和4个出口(4个偏置),那么该层的总参数数就是12+4=16。
5. 计算整个模型的总参数数
整个模型的总参数数是所有层的参数数之和:总参数数 = ∑(每层的N×M + M)。
假设模型有三层:
- 输入层到第一隐藏层:参数数为A
- 第一隐藏层到第二隐藏层:参数数为B
- 第二隐藏层到输出层:参数数为C
那么总参数数就是A+B+C。
倒推7B参数模型的计算过程
假设一组数据:
- 第一组节点数N1=10万(基于自然语言处理中常见的词嵌入维度)
- 第二组节点数M1=8万(第一层隐藏层节点数)
- 中间组节点数Mi=8万,共99组(假设模型有100层隐藏层,首尾单独计算)
- 最后一组节点数Mout=5千(输出任务的目标类别数)
计算步骤如图所示:
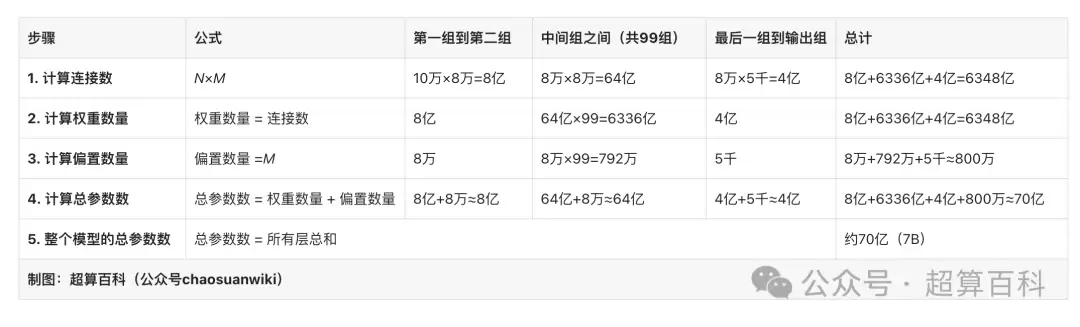
小结一下:
- 第一组到第二组贡献约8亿参数
- 中间组之间贡献约6336亿参数
- 最后一组到输出组贡献约4亿参数
加起来接近70亿(7B)参数。这个假设是合理的,因为词嵌入维度、隐藏层规模和层数都符合大型深度学习模型的特点。
虽然过程中用到了“连接数”等辅助概念,但模型的参数总数仍然由权重和偏置组成,总计约70亿个。
模型参数和Token有什么关联或区别?
很多人容易把“模型参数”和“Token”搞混,其实它们完全不同,但又密切相关。
用智能音箱来比喻:
- 模型参数就像音箱内部的零件和电路板,决定了音箱如何工作。一旦制造完成,这些零件就不会再变。
- Token则是你对音箱说的话和音箱的回答。比如你说“播放一首歌”,这句话会被拆成几个Token:“播放”“一首”“歌”。音箱根据这些Token来理解指令。
两者的关联:模型参数决定了模型如何处理Token。当模型收到一个Token时,它会根据权重和偏置计算出这个Token的含义,并生成输出。更多的参数能让模型更好地理解和生成复杂的Token序列。
两者的区别:模型参数是模型内部的东西,用户看不到,是固定的;Token是用户和模型交互的内容,可见且数量取决于输入和输出的长度。
参数越多=模型越强?
这个说法对了一半,但也需要注意一些问题。
更多参数=更强的学习能力
参数越多,模型能捕捉的数据模式越复杂。就像记忆力超强的人能记住更多细节并总结规律。比如175B参数的模型通常比7B参数的模型更擅长处理长篇文章或生成高质量内容。
参数多≠模型性能一定好
参数数量不是唯一决定因素。如果训练数据质量差或模型设计不合理,参数再多也可能导致过拟合——模型只记住了训练数据,但无法应对新问题。就像学生死记硬背课本内容,考试遇到稍微变化的题目就懵了。
参数数量与计算成本成正比
更多参数意味着需要更多计算资源和时间来训练模型。训练7B参数模型可能只需要几天,而训练175B参数模型可能需要几个月,甚至需要成千上万块高性能GPU支持。OpenAI的GPT-3训练一次成本高达数百万美元,即便Meta的Llama系列参数量较少,也需要强大的计算集群。
参数数量的未来趋势
研究人员正在探索更高效的模型:
- 稀疏模型:只激活部分参数,减少计算量,像人脑一样不是所有神经元同时工作。
- 模型压缩:将大模型“瘦身”成小模型,尽量保留性能,方便在手机等设备上运行,比如通过知识蒸馏技术。
- 混合架构:结合不同规模的模型,用小模型处理简单任务,大模型处理复杂任务,平衡性能和资源消耗。
话说回来,参数数量虽然重要,但并不是唯一的追求目标。未来的AI模型会更加注重效率和实用性,而不是一味堆参数。
总之,模型参数是AI模型的核心组成部分,直接决定了学习能力和任务表现。参数越多,模型通常能处理更复杂的任务和更广泛的数据模式,但也意味着更高的计算成本和训练需求。当我们说“7B”或“175B”时,实际是指权重和偏置的总和——权重控制输入信息的重要性,偏置微调输出结果,两者共同定义了模型的行为和性能。