RAG系统为何选择向量检索?深度解析传统关键字检索的局限性
在搭建RAG系统时,为什么开发者普遍采用向量检索,而非沿用传统的关键字检索?这背后实际上是一道不容忽视的技术抉择。简单来说,向量检索能够有效弥补关键字检索的固有缺陷,显著提升检索的准确性与效率。
那么,关键字检索的“硬伤”究竟体现在哪里?向量检索又是如何解决这些问题的?接下来,我们逐一深入剖析。
关键字检索的局限性
传统的关键字检索,核心依赖词频统计——例如BM25这类基于倒排索引的算法。它只识别字面,不理解语义。换句话说,它只能匹配完全相同的词语,根本无法捕捉深层含义。这导致以下几个常见问题:
- 语义理解不足:当你搜索“苹果公司最新产品有哪些?”时,它可能将关于水果“苹果”种植技术的文档也检索出来。原因仅仅是字面上都包含“苹果”二字。这种尴尬情况在实际系统中并不鲜见。
- 模糊表达和拼写错误:用户输入“人工智障”这样的错别字,或者描述非常模糊(例如“那个很火的AI工具叫什么来着”),关键字检索基本上束手无策。
- 长尾查询支持不足:当查询包含多个关键词、句子结构复杂时,召回率会急剧下降——因为每个词都需要精确匹配,缺少任何一个都会导致检索失败。
简言之,关键字检索就像一个“死脑筋”,你说了什么它才找什么,你说不清楚它就什么也找不到。
向量检索的优势
向量检索的出现,本质上是从“字面匹配”跃迁到“语义匹配”。它将文本转换为高维向量,然后计算向量之间的相似度(例如余弦相似度),从而找到最相关的内容。这一机制带来的优势十分显著:
- 语义理解能力强:即使查询与文档中没有完全相同的词语,甚至语言不同,向量检索也能根据语义关联将相近内容提取出来。举例来说,搜索“为什么下雨前蚂蚁会排队搬家?”,文档可能根本没有提及“蚂蚁搬家”,但向量检索能够通过语义关联到“昆虫感知气压变化”这类科普信息。这才是真正理解用户意图。
- 处理模糊表达和拼写错误:向量检索对拼写错误和模糊描述具有天然的容错能力。输入“人工智障”照样能匹配到“人工智能”相关的文档,因为在向量空间中这两个词的语义距离非常接近。
- 支持复杂查询:即使查询包含多个关键词、复杂句式,向量检索仍能保持较高的召回率和相关性。它不再依赖单个字词的匹配,而是着眼于整体语义。
向量检索与RAG系统
在RAG(检索增强生成)系统中,向量检索扮演着核心引擎的角色。它负责从海量数据中快速找到与用户查询语义最匹配的内容片段,并将这些片段提供给大模型用于后续生成。
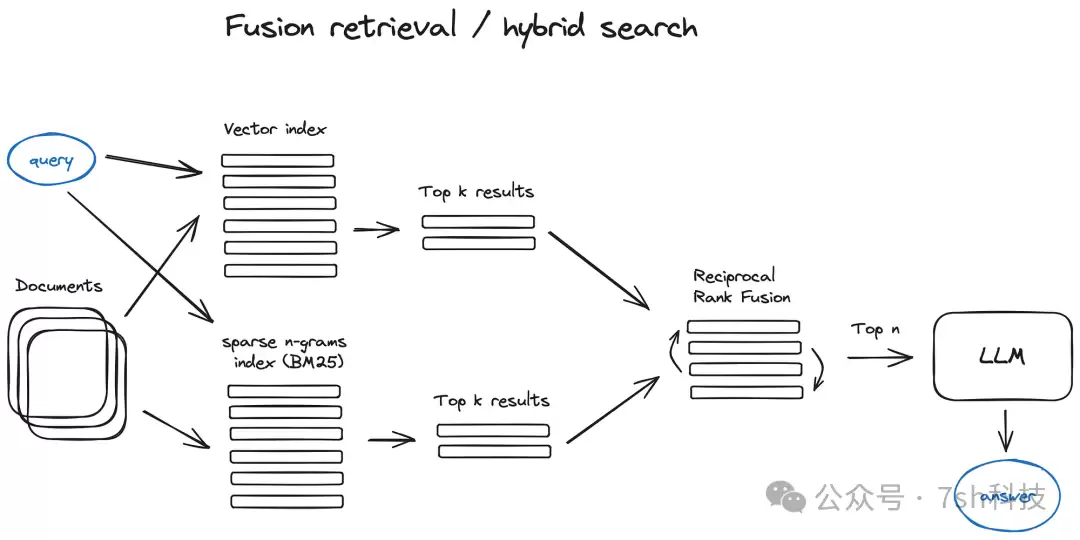
具体而言,向量检索在RAG中具有三重价值:
- 高效性:向量数据库(如Milvus、Faiss)支持高维向量的快速相似性搜索,能够在百万甚至十亿级别的数据集中毫秒级返回结果。没有这一能力,RAG系统很难实际落地。
- 灵活性:向量检索可以搭配不同的嵌入模型(例如BGE-M3、text-embedding-3-small)以及多种向量数据库技术,选型灵活,能够适应各类业务场景。就像搭积木一样,需要什么模块就替换什么模块。
- 提升生成质量:检索到的相关上下文越精准,大模型生成的内容就越准确、越丰富。这正是RAG“检索+生成”双轮驱动机制的关键所在。
课代表小结
看到这里你可能要问:那么向量检索是否完美无缺?并非如此。在某些特定场景下,比如搜索专有名词、人名、缩写词等,传统关键字检索反而更加直接、准确。举个例子:搜索“GPT-4”这样的精确术语,向量检索可能因为语义扩散而返回一堆不相关的内容,而关键字检索可以一步到位。
因此,业界的共识是什么呢?混合搜索——将向量检索与关键字检索结合使用,取长补短。用关键字检索来兜底精确匹配,用向量检索来拓展语义覆盖。这才是目前RAG系统中最务实的做法,也是使检索效果最大化的最优解。