选择合适的大模型,提升企业AI能力,坦白说,这并非一件简单的事。核心其实就围绕几个关键方法:提示工程与上下文添加、检索增强生成(RAG)技术,以及微调模型。这三者各有侧重,企业可以根据自身情况灵活组合,才能真正让大模型为业务服务。
面对生产中部署大模型(LLM)的需求,市面上有不同训练程度、复杂度、成本和质量的模型可供选择。如何从LLM那里获得想要的结果?这里的关键在于,不同的方法对应的场景和投入完全不同。下面来逐一拆解。
提示工程并附加上下文
这是最具成本效益的起步方式。你看,预训练过的LLM在通用自然语言任务上表现已经足够惊艳,甚至只需要一个简短提示——比如一个未完成的句子或一个问题——就能触发所谓的“零样本”学习。但问题在于,用户越是能组织起详细的请求,并附上相应的示例(也就是上下文),模型给出的答案就越精准,越接近用户的预期。如果提示里只包含一个示例,这叫“一次性”学习;包含多个,就是“少量学习”。说白了,你给的“素材”越丰富,AI的“发挥”就越靠谱。
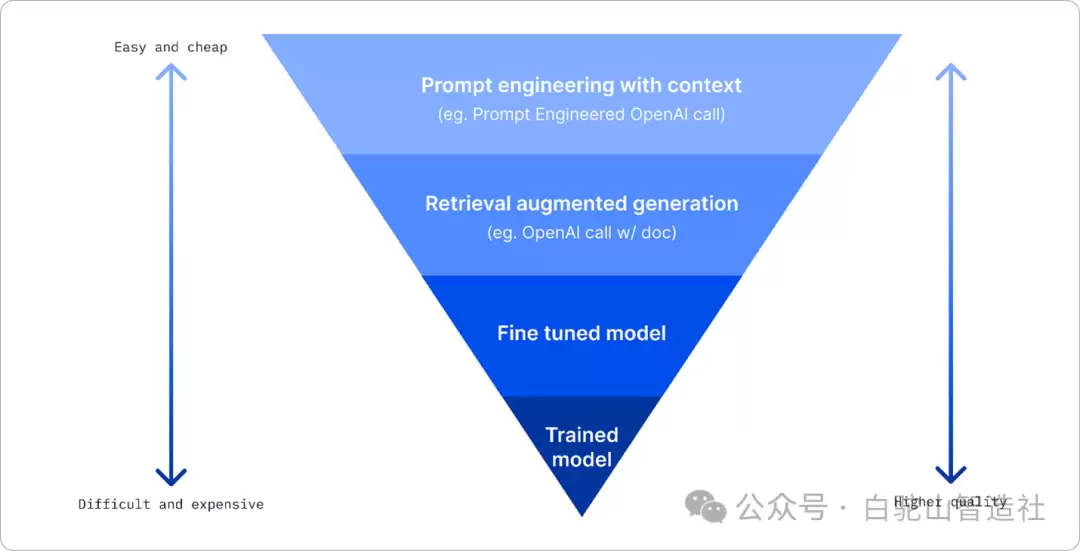
检索增强生成(RAG)
LLM有个天然短板:它只能基于训练时“见过”的数据来作答。这意味着,它对训练之后发生的新事实一无所知,更别说访问企业内部的非公开信息了。如何破局?答案是检索增强生成(RAG)。这是一种在考虑提示长度限制的前提下,利用外部数据(比如以文档块形式存在)来增强提示的技术。具体怎么实现?借助矢量数据库工具,比如Azure矢量搜索,它能从各种预定义数据源中检索出有用的信息块,动态地添加到提示上下文中。
当企业缺乏足够数据、时间或资源去微调LLM时,这个技术特别有用。它能显著提升特定工作负载的性能,同时有效降低模型“捏造”内容的风险——也就是那些脱离现实甚至有害的“幻觉”。

微调模型
微调则是另一条路。它利用迁移学习,让预训练模型“适应”特定的下游任务或解决某个具体问题。和少样本学习或RAG不同,微调的产出是一个全新的模型——权重和偏差都被更新了。这需要一套由输入(提示)和对应输出(完成)组成的训练示例。那么,什么情况下应该优先考虑微调?
首先,企业希望用微调过的、功能相对精简的模型(比如嵌入式模型)来替代高性能大模型,从而在成本和速度上获得优势。其次,延迟是关键考量,某些场景不允许使用过长的提示,或者能从模型学到的示例数量受提示长度限制。最后,企业需要有大量高质量数据、基础事实标签,以及维持这些数据长期更新的资源,才能保证模型持续有效。

训练大模型
从头开始训练一个大模型,无疑是技术栈里最硬核、也最复杂的一环。它需要海量数据、顶尖的研发团队和充沛的计算资源。除非企业拥有极其聚焦的垂直领域用例,并且积累了丰富的领域专有数据,否则一般不建议考虑这个选项。毕竟,投入与产出之间,需要非常谨慎的权衡。