随着袋里承担的任务越来越复杂,一些原先被忽略的问题开始浮出水面:
- 大规模任务下能否稳定完成工作
- 自身上下文窗口是否够用
我们的答案是尝试一种新的思路,称之为动态子袋里。听起来不算复杂:不再通过通用工具调用来分发子任务,而是让袋里自己写一段简短代码,去驱动子袋里的执行。这样一来,模型可以用它擅长的代码模式——比如循环、分支、并发——去编排逻辑,让任务更适配。
其实Deep Agents早就支持了子袋里。它的作用很明确:隔离上下文,让主袋里把一个个独立的工作单元分配出去,同时避免中间结果塞满主窗口。那为什么还要搞个动态版本?
常规子袋里的调用方式,是主模型一次一次地直接调用。小规模没毛病。但如果你需要一次生成几百个,或者编排逻辑本身就有条件判断和多个阶段,这种逐个调用的模式就会立刻崩掉。
动态子袋里的解决思路,其实是把编排逻辑写进代码里。袋里不靠逐条工具调用来推进,而是写一个简短的脚本,通过轻量级解释器去运行它,脚本负责调度子袋里。
举个更直观的例子:一份300页文档,需要每页一个子袋里去总结。传统做法是调用子袋里工具300次。而动态子袋里只写一个循环:
const results = await Promise.all(pages.map(page =>task({ description: `Summarize page ${page.number}`, subagentType: "summarizer" })));
这意味着两个关键的突破,是工具调用型编排无法稳定做到的。
确定性的规模覆盖。 没有结构约束时,袋里往往会自行判断范围,比如原本500项只挑了75项就草草收场。而一个分发循环不会有这个毛病。覆盖率变成了结构上的保障,而不是靠提示词去凑。
可靠的复杂编排。 用代码写编排比让模型重复模拟一长串工具调用来得可靠。尤其是扇出+汇总、多阶段流水线或条件分支这类场景。
这个思路和Claude Code、递归语言模型(RLM)中的工作流想法是一致的:模型写代码,代码再去调度更多的袋里。
Quickstart
要启用动态子袋里,需要两样东西:一个可以分发工作的子袋里,以及一个代码解释器——一个安全、轻量的运行时环境,供模型编写和执行编排代码。Deep Agents自带一个基于QuickJS的可选解释器。使用它很简单:先安装QuickJS中间件包,然后在create_deep_agent时通过middleware参数传入CodeInterpreterMiddleware即可。
pip install -U "deepagents[quickjs]"
from deepagents import create_deep_agent from langchain_quickjs import CodeInterpreterMiddleware agent = create_deep_agent(model="openai:gpt-5.5", middleware=[CodeInterpreterMiddleware()], )
Deep Agents内置了一个通用子袋里,可以直接在工作流里使用。如果需要更定制化的流程,可以配置自定义子袋里,设定名称、描述和系统提示词——袋里通过名称和描述知道该调用哪一个角色。
触发动态子袋里的方式很简单:在提示词中加入"workflow"这个词。像这样:
result = await agent.ainvoke({"messages": [{"role": "user", "content": "Run a workflow that reviews every file in src/routes/ and summarizes the top risks."}]})
配合编码袋里使用
体验动态子袋里最快的方式是使用dcode,这是基于Deep Agent构建的终端编码袋里。它出厂时就已经启用了代码解释器,什么都不用配置直接可用。
安装:
curl -LsSf https://langch.in/dcode | bash
运行:
dcode
触发动态子袋里,只需说“运行一个workflow”。袋里不会硬扛全部工作,也不会费劲地扩展子袋里任务,而是直接写一个编排脚本,调用内置的task()全局函数,在代码解释器中执行。比如:“运行一个workflow,审查src/下所有文件的SQL注入风险。”
子袋里启动后,dcode的界面上会实时显示它们的分组状态,按不同阶段排列。
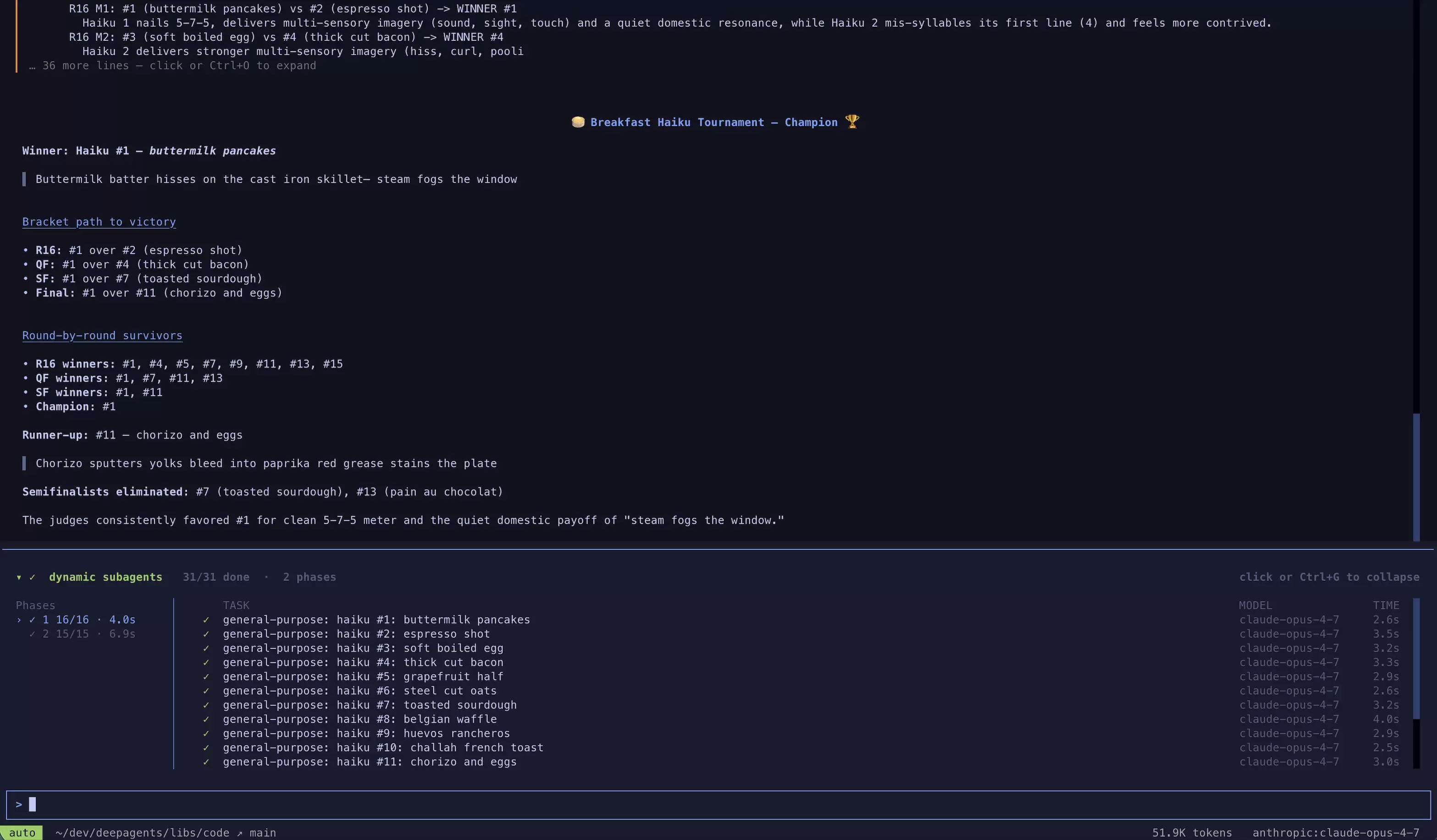
用dcode体验最快,但也可以通过ACP在其他工具(比如Zed)中尝试。
How it works
袋里会被赋予一个eval工具,它在解释器内安全地执行Ja vaScript代码。当子袋里配置好之后,解释器会暴露一个内置的task()全局函数,用来从代码中调度子袋里。根据当前任务的不同,模型会写出不同的代码——可能是循环、分支、或者是Promise.all——然后由解释器确定性地执行。
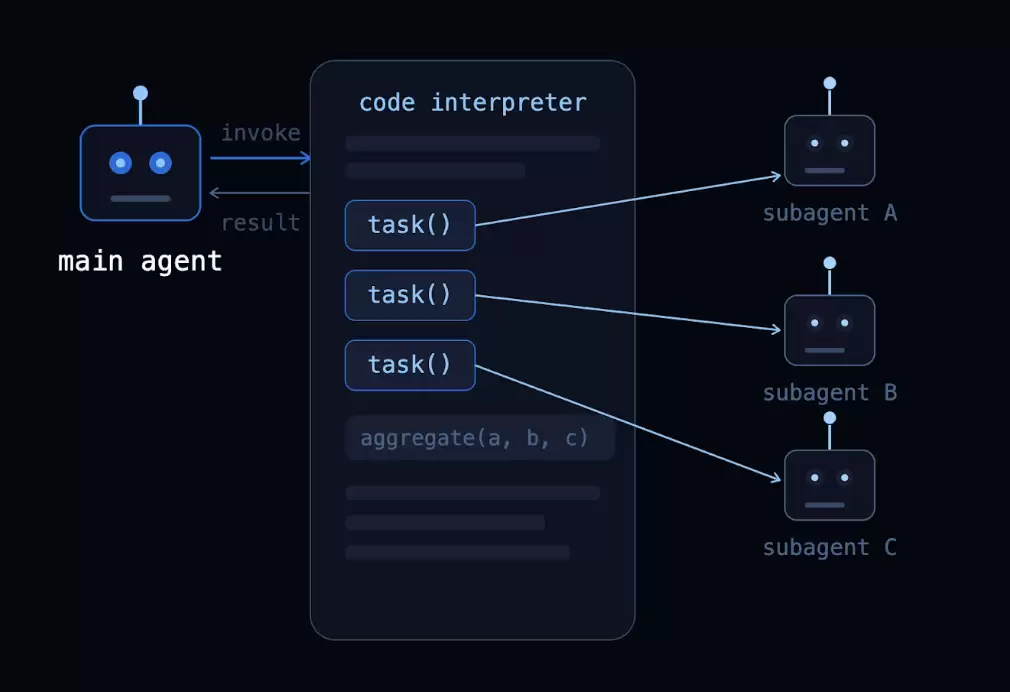
task()接收三个参数:description(描述)、subagentType(子袋里类型),以及可选的responseSchema(返回格式)。如果提供了模式,结果会直接是一个类型化的对象,方便后续过滤或传递。
const result = await task({ description: "Review src/auth/login.ts for security issues.", subagentType: "reviewer", responseSchema: { type: "object", properties: { severity: { type: "string", enum: ["high", "medium", "low"] }, issues: { type: "array", items: { type: "string" } }, }, }, }); const critical = result.severity === "high" ? result.issues : []; critical; // model sees the last line
更多细节可以查阅文档中的“程序化子袋里”和“解释器”部分。
Common Orchestration Patterns
Anthropic的动态工作流推广了一系列用于并行袋里的编排模式。这些不是你可以一键开启的功能,而是任务执行过程中自然涌现的形态,当任务变化时,袋里会自动切换到不同的模式。下表总结了每种形态适合的场景。
| 模式 | 形态 | 使用时机 |
|---|---|---|
| 分类并操作 | 按类型将每个项目路由给专门的处理单元 | 混合输入需要不同的处理方式时 |
| 扇出并综合 | 对多个项目并行执行相同操作,然后合并结果 | 多个独立单元,需要一份综合报告 |
| 对抗性验证 | 先发现,再独立验证,通过后才保留 | 误判代价高时 |
| 生成并过滤 | 生成多个候选方案,打分,保留最佳 | 探索多方案比一次命中更有效时 |
| 锦标赛 | 两两对决,胜者晋级 | 依赖主观或相对标准时 |
| 循环直到结束 | 重复多轮,直到某轮没有新发现 | 范围未知,追求完整性时 |
以下逐一说明每种模式在Deep Agents中的具体实现和实时追踪。
分类并操作
项目先分类,再根据分类结果交由专门的子袋里处理。这适用于处理混合输入的场景,不同项目需要不同的专业能力。
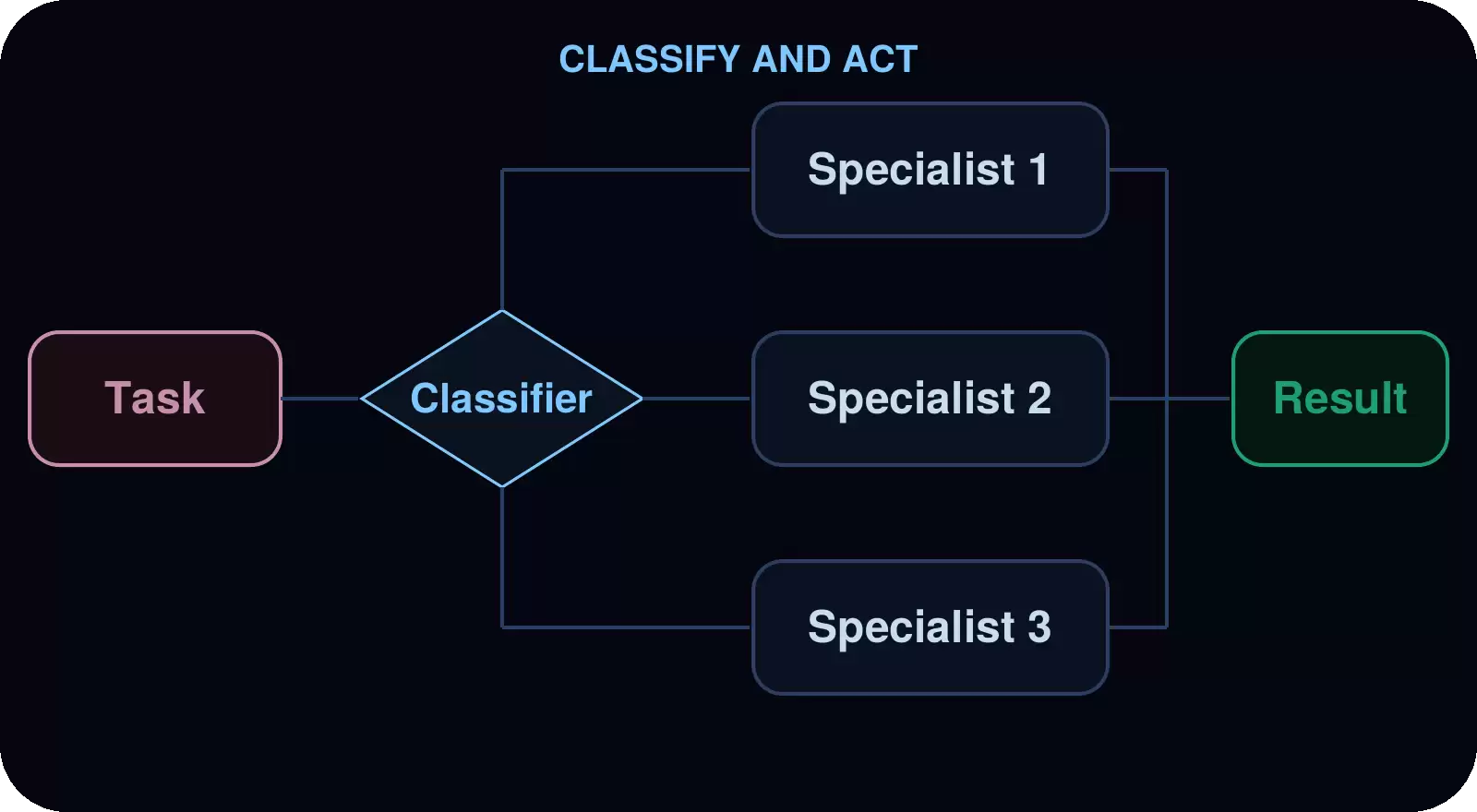
应用场景: 处理支持工单、错误日志、用户反馈,或任何需要根据类型区别对待的批量项目。
示例: 对支持工单进行分拣。袋里读取工单,将其分类为bug、功能请求或咨询。bug交给bug调查员,功能请求交给功能分析师,咨询交给支持响应员。最终输出一份按类别汇总的报告。
查看追踪记录。
扇出并综合
袋里对多个项目并行执行同一类操作,然后合并结果。
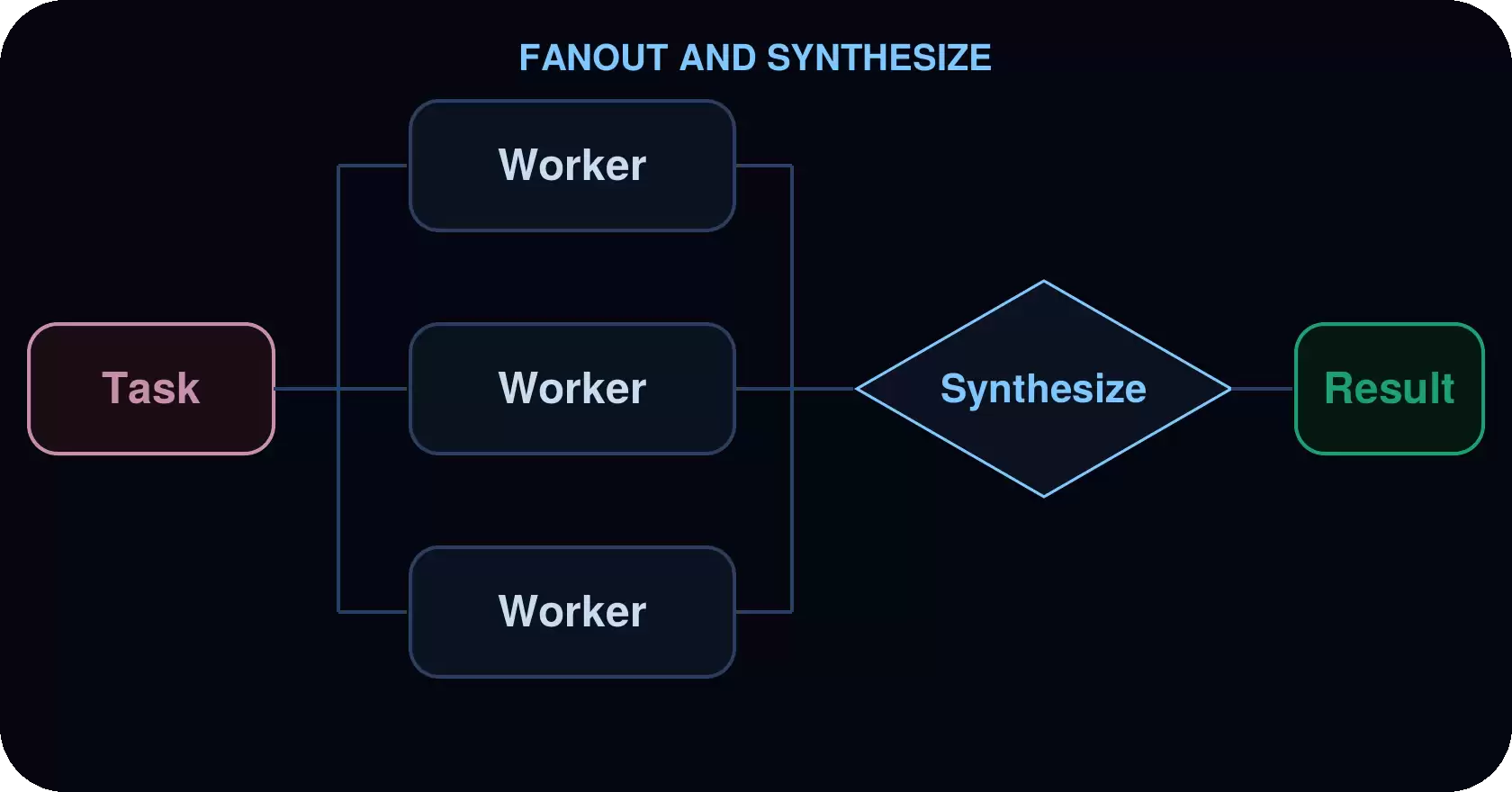
应用场景: 跨目录的代码审查、批量文档分析、日志处理、跨服务的一致性检查。
示例: 对源代码树的逐文件安全审查。袋里发现src/下的所有TypeScript文件,然后为每个文件并行分配一个安全审查员。最后将所有审查结果合并成一份按严重程度排序的报告,并标注需要修改的代码行。
查看追踪记录。
对抗性验证
这是一个两轮模式。第一轮产生发现结果,第二轮将每个结果发送给独立的验证员,只有通过独立验证的结论才会被保留。当置信度比速度更重要时,这能有效降低误判。
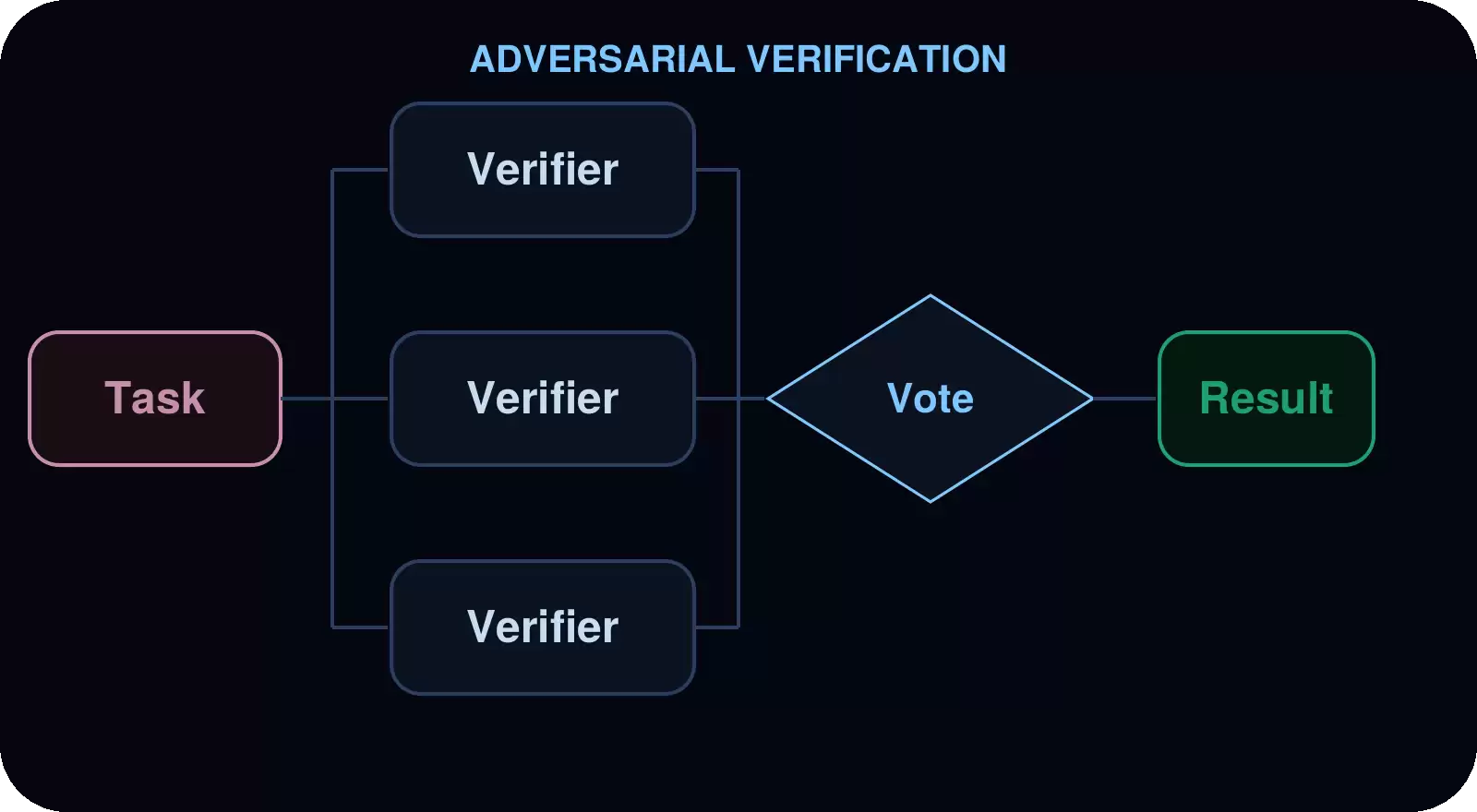
应用场景: 安全审计(误判代价高昂)、合规检查,或任何要求对发现结果有高置信度的审查。
示例: 安全审计中,误判是不可接受的。审计员先广泛扫描潜在漏洞,然后将每个发现交给一个独立验证员重新阅读代码,返回已确认或已拒绝的判定。只有被确认的漏洞才会进入最终报告。
查看追踪记录。
生成并过滤
多个子袋里就同一问题独立生成解决方案,袋里在代码中比较、打分并过滤结果,只保留最优方案。
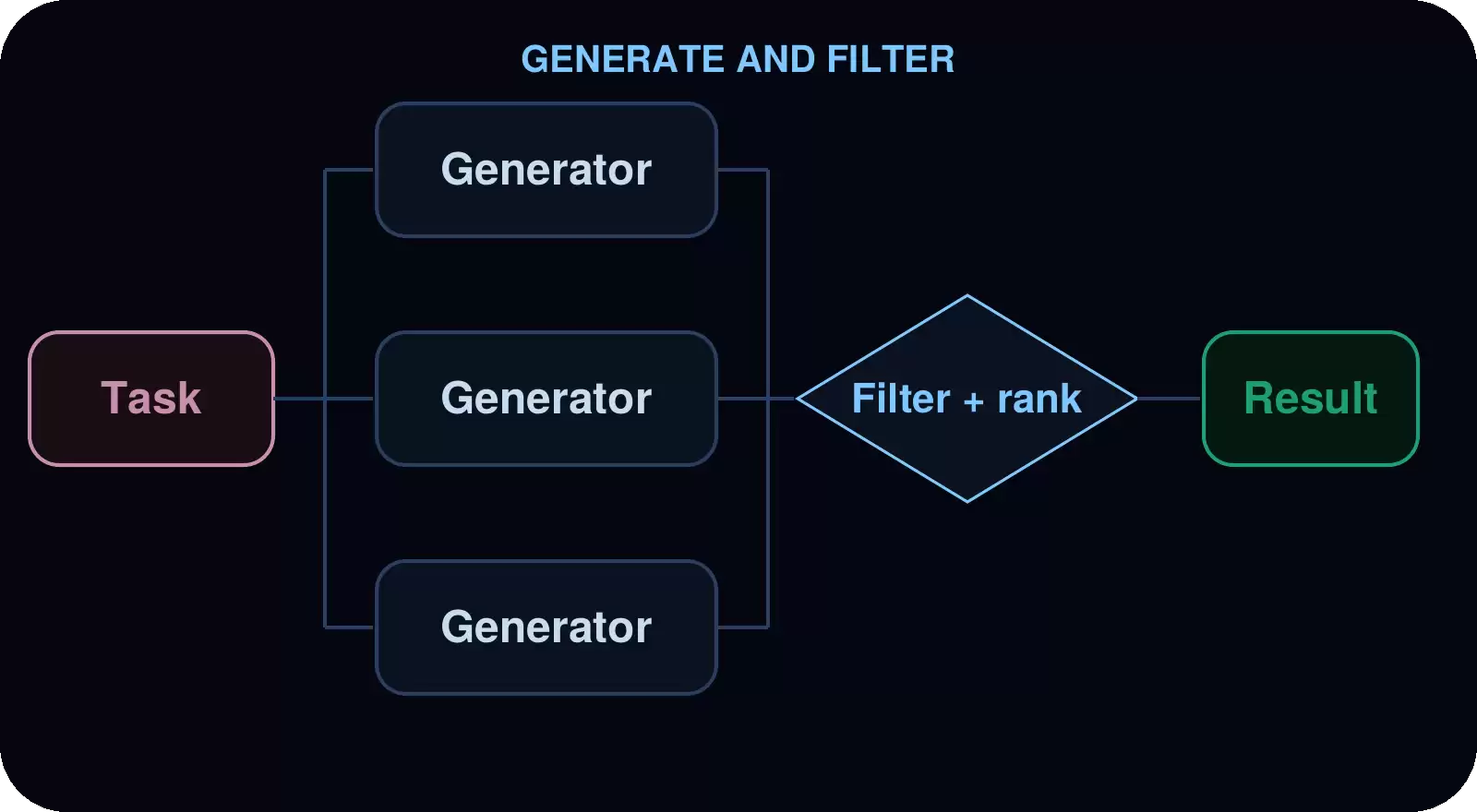
应用场景: 架构设计提案、重构方案、内容变体,或任何需要先探索多个方案再定稿的任务。
示例: 多个限流器重设计方案的排名。袋里让架构师生成几个独立的rate-limiter.ts重设计方案,每个方案写入独立文件防止覆盖。然后从突发情况下的正确性、多实例支持和复杂度三个维度打分,最强方案胜出,附上理由。
查看追踪记录。
锦标赛
备选方案由裁判子袋里进行两两对比,胜者逐轮晋级。
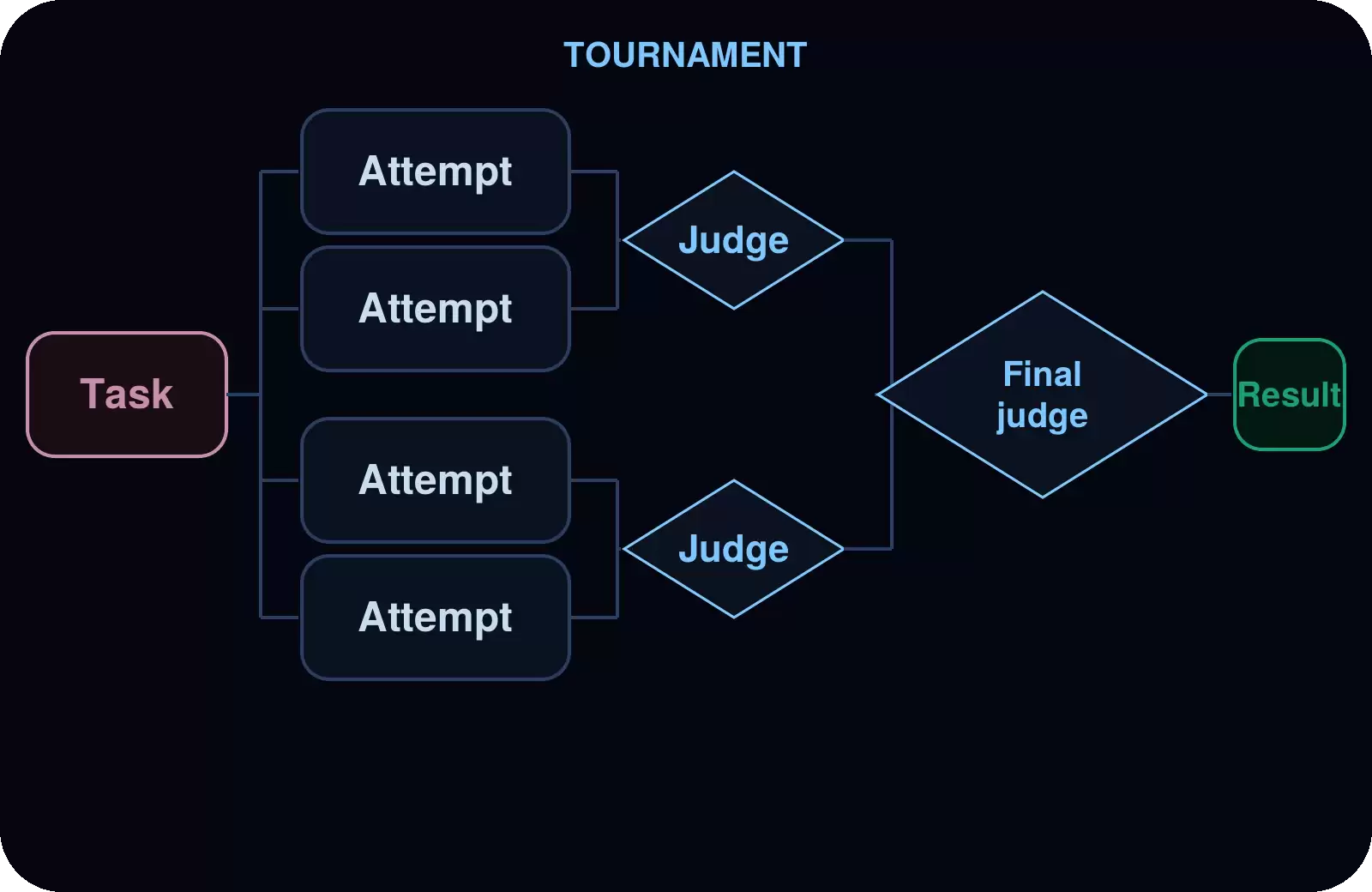
应用场景: 依赖主观标准的优化、风格选择、多个实现方案的择优。
示例: 对混乱的createOrder处理程序进行重写比赛。几位写作者各出一个重写方案,风格不同;然后裁判两两比对、逐轮晋级,直到选出最佳方案,并附上裁判的评判理由。
查看追踪记录。
循环直到结束
袋里运行一个发现循环,去重已有结果,直到不再出现新结果才停止。适用于工作范围不确定、追求彻底性的场景。
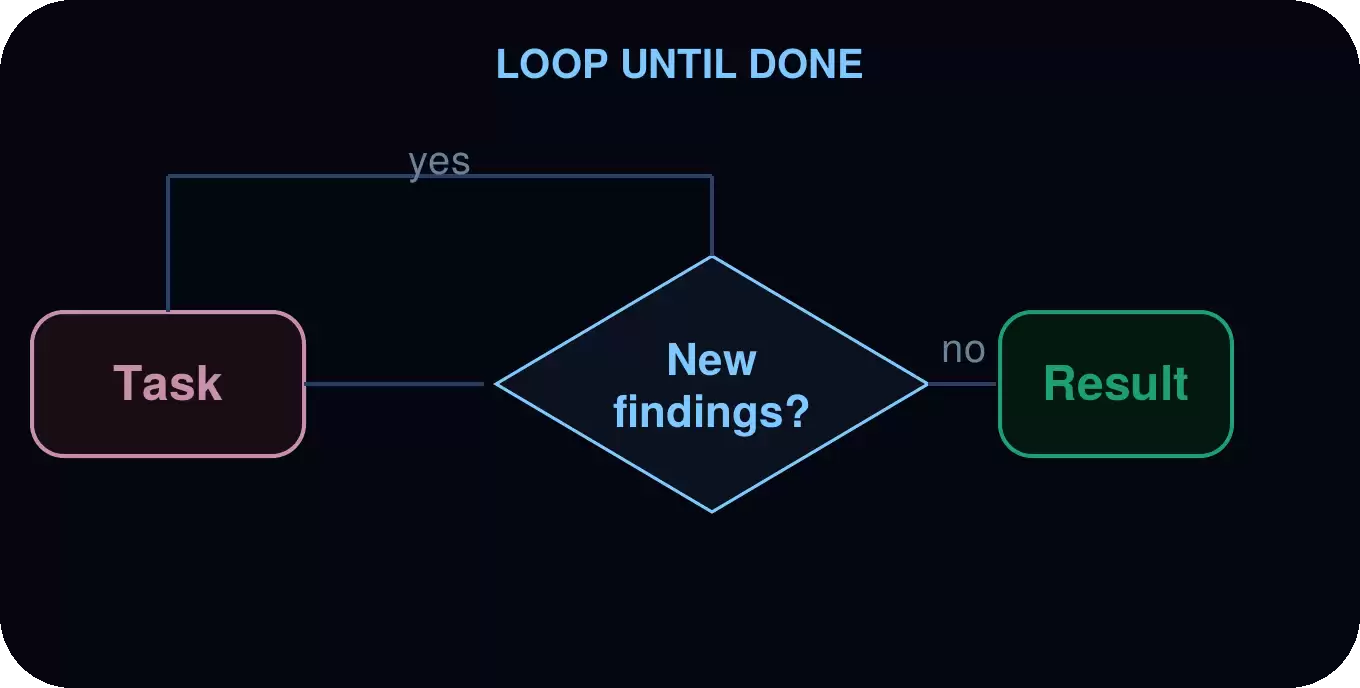
应用场景: 穷举扫描、死代码检测、依赖审计,或任何不求数量、只求完全的扫查。
示例: 安全扫描轮次运行。袋里先跑一次扫描,在代码中检查发现结果,只有当前轮次发现了新问题才启动下一轮。当某轮没有任何新问题时,它停下来,输出合并后的发现结果和总共跑了多少轮。
查看追踪记录。
Conclusion
动态子袋里的核心价值,在于它赋予了袋里更强的自主性和更高的可靠性。代码负责覆盖度和上下文管理,而模型则专注于最需要判断力的工作。上面提到的模式只是一个起点。在实践中,袋里会根据任务要求组合和混合这些模式。
这其实就是递归语言模型最朴素的呈现。一个袋里写代码,代码再去调度更多袋里。袋里可以递归地调用自身,不受上下文窗口限制,也不被固定工作流束缚。它能将问题拆解到任意深度,再以最合适的方式重组。上面这些编排模式只是冰山一角,随着模型写代码的能力越来越强,天花板还会继续抬高。
动态子袋里,就是Deep Agents今天让你亲自上手体验的东西。给袋里加一个代码解释器就能开始,或者直接用dcode——它开箱即用,一切就绪。