在日常挑选 AI 模型时,你是否曾认真思考过:最终决定使用某个模型,究竟是出于它卓越的性能表现,还是仅仅因为它的价格足够诱人?当大模型价格战愈演愈烈,性价比与真实能力之间的界限正变得越来越模糊。
就在上周,ZenMux 发起了一场颇具创意的实验,试图通过"价格拉平"来揭示开发者真实的模型偏好。他们将 GLM 5.2、Kimi K2.7 Code、Qwen3.7-Max、MiniMax M3、Doubao Seed 2.1 Pro 等十余款主流国产大模型的价格,统一调整至与 DeepSeek V4 Pro 和 DeepSeek Flash 完全相同的水平线。
当价格壁垒被彻底抹除,开发者会用 Token 为谁投票?
先来聊聊 ZenMux 为何要策划这样一场实验。
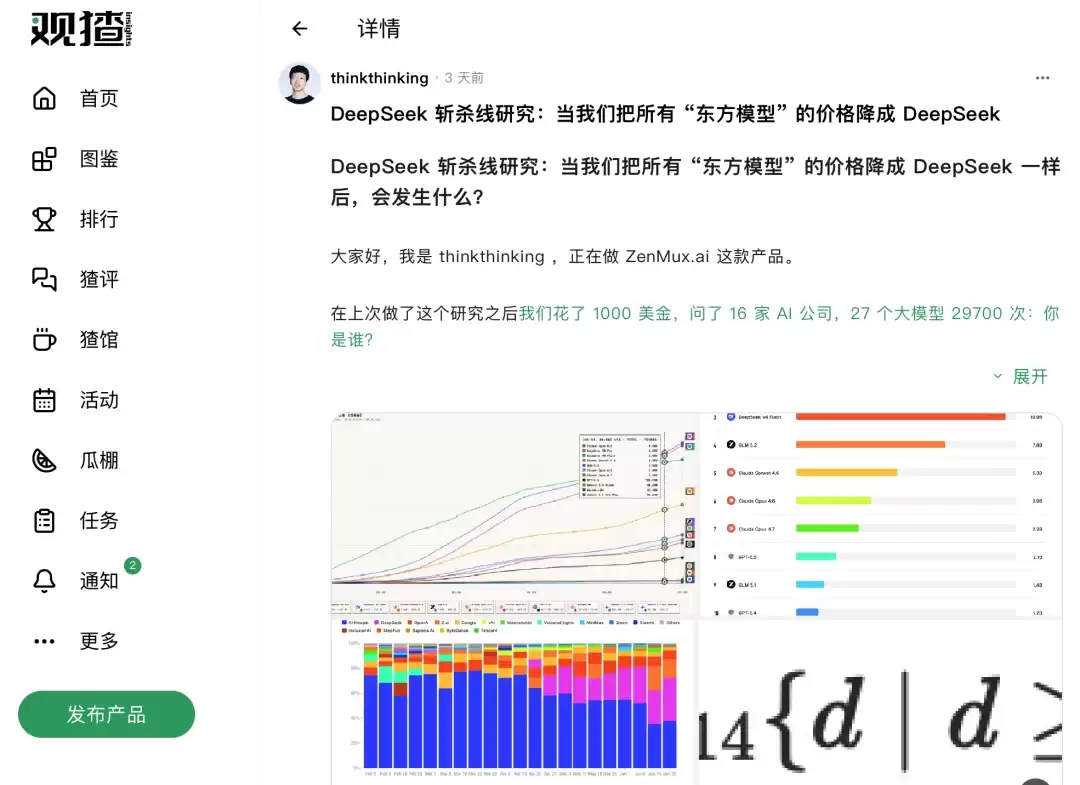
过去数周,他们在平台数据中捕捉到一个极为显著的趋势:DeepSeek 的 API 调用量呈现出爆发式增长,V4 Pro 的 Token 消耗量一度逼近 Claude Opus 4.8。与此同时,GLM 5.2 等国产模型的使用量也在快速攀升。
这就引出了一个核心问题:这一波增长,究竟是源于模型本身过硬的技术实力,还是单纯因为价格足够低廉?
如果答案是前者,说明国产大模型的能力已真正获得开发者群体的广泛认可。如果是后者,那么一旦价格优势不复存在,用户是否会毫无留恋地转向其他选项?
ZenMux 的应对策略十分干脆——直接消除价格这个干扰变量,看看在公平的起跑线上,各模型能否凭借真实表现留住用户。
此次参与实验的模型阵容相当庞大,几乎囊括了当前国内主流大模型厂商的旗舰产品:
GLM 5.2、Kimi K2.7 Code、Qwen3.7-Plus/Max、MiniMax M3、Step 3.7 Flash、Agnes-2.0-Flash、ERNIE 5.1、Ring-2.6-1T、Ling-2.6-1T/flash、Hy3 preview、MiMo-V2.5 Pro、KAT-Coder-Pro-V2、Doubao-Seed-2.1-pro/mini,全部按照 DeepSeek V4 Pro 或 Flash 的归一化价格进行了严格对齐。
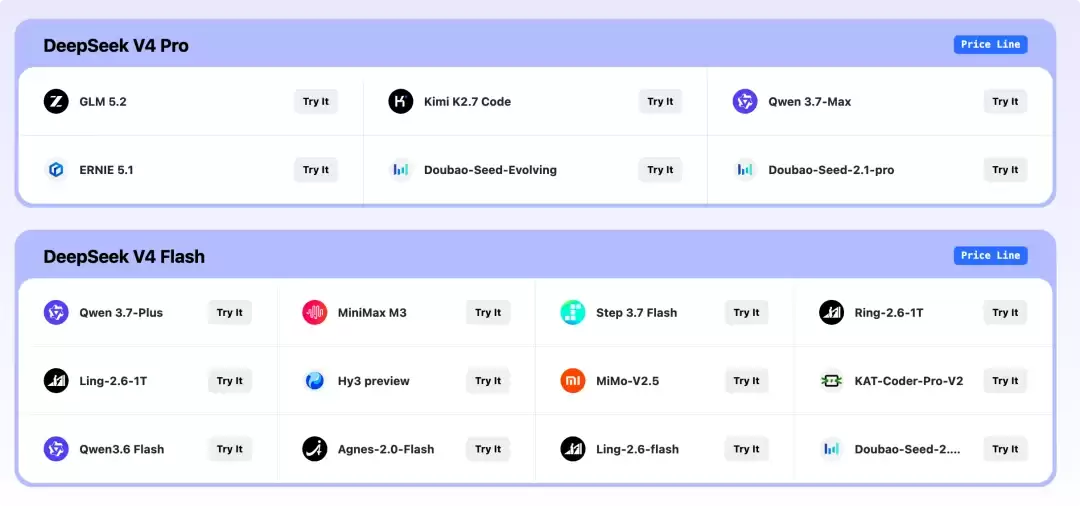
具体的价格归一化方法与计算公式,可以参考官方说明。

部分模型的降价幅度令人印象深刻。Qwen3.7 Max 的降幅高达 82.8%,GLM 5.2 直降 69.3%,Kimi K2.7 Code 也下降了 55.2%。
这些数字背后的含义非常清晰:从现在开始,你可以用 DeepSeek 的价格,随意调用参与实验的任意一款旗舰级国产大模型。
紧接着,ZenMux 又做了一个更大胆的举动:他们将所有模型的实时 Token 消耗量,以公开 Arena 榜单的形式实时呈现,任何人都可以随时查看每个模型当下的 Token 流向与热度变化。
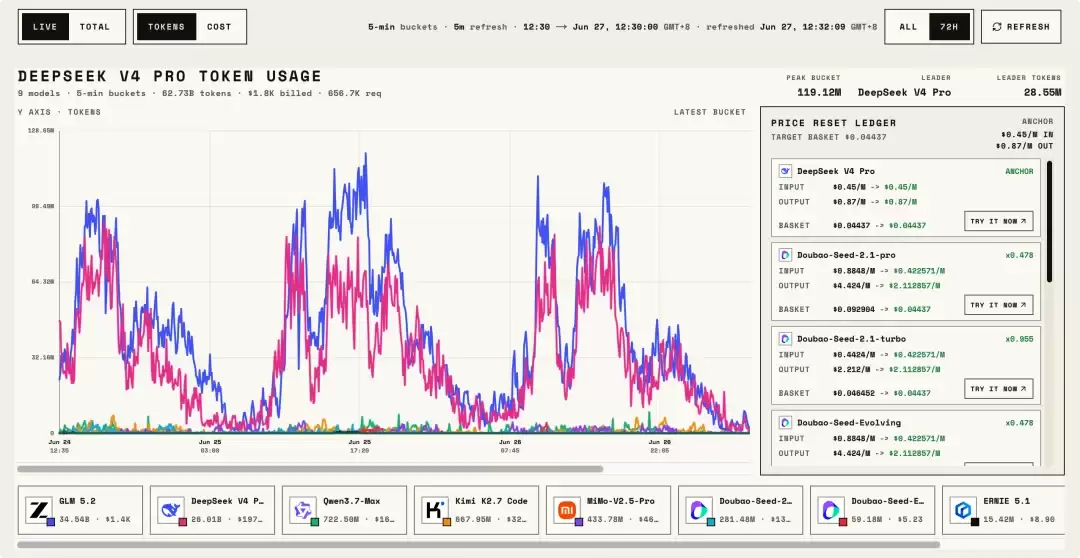
没有复杂的 Benchmark 榜单,也没有官方评测报告的背书。你的每一次真实调用,就是一次投票。每一百万 Token 的消耗,就是一张诚实的选票。

坦白讲,当我第一次了解到这个活动时,脑海中闪过一个念头:终于有人敢于用这种方式,让市场自己给出答案。
AI 模型领域一直存在一个认知困境:
发布会上,每一家都宣称自己是「最强王者」。论文中,每一篇都在各种 Benchmark 上刷出令人瞩目的高分。然而,开发者在上手使用时的真实体感,与这些光鲜的数字之间,往往存在不小的落差。
原因其实并不复杂。Benchmark 测试的是标准化、封闭式的题目,而真实世界的开发工作流千变万化、高度复杂。一个模型在 MMLU 上得分再高,如果它在你的 Agent 循环中频繁丢失上下文,或者在长代码生成任务中反复出错,你大概率不会把它纳入生产环境。
与其让专家来打分,不如让市场自己发声。当价格被拉平,开发者每天消耗的 Token,就是最直接、最诚实的能力评价。
如果你亲自动手测试一番,就会发现在公平价格条件下,各模型的表现差异可能远比想象中更明显。
参考大模型评测中流行的「开放式视觉创作」类任务,我设计了一个对模型综合能力要求颇高的挑战:让模型生成一张飞翔的西方龙 SVG 图像,输出至少 100000 个 Token,并尽可能做到逼真细腻。
为什么选择 SVG 生成?因为这是一个能全方位考验模型能力的任务。它不像写文章那样可以模糊处理或靠套路化语言凑数,SVG 要求精确的坐标计算、合理的颜色搭配、清晰的路径规划,同时还需要对「飞龙」这一概念具备足够的视觉想象力。更关键的是,要求输出至少 100000 个 Token,这迫使模型在长文本生成过程中始终保持结构一致性与逻辑连贯性,不能写到后面就开始混乱或重复。
测试指令如下:Generate an SVG of a fly dragon in the sky. 输出至少 10000 个 token,尽可能逼真。

随后,我将这个任务分别提交给几个参与实验的模型进行测试。
各模型产出的结果差异相当显著。
GLM 5.2 绘制的飞龙视觉效果最为出众,生成了一条姿态舒展、细节丰富的飞翔火龙,整体呈现相当到位。

Kimi K2.7 Code 的输出令人眼前一亮,风格偏向几何感更强的现代插画路线,龙的形态更加抽象,有点像一只翱翔于天际的大型蜥蜴,别具一格。

Qwen3.7-Max 选择了较为写实的表现手法,但尾巴部分略显冗长,整体看起来有点像一条大型昆虫。

DeepSeek V4 Pro 的生成结果相对中规中矩。

MiniMax M3 则带来了一个小惊喜,它生成的龙细节丰富,虽然形态上有点像一根大香肠,但视觉冲击力在几个模型中属于较强的水平。

这个测试让人真切地感受到:当价格壁垒被彻底移除之后,不同模型之间的能力差异确实清晰可见,而且这种差异并非简单的「谁好谁坏」能概括,而是体现在风格取向、擅长领域、长输出稳定性等多个维度的综合较量。
截至撰写本文时,ZenMux 的 Token Economics Arena 已经运行了数日。
实时榜单上的数据开始呈现出一些耐人寻味的格局变化。
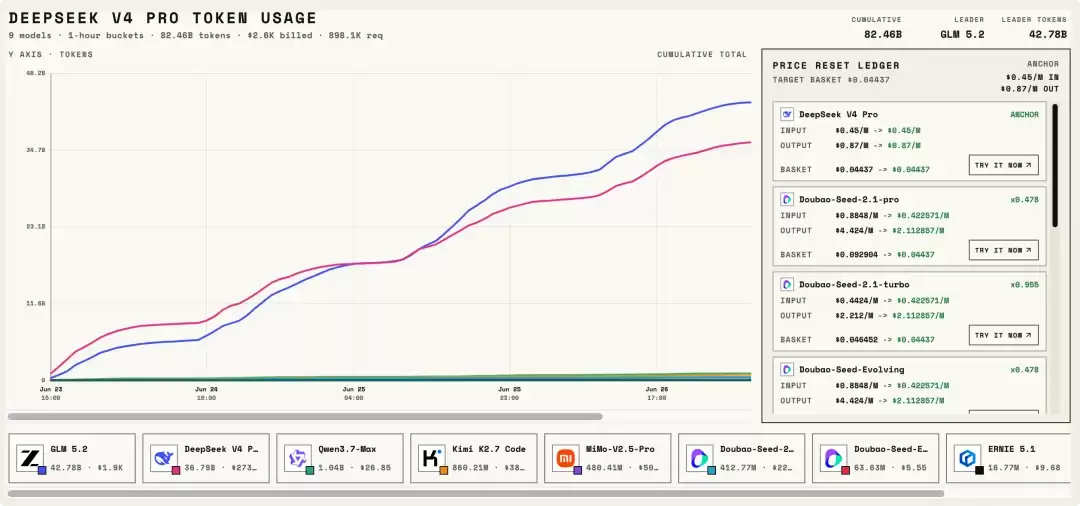
首先,DeepSeek V4 Pro 依然保持着相当可观的调用量。即便其他模型已经降至同等价位,用户的使用惯性和对既有工具的信任感仍然在持续发挥作用。这说明,一旦某个模型成为开发者工作流中的默认选项,替换成本远比想象中更高。
但更值得关注的是,GLM 5.2 的用量在实验启动后出现了明显的攀升,甚至一度反超 DeepSeek V4 Pro 位居榜首。这暗示了一个重要信号:此前限制这些模型市场份额增长的因素中,价格确实占据了相当大的比重。当价格壁垒被打破,模型的真实能力开始被更多开发者看见并认可。
Doubao Seed 2.1 Pro 作为一款刚发布不久的新模型,其起步增长曲线也比较陡峭。字节在模型能力上的持续投入,正在真实市场中逐步收获正向反馈。
ZenMux 将这些数据完全对外开放,任何人都可以前往 arena.zenmux.ai/token-economics 查看实时排名。你可以看到每个模型在具体时间段内的调用量变化,也可以从 Token 和 Cost 两个维度切换视角进行观察分析。

回顾过去两年,中国大模型市场的竞争逻辑已经历了多个阶段。最初是参数竞赛,谁的模型规模更大谁就更强。随后转入 Benchmark 竞赛,谁的测评得分更高谁就领先。再后来演变为价格战,DeepSeek 率先将价格大幅拉低之后,众多厂商被迫跟进降价大潮。
但降价之后,真正的竞争点在哪里?
如果所有模型都跌入同一个价格区间,下一步决定胜负的关键究竟是什么?
ZenMux 的这次实验给出了一个可能的方向性答案:真实应用场景中的综合使用体验。
这种综合体验所涵盖的维度非常丰富。模型在 Coding 任务中的准确率与执行效率,在 Agent 循环流程中的上下文保持能力,在长文本处理过程中的稳定性与连贯性,在多语种场景下的翻译质量与语义理解,在内容生产任务中的创造力与格式控制力。
这些能力,没有任何单一的 Benchmark 能够全面覆盖。
因此,ZenMux 设计了五个场景板块供用户自由探索和讨论(即将开放)。Coding、Agent、Long Context、多语种、内容生产,每个板块都是一个独立的竞技场,让开发者可以针对自己最关心的维度进行真实对比。
你还可以通过小票的形式,打印并保存自己的投票数据(该功能即将上线)。
这项实验将持续到 7 月底,最终将评选出两个重量级奖项。
「最受欢迎奖」将授予 Token 消耗总量最大的模型,而「最佳表现奖」则颁获得开发者投票数最高的模型。
这些实时流动的 Token 数据,最终将告诉我们:当中国 AI 模型的价格战打到尽头,真正能够长久留住开发者的,究竟是什么核心价值。
如果你也对这个答案感到好奇,现在就可以亲自参与进来:选择一款你比较看好的模型,用同样的任务跑一遍,看看最终结果是否符合你的预期。你的每一次调用都会被如实记录在 Arena 榜单上,成为这场大规模市场实验的重要组成部分。

没有哪个 Benchmark 能替你决定该用哪个模型。
你的手感,你的体验,你打出去的每一个 Token,才是最真实、最可靠的答案。