6月28日,一条推文在开发者圈子里引发了热烈讨论:
"Google casually giving developers 1M tokens per minute for free"
「Google 随随便便就给开发者免费送了每分钟100万tokens。」
无需绑定信用卡,也无需订阅付费计划,只需打开Google AI Studio,短短几秒钟就能生成一个API Key,即刻上手使用。
这条帖子来自X平台用户@k2sbhai,并附上了一张AI Studio的Rate Limits(速率限制)截图。截至目前,该帖子已获得12.3万次浏览量、1440个点赞和2564次收藏。评论区里,有人疯狂标记好友准备去“薅羊毛”,也有人直接甩出两个字:Fake news。
那么,真相究竟是什么?


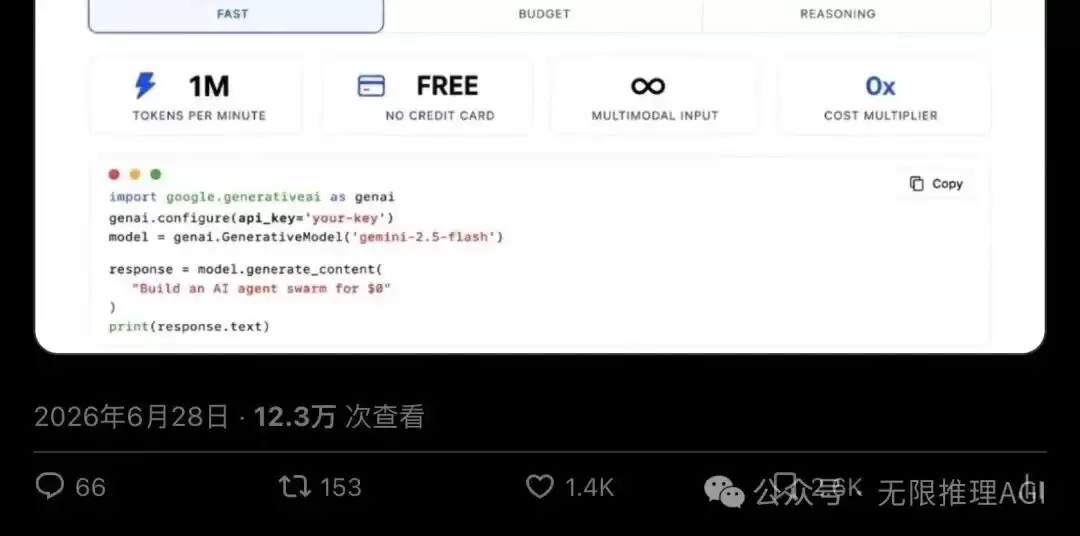
▲ @k2sbhai 的原帖,展示了AI Studio的速率限制截图,浏览量已超12.3万
帖子究竟说了什么?
@k2sbhai 的帖子将核心卖点拆解为三个部分:
0美元你能得到什么——
- Gemini 2.5 Flash 和 Pro 均可使用,每分钟享有100万tokens
- 原生支持文本、图像、音频、视频等多种模态输入
- 几秒钟即可生成API Key,开箱即用
为什么这很重要——
- 不再需要与其它平台严苛的免费额度限制周旋
- 无需为简单实验预先充值
- 直接使用官方服务,绕过第三方中间商
Pro tip(专业建议)——
利用 Flash 模型处理高吞吐量的批量任务,用 Pro 模型处理需要深度推理的复杂问题。通过两个模型的配合使用,可以最大化地利用免费额度。
听起来确实极具诱惑。然而,评论区的画风却完全是另一番景象。
质疑声浪:「我的 Dashboard 为什么和你的不一样?」
帖子发布几小时后,越来越多的反驳声音开始涌现。
用户 @magithar 直接贴出了自己的速率限制页面截图——上面的数字与帖子中的内容完全无法对应。
用户 @voy_aj 留言道:
"only include 20 request per day"
「每天仅有20次请求。」
@1petitbiscuit 的表述则更加具体:
TPM 250K + 20 RPD
这意味着每分钟25万tokens,每天最多20次请求。这与帖子宣称的“100万tokens随意使用”相差甚远。
还有巴西用户反映,在当地根本无法获取到任何额度。
甚至连平台自身的AI助手Grok也在同一帖子下回复,给出了一个相当中肯的评价:
"Solid for testing, not casual unlimited"
“用于测试足够了,但别指望能随意无限使用。”
Grok进一步指出:部分Flash模型确实能显示接近1M TPM(每分钟tokens数),但2.5 Flash通常的限额在250K TPM / 10 RPM左右。Pro模型的限制则更严格,每天可能仅有几十次请求。
所以,截图本身并非伪造。但显示的配额数值,会因账户类型、模型版本、所在地区,甚至项目不同而天差地别。
真实的免费配额到底是多少?
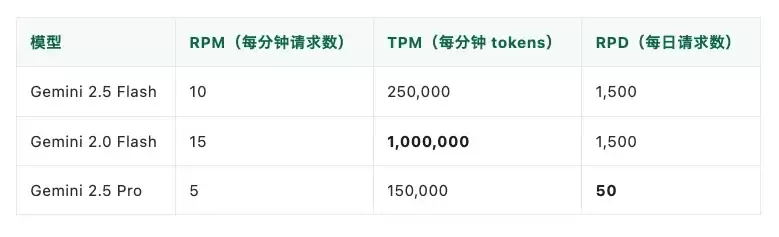
开发者社区里有人整理了各模型免费层(Free Tier)的实测数据汇总表。以下数据源自PE Collective 2026年的统计(具体请以个人AI Studio页面显示为准):
看出关键信息了吗?
能够达到1M TPM(每分钟tokens)的,是Gemini 2.0 Flash——这是上一代的轻量级模型。而2.5 Flash的TPM仅为25万,2.5 Pro更是只有15万。
真正限制日常使用的核心指标,藏在表格的最后一列:RPD,即每日请求数(Requests Per Day)。
例如,2.5 Pro 每天只能调用50次。即便每次请求仅消耗1000个token,一旦50次额度用完,就必须等到太平洋时间午夜重置。这样一来,你再高的TPM(每分钟tokens)也仅仅是纸面上的漂亮数字。
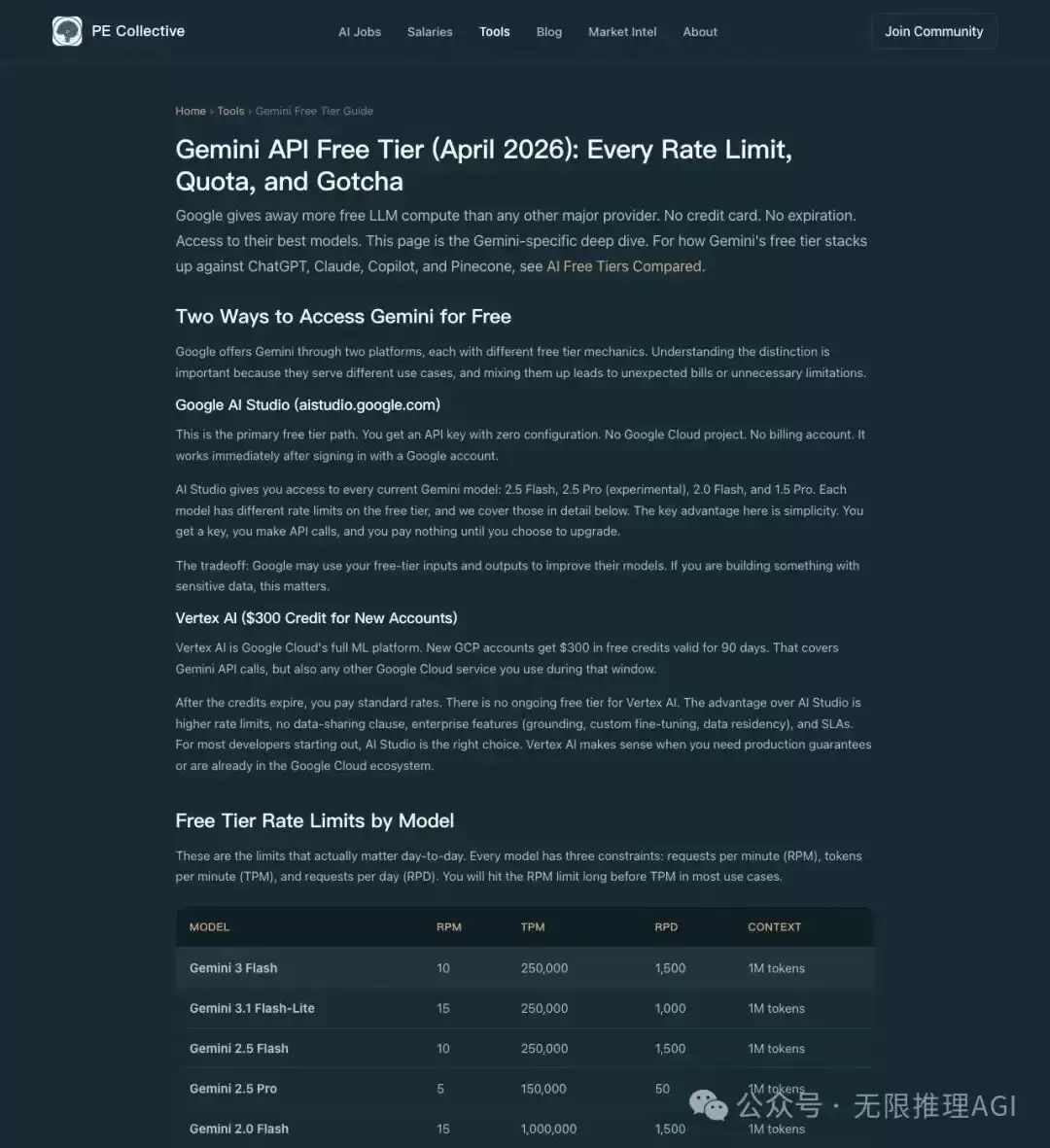
▲ PE Collective 整理的 Gemini 免费层限额表,请注意 RPD(每日请求数)列的显著差异
Google 官方如何解释?
查阅Google的官方文档,关于速率限制(Rate Limits)的页面写得非常明确:
配额由三个关键维度共同控制——
- RPM(Requests Per Minute):每分钟的请求次数
- TPM(Tokens Per Minute):每分钟消耗的 token 总量
- RPD(Requests Per Day):每日请求的硬性上限
这三个维度,任意一个达到上限,API都会返回429错误(请求过多)。而且,限额是按照项目(Project)而非API Key来计算的,RPD(每日请求数)会在太平洋时间午夜自动重置。
文档中不断强调的核心信息是:配额会因为模型、账户状态、使用历史等因素动态变化,必须亲自登录AI Studio查看个人的实时配额。
这就完美解释了为什么十个人会看到十个不同的数字。Google从未在文档里承诺过一个固定的免费数值——它只是提供了一个控制面板,让你自己去查看。
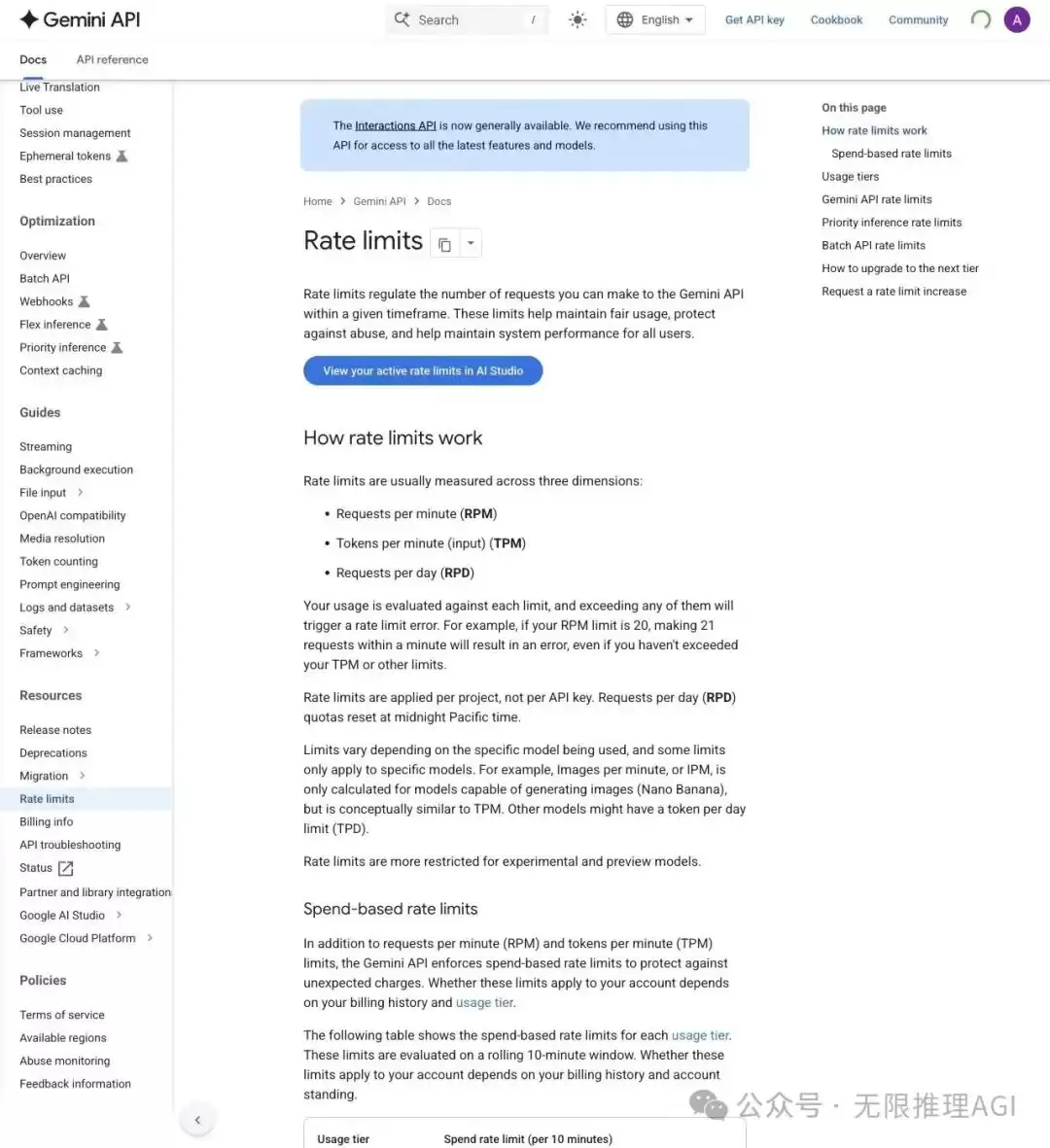
▲ Google Gemini API 官方文档,清晰阐述了三大配额维度
免费背后的代价:你的数据
翻到定价页面,在免费层(Free tier)的描述下方,有一行很容易被忽略的注释:
Content used to improve our products*
这行字意味着,免费用户的输入和输出内容,可能会被Google用于改进其模型。
而在付费层(Paid tier)的同一位置,标注的则是:Content not used to improve our products*(内容不会被用于改进产品)。
这正是Google免费策略中的隐藏条款。当你用Flash运行每一次请求、输入每一个prompt、生成每一段内容时,这些数据都可能成为Google训练数据的一部分。尽管官方声称可以勾选退出(opt out),但对于处理敏感数据的开发者来说,这是一个不容忽视的权衡。
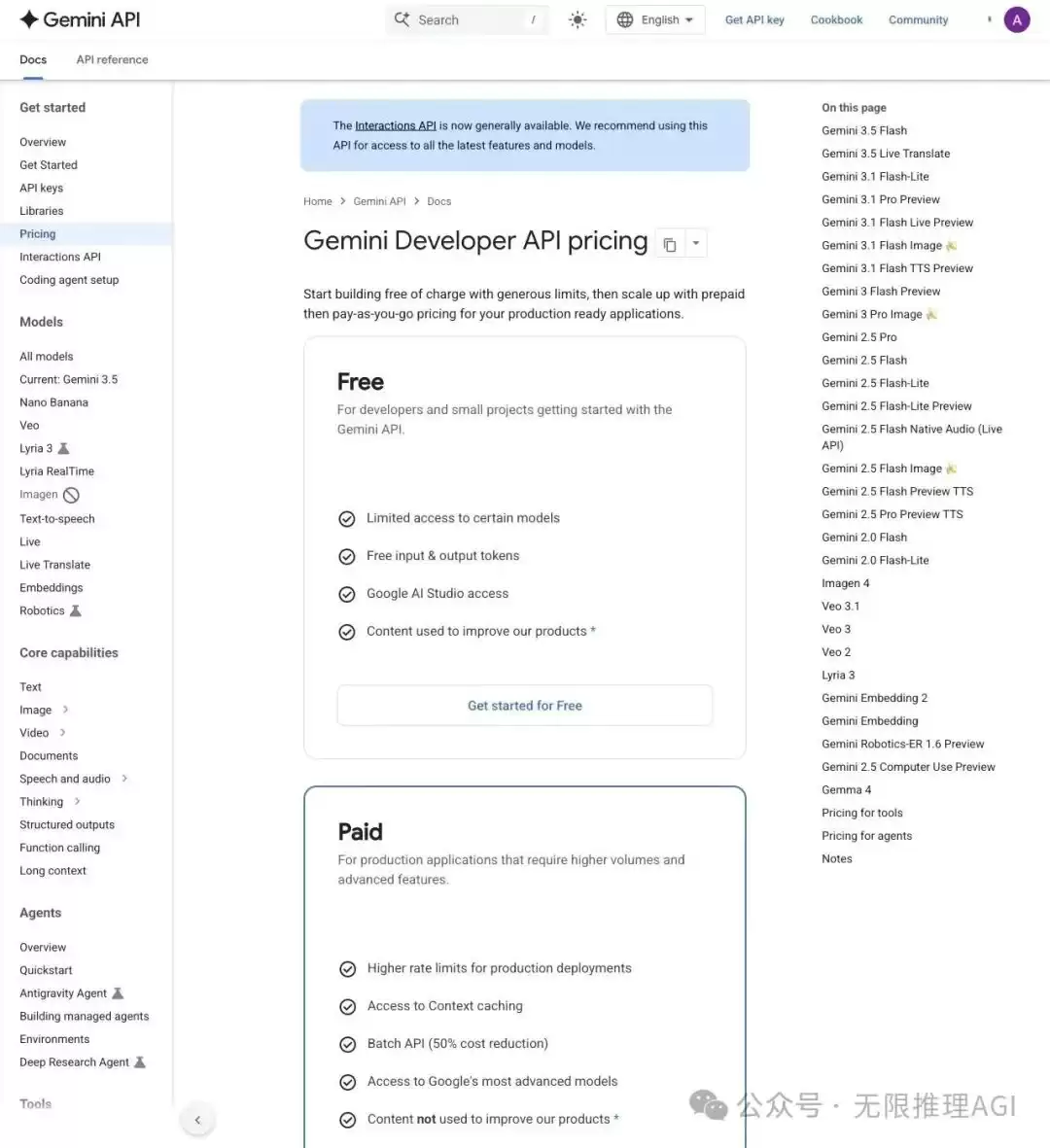
▲ Gemini API 定价页面,免费层明确标注数据可能被用于产品改进
Google 究竟在下什么棋?
向开发者慷慨发放高额API配额,Google的目的可以用三个字概括:抢生态。
先看看竞争对手的情况:
- OpenAI:免费层的限制非常严格,大多数使用场景都需要绑定信用卡。
- Anthropic:至今仍未面向个人开发者提供免费的API服务。
- Groq / Together:虽然推理速度快,但免费配额较为有限。
Google的打法与二十年前推广Gmail时如出一辙——用远超竞争对手的免费容量吸引用户,等用户养成使用习惯后,再自然地引导他们升级到付费层。
具体来说,这套策略分三步走:
第一步,零门槛获客。无需信用卡,无需设置结算账户,只要有Google账号就能登录。一个独立开发者在周末有了灵感,三分钟内就能获取key并开始写代码。
第二步,养成依赖。为Flash模型提供充足的TPM(每分钟tokens)配额,让开发者的原型代码、agent框架、RAG管道全部运行在Gemini之上。当代码写完了,prompt调优好了,迁移到其它模型意味着大量的返工成本。
第三步,付费转化。当开发者的项目从原型走向生产环境,每天50次请求(RPD)显然不够用了。这时,付费层(Paid tier)就在旁边静静等候——提供更高的限额、上下文缓存(context caching)、Batch API五折优惠,还有一个关键卖点:你的数据不会被用于模型训练。
这套先占领再扩张(land and expand)的玩法,Google已经在Cloud、Workspace、Maps API等多个产品上反复验证过。
开发者现在该如何操作?
抛开帖子中夸大其词的成分,Google AI Studio提供的免费层(Free tier)确实值得申请。操作步骤非常简单:
- 打开官网aistudio.google.com
- 使用Google账号登录,并勾选同意相关条款
- 在左侧导航栏找到API Keys入口,生成你的专属key
- 选择合适的模型,开始调用API
▲ Google AI Studio 首次进入时的界面,继续操作前需同意服务条款
几条实用的操作建议:
高频批量任务选用Flash。Flash系列的TPM和RPD(每日请求数)都远高于Pro,非常适合处理数据清洗、批量生成内容、简单的agent调度等任务。2.0 Flash提供的1M TPM + 1500 RPD组合,对于个人项目来说已经相当阔绰。
复杂推理任务选用Pro,但需精打细算。2.5 Pro每天仅有50次请求配额,建议将其留给真正需要长链推理或复杂分析的核心场景。一般的对话和内容生成任务,交给Flash模型处理就足够了。
警惕长上下文带来的配额消耗。Gemini支持高达1M token的上下文窗口,一次长上下文的请求就可能消耗掉数十万token的配额。如果你正在构建RAG(检索增强生成)应用或进行文档分析,控制单次输入的长度至关重要。
定期监控你的实际配额。请务必登录AI Studio的速率限制页面查看个人的实时限额,不要轻信任何第三方的截图。因为配额是动态调整的,今天看到的数字明天可能就会发生变化。
尽早准备备选方案(Plan B)。Google在页面底部也提示了——免费层的内容随时可能发生变更。当你的项目开始严重依赖免费API时,提前准备好付费迁移方案或备用的模型服务。
免费午餐确实存在,但并非想象中丰盛
让我们回到那条被12万人围观的推文。
@k2sbhai 说错了吗?也不完全错。AI Studio确实可以免费申请API Key,部分模型也的确拥有很高的TPM(每分钟tokens)额度,整个流程确实无需花费一分钱。
然而,“Flash和Pro都拥有1M TPM”的说法经不起推敲。真实情况是:2.0 Flash可以达到1M TPM,2.5 Flash通常为25万,而2.5 Pro只有15万。更重要的是,RPD(每日请求数)这一硬性限制,使得Pro模型在一天之内就会触及上限。
Google正在将AI API的实验门槛降至历史最低点。对于个人开发者而言,跑一个agent原型、做一次视频理解实验、搭建一条RAG管道,现在真的可以零成本启动。这在一年前还几乎难以想象。
只是别忘了——Google送出的每一个免费token,都在为它的生态布局买单。当免费配额未来某一天收紧时,你在Gemini上写下的每一行prompt、每一个function call、每一套agent架构,都将成为它巩固市场的护城河。
现在就去领取你的Key。趁它还是免费的。