AI推理的“慢”与“堵”,终于有了新解法
先挑个重点说:大模型在推理阶段出现的“卡顿式”延迟,一直是困扰业界的顽固痛点。尤其在高并发请求下,模型每生成一个词元,都必须重新激活全部计算资源从头执行前向传播——这好比你说出一个字就要重启整个大脑,效率之低可想而知。
6月28日,北京大学与深度求索(DeepSeek)联合发布了一款名为DSpark的推理加速框架,目前已正式开源。它的核心目标非常明确:解决长文本生成过程中,“重复执行前向计算”所导致的算力浪费与响应延迟问题。
当前主流的加速方案是推测解码,但其缺陷同样突出:轻量模型串行生成候选序列,时间成本偏高;并行架构虽能提升吞吐量,但一旦遇到长文本场景,候选序列的接受率就会明显下降。简而言之,大量算力被浪费在无效候选上。
双轨协同:一次搞定质量与速度的矛盾
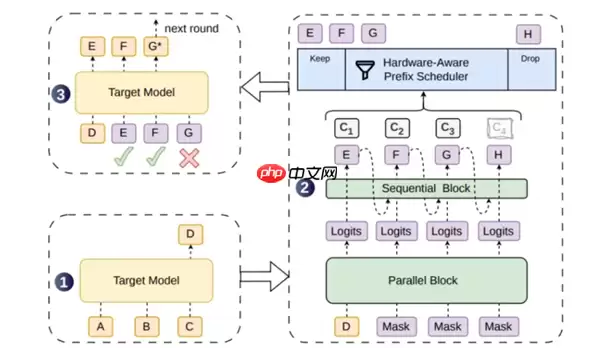
那么DSpark是如何实现突破的呢?它选择了一条“双轨协同”的优化路线。
在候选生成阶段,该框架采用了一种半自回归结构。通俗来说:由并行主干网络一次性提取高质量语义特征,再叠加一个轻量级的逻辑增强模块进行局部精修。结果令人惊喜——仅用两层Transformer,就能超越五层并行模型的生成质量。这在推理速度与输出精度之间,找到了一个相当理想的平衡点。
而在验证调度环节,系统引入了置信度驱动的动态验证机制。具体而言,一个硬件感知型前缀调度器会实时监测GPU的负载状态,优先验证那些高置信度的候选片段。如此一来,冗余计算量被大幅压缩,整体效率自然显著提升。
实测表现:长文本不再“越跑越慢”
该框架已在通义千问3、Gemma4等主流模型上完成了多维度测试,覆盖代码生成、数学推理、日常对话等典型任务。与Eagle3和DFlash这两个行业标杆基线方案相比,DSpark在单轮有效生成长度指标上展现出明显优势。尤其针对超长文本生成,它有效抑制了候选有效率随长度增加而快速衰减的现象——这在以往几乎无法避免。
工程落地:不是纸上谈兵
DSpark的可贵之处在于它并非仅停留在实验室。研发团队实施了大量底层系统级优化:序列打包技术压缩显存占用,异步调度引擎消除GPU流水线阻塞,并且全面适配主流CUDA硬件生态。
目前,DSpark已率先集成到DeepSeek-V4-Flash与DeepSeek-V4-Pro预览版服务引擎中。实测数据表明,无论以何种响应延迟阈值衡量,系统整体的吞吐能力都实现了阶跃式提升——这并非百分之几的改善,而是质变级的跨越。
开源才是硬道理
深度求索已在GitHub上的DeepSpec项目中同步开源了DSpark、DFlash及Eagle3的完整训练代码、模型权重与评估工具链。这意味着,高性能推理服务的部署门槛正在被实质性降低。对于希望实现大模型规模化、低成本落地的团队而言,这无疑是一套可直接复用的技术底座。