AI模型的参数规模是否越大越好?这一话题在业内长期存在争议。近日,新浪开源的新模型VibeThinker-3B,给出了一个颇具启发性的答案。
首先来看几个关键结论:该模型仅拥有30亿参数——在当前大模型领域,这属于轻量级配置。然而,在数学推理、编程等高难度基准测试中,它却能对标参数规模高出数百倍的“巨无霸”模型,甚至在一些竞赛级任务上,超越多款主流商用模型。
这并非偶然。VibeThinker-3B的卓越表现,源于一套系统化的“后训练”策略支撑。
性能表现与后训练策略
您可以将其训练过程视为一场精心策划的“教育工程”:基础模型选用阿里的Qwen2.5-Coder-3B,随后经过监督微调、强化学习、自蒸馏、指令微调等多阶段的精细化训练。目标十分明确——将大型模型复杂的逻辑推理能力,高效地“浓缩”到仅有30亿参数的紧凑架构中。
实际效果如何?数据说明一切:在LeetCode编程竞赛题集中,128道题目它准确完成了123道。这一成绩已经超越了GPT-5.2等业界公认的标杆模型。坦诚地说,若放在一年前,几乎无人相信一个30亿参数的模型能取得如此成就。
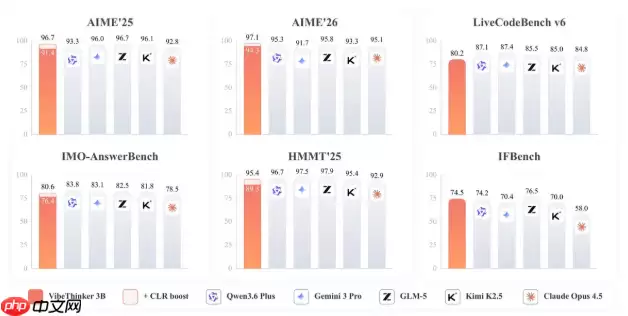
参数压缩-覆盖假说
此次发布中最值得关注的,是团队提出的“参数压缩-覆盖假说”。研究揭示了一个常被忽视的事实:AI模型的能力并非均匀分布。
具体而言,对于逻辑推理、代码生成等结构清晰、规则性强的任务,完全可以通过定向训练实现高密度的能力压缩。这就像一位优秀的心算专家——无需庞大的知识库,也能快速解决复杂数学问题。相反,对于需要广泛通用知识表征的场景,如常识问答、开放域对话,则依然需要更大的参数容量来支撑。
这一发现背后蕴含的深意值得玩味:在许多专注于推理的垂直场景中,我们或许不必动辄调用资源消耗巨大的超大规模模型。小模型配合深度定制化训练,完全可能成为一条更为务实的技术路径。
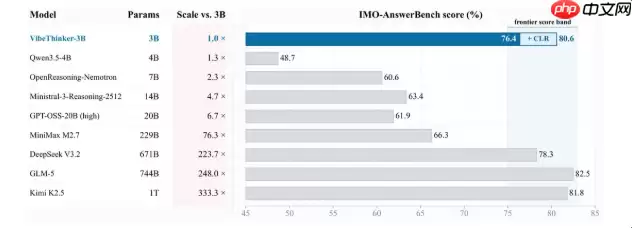
目前,VibeThinker-3B已在Hugging Face和GitHub平台全面开源。对于开发者而言,这意味着一个兼具轻量化与高性能的全新选择。更值得关注的是,它验证了一条AI优化的新路径:在垂直任务领域,通过深度定制的后训练流程,完全有可能以极低的计算开销,达到媲美“行业巨头”的推理水准。这或许正是这项开源工作最值得深思之处。