在AI绘画的入门旅程中,许多新手常常问:到底该如何开始?对于那些从未接触过AI绘图的朋友、电脑配置不足无法运行本地Stable Diffusion的用户,或者只想专注于创意表达而不愿钻研技术细节的内容创作者来说,选择合适的工具是第一步。这里强烈推荐一个非常适合新手的在线AI绘画平台——LiblibAI。只需注册即可直接使用,而且它的在线生图界面与SD Web UI几乎完全一致,对于后续学习和掌握SD相关技能非常友好,是AI绘画入门教程的理想选择。
注册后每天可免费获得300积分,生成一张图片通常消耗2-8积分,完全足够日常练习。下面直接进入正题,手把手带大家从零开始生成第一张AI图片,轻松掌握Stable Diffusion入门技巧。
一. 快速入门
在浏览器中打开LiblibAI网站,首页点击“在线生图”按钮,进入绘图主界面,开启你的AI绘画之旅。
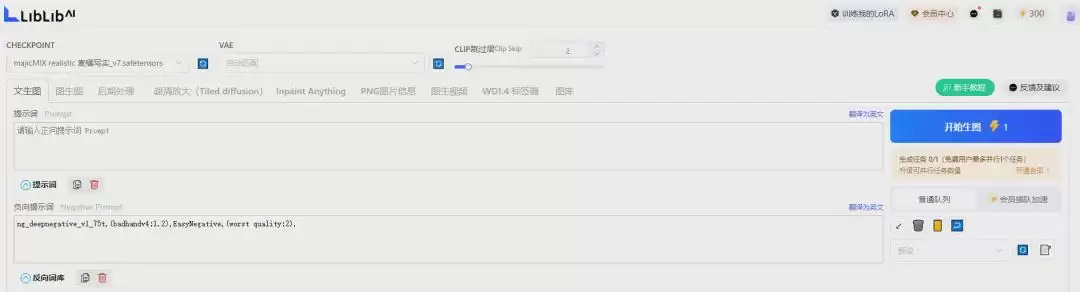
先按照下面的参数设置生成一张图,感受一下效果。为了清晰说明,我们分成三个部分来讲解。
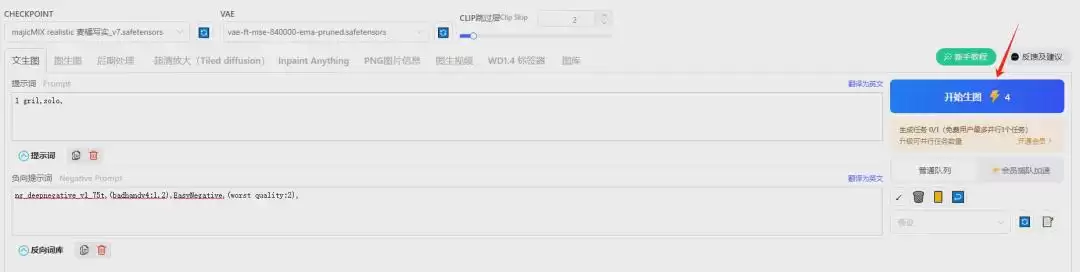
(1)大模型和提示词
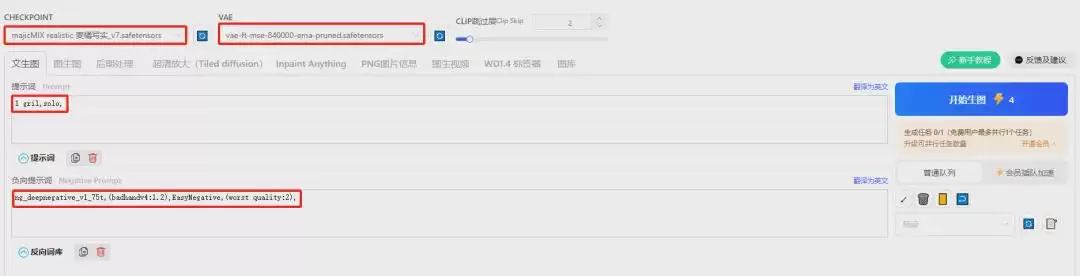
- CHECKPOINT(大模型):
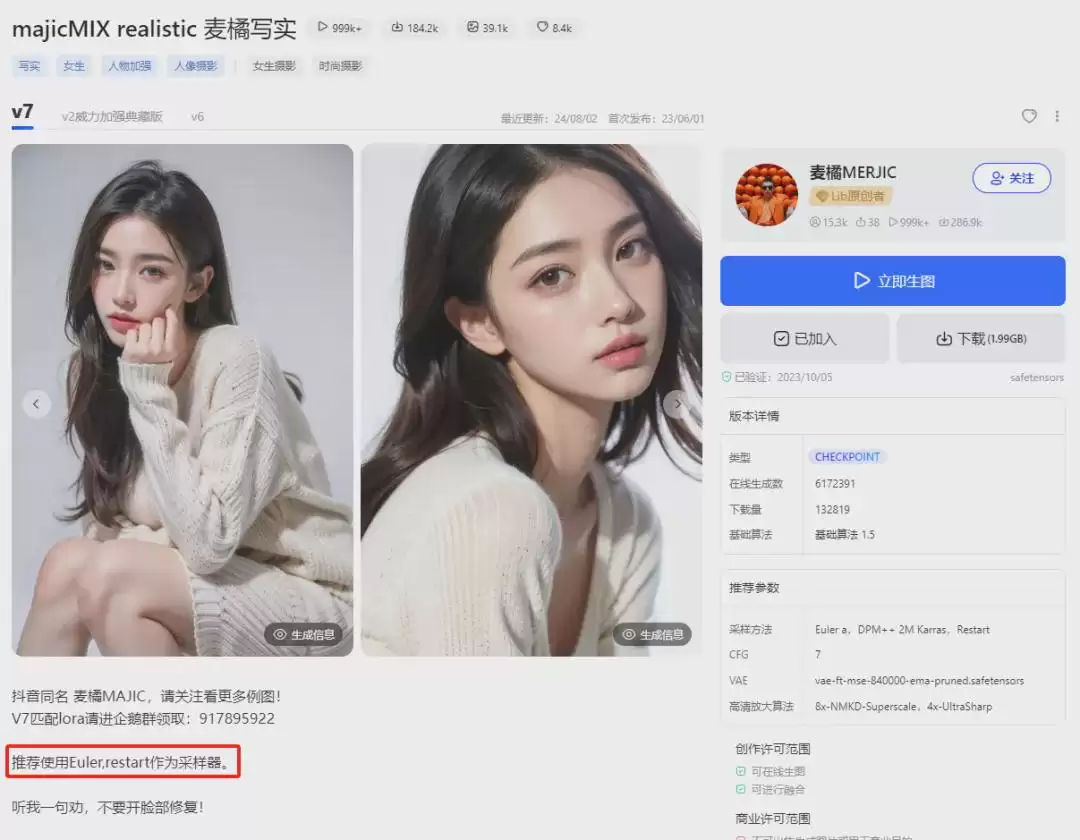
majicMIX realistic 麦橘写实_v7.safetensors - VAE(VAE模型):
vae-ft-mse-840000-ema-pruned.safetensors - CLIP跳过层:2(保持默认)
- 正向提示词:
1 gril,solo, - 负向提示词:
ng_deepnegative_v1_75t,(badhandv4:1.2),EasyNegative,(worst quality:2),
(2)参数设置
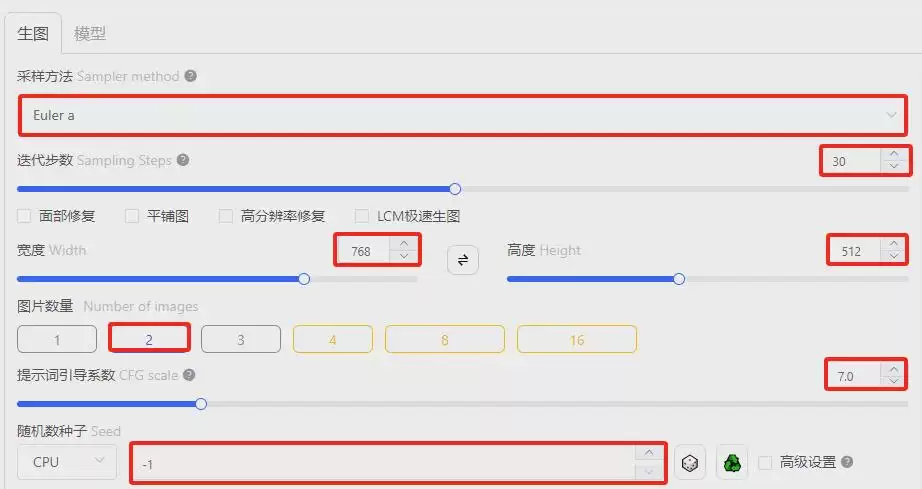
- 采样方法:
Euler a - 迭代步数:30
- 宽度:768
- 高度:512
- 图片数量:2
- 提示词引导系数:7
- 随机数种子:-1
(3)ADetailer插件
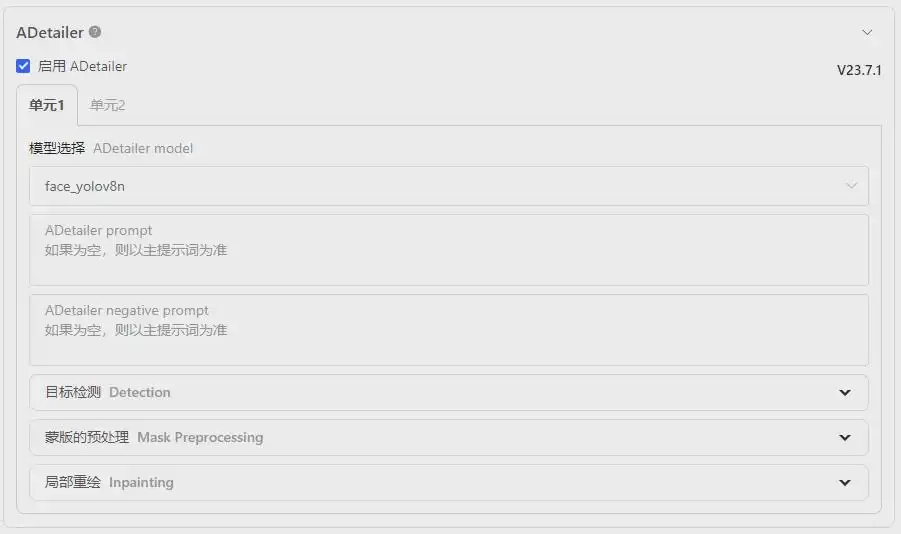
- 启用ADetailer:勾选
- 模型选择:
face_yolov8n
参数全部设置完成后,点击“开始作图”按钮,稍等片刻即可看到生成的图片。因为我们设置了图片数量为2,所以会同时生成两张图。
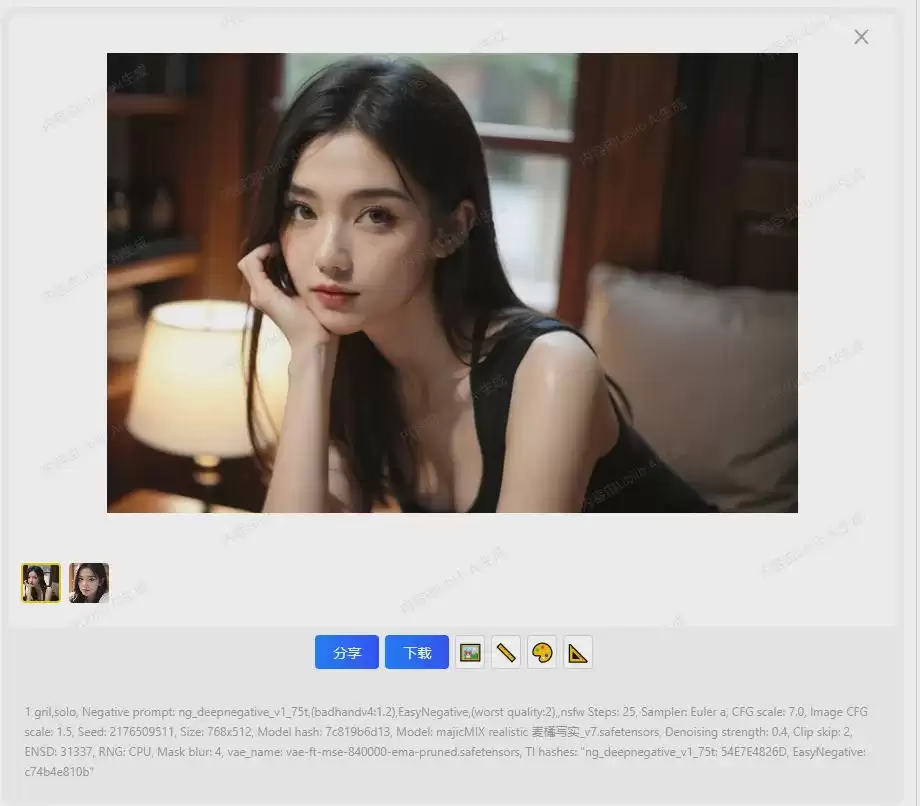
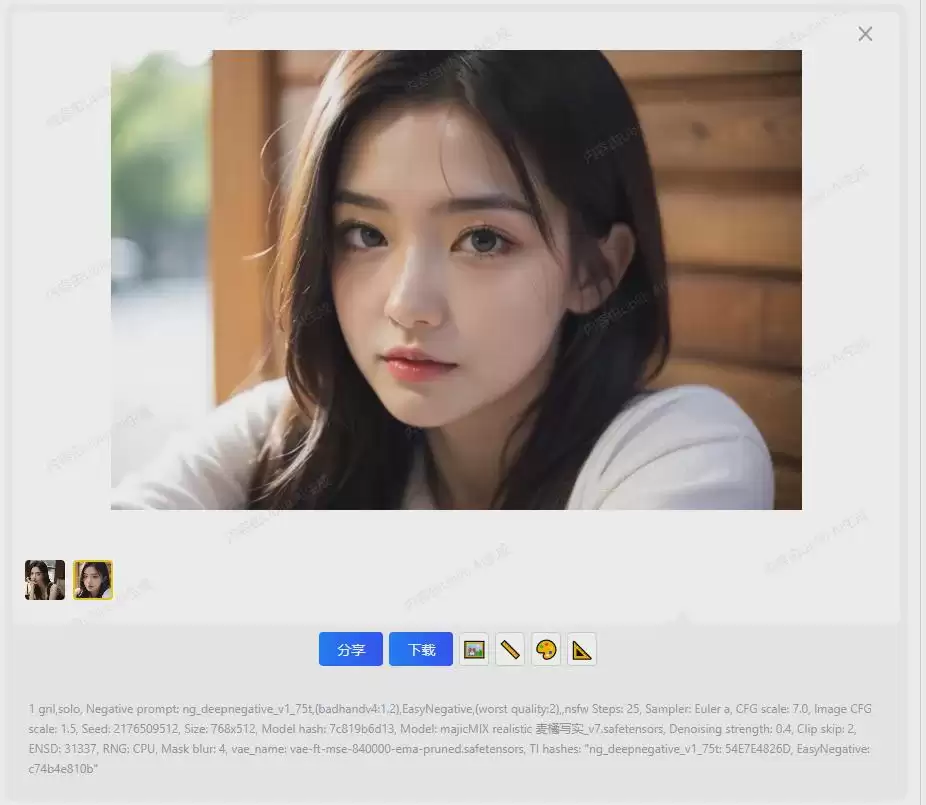
第一张AI图片就这样成功生成了。是不是比想象中更简单?这就是LiblibAI在线生图的魅力所在。
二. 各种参数的讲解
下面逐一说明上面涉及的关键参数,帮助大家理解每个选项的具体作用,为后续深入学习Stable Diffusion入门教程打下坚实基础。
1. 大模型(Checkpoint)
大模型是SD绘图的基础,也被称为底模。它决定了生成图片的主要风格——二次元、真人、国风等不同方向都有对应的专用模型。目前主流的大模型分为基于SD1.5和SDXL两个生态。
对于初学者,重点掌握以下两点:
如何添加大模型
在LiblibAI首页搜索框中输入关键词(比如“麦橘”),即可看到相关模型列表。点击模型进入详情页,点击“加入模型库”,该大模型就会出现在绘图界面的CHECKPOINT下拉列表中。如果点击后没有反应,可以点击旁边的刷新按钮,模型一般就能成功加载。

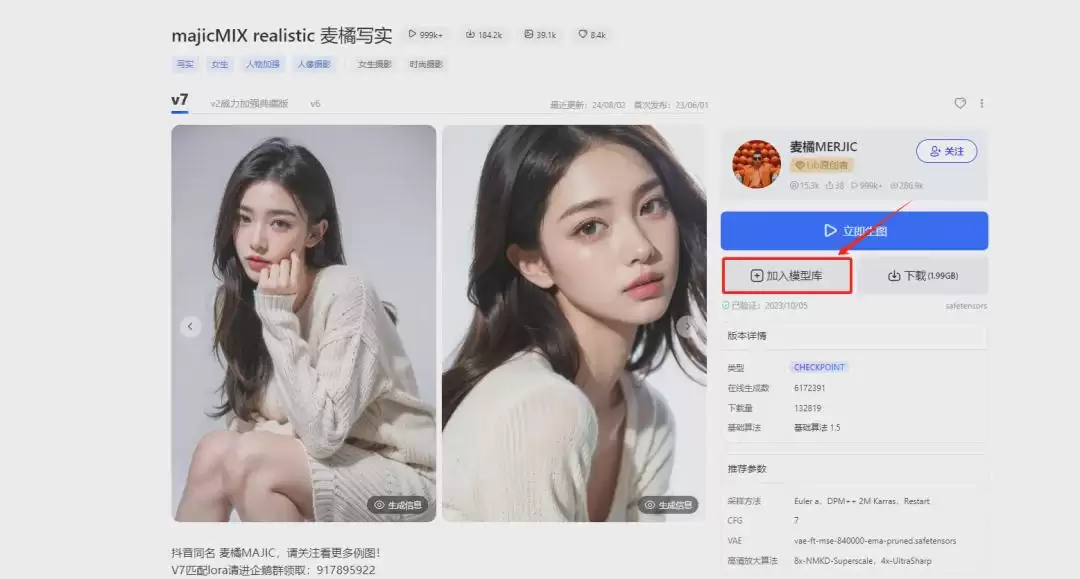

常用的大模型推荐
- SD1.5 系列:通用模型DreamShaper;写实类DeliberateV2/ReVAnimated_v122;真人写实类majicMIX realistic V7、realisticVisionV60、Chilloutmix;人像优化类AWPortaint和kimchiMix。
- SDXL 系列:通用模型DreamShaper XL、juggernautXL_v9 + RDPhoto 2、RealVisXL V4.0 Lightning、AlbedoBase XL V2.1、Dream Tech XL(筑梦工业);写实类LEOSAM HelloWorld 新世界、万享XL V8.2、wuhaXL_realisticMix。
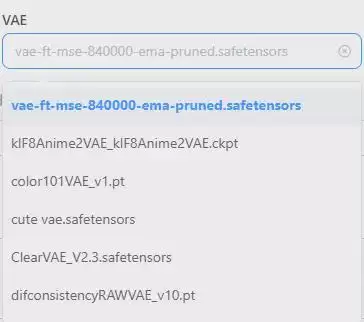
2. VAE模型
VAE可以理解为一种颜色滤镜,用于调节和美化生成图片的色彩表现。最常用的是vae-ft-mse-840000-ema-pruned,一般选择这个就足够了。需要注意的是,LiblibAI对VAE的使用有限制——当大模型是SDXL时,VAE选项会不可用,这对初学者来说反而是好事,避免了选错的风险。
3. 提示词
提示词分为正向和反向两种:正向提示词描述你希望图片包含的元素,反向提示词则列出你不希望出现的元素。提示词需要用英文描述,可以是单词、短语或短句。如果不会编写也没有关系,LiblibAI大模型的详情页里有大量用户分享的图片,下面通常附带提示词,直接模仿学习即可。
4. 采样方法与迭代步数
这两个参数通常一起设置。采样方法决定了图像去噪的过程和风格,常用的有Euler a、DPM++2M Karras、DPM++SDE Karras、DPM++2M SDE Karras等。在LiblibAI的采样方法旁边有一个提示图标,点击后会显示推荐信息。另外,大模型的详情页通常也会注明该模型推荐的采样方法,供你参考。
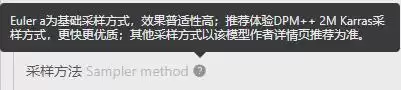
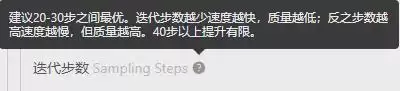
迭代步数指的是生成图像所需的步数,每一次采样都在前一步的基础上进行优化和调整。通常设置在20-40之间即可获得较好的效果。
5. 图片宽高
不同模型有各自推荐的最佳宽高比:
- SD1.5 模型最佳:512×512。常用比例:1:1(512×512、768×768)、3:2(768×512)、2:3(512×768)、4:3(768×576)、3:4(576×768)、16:9(912×512)、9:16(512×912)。
- SDXL 模型最佳:1024×1024。常用比例:1:1(1024×1024、768×768)、3:2(1152×768)、2:3(768×1152)、4:3(1152×864)、3:4(864×1152)、16:9(1360×768)、9:16(768×1360)。
注意:宽度和高度最好能被8整除。如果选错比例,很容易生成形态怪异的图片。
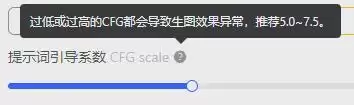
6. 提示词引导系数(CFG Scale)
该参数控制生成图片对提示词的遵循程度,数值越大,图片越贴近提示词的描述。默认值为7,一般建议设置在5-10之间,不建议调得过大,以免破坏画面自然度。
7. 随机数种子(Seed)
种子相当于图片的“DNA”,决定了画面的具体内容和构图。默认为-1表示随机生成,每次结果都会不同。如果你希望同样的参数组合能产生相似的图片,可以将种子固定为一个具体数字。很多初学者会困惑:为什么同样的参数每次生成的图不一样?答案就在这颗种子上。
掌握以上这些基础知识,再动手生成几张图,基本就算成功入门了。接下来该做什么?尝试更换不同的模型和提示词,不断练习,你就能逐渐找到AI绘画的感觉,开启属于自己的创意表达之路。