LiveWorld是什么
先聊一个很有意思的现象。在日常观看视频或使用模拟器的时候,我们经常会遇到一个令人困扰的场景:一个物体——可能是人,也可能是一只狗——刚刚走出画面,再次切回镜头时,它就像被按下了暂停键一样,僵在原地。这在现实世界中显然不可能发生,那只狗很有可能早已跑到别处去了。因此,许多现有的视频模型都陷入了这个“视野外冻结”的困境。
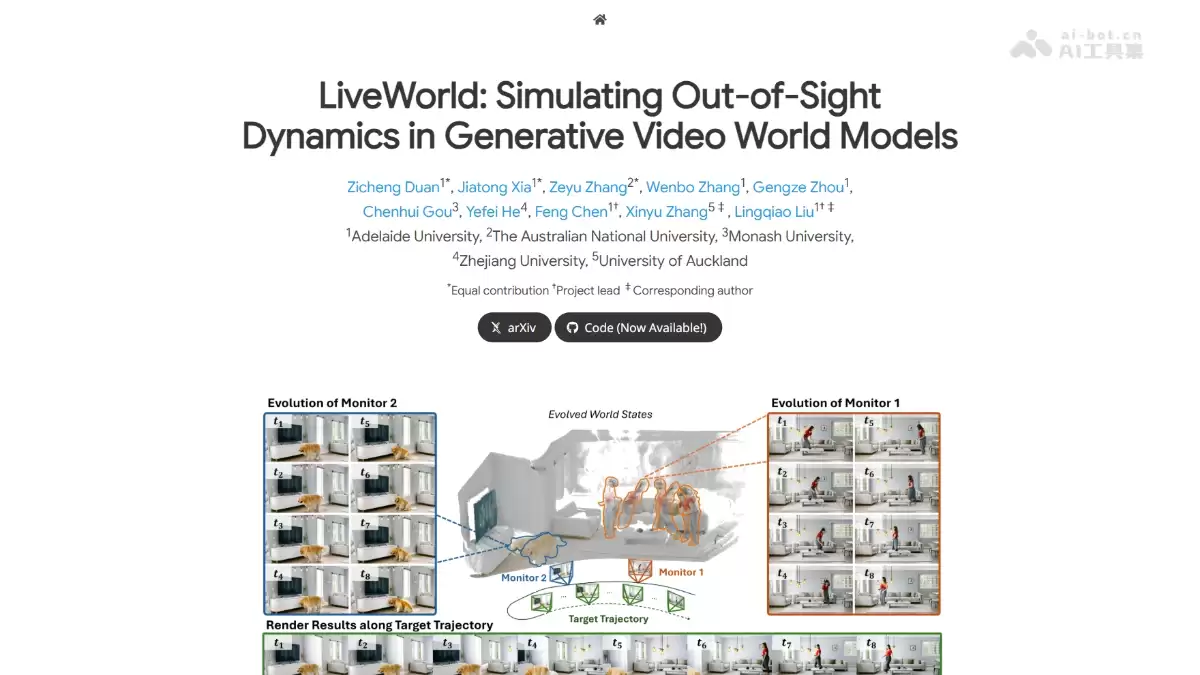
LiveWorld 正是为了解决这一难题而诞生的。它是由阿德莱德大学、澳大利亚国立大学等机构联合推出的一款生成式视频世界模型。其核心突破在于不再固守“只演化可视区域”的规则,而是通过一种巧妙的方法将世界的演化过程与观察渲染过程解耦。这样一来,即使物体暂时脱离了相机的视线,其状态也能在后台持续更新,从而实现真正意义上的4D世界模拟。
LiveWorld的主要功能
那么,LiveWorld 究竟能实现哪些功能?下面简要列出几个关键能力,帮助你理解它为何值得关注。
- 动态实体检测:利用 Qwen3-VL 和 SAM3 自动识别视频中所有动态目标——人物、动物、车辆,无一遗漏。
- 虚拟监视器注册:每发现一个动态实体,就为其分配一个固定视角的“监视器”,专门追踪该实体的状态变化。
- 视野外动态演化:当相机移开、实体消失后,监视器在后台继续推进动作——比如那只狗如何吃完食物然后走开,而不是停滞在原地。
- 静态环境积累:通过 Stream3R SLAM 框架,将静态背景逐帧融合为一个全局3D点云,为整个场景奠定空间基础。
- 状态感知渲染:将演化后的动态4D点云与静态3D点云投影到目标相机轨迹上,生成连贯的观察帧。
- 外观一致性保持:借助 Appearance LoRA 这个“记忆体”检索历史参考帧,确保在长序列中每个实体的身份和纹理不发生漂移。
LiveWorld的技术原理
谈到技术细节,LiveWorld 的设计理念虽然简洁,但极具巧思。它不仅关注当前画面,还建立了一套“后台推动”的机制。
世界状态解耦
它将整个世界简化为两个部分:静态3D背景 + 动态4D实体。这是一种结构化的近似表示,而非直接预测每一帧的2D图像。
演化-渲染分离
运行逻辑分为两步:首先,世界状态通过“演化算子”更新全局动态信息;然后,“渲染算子”结合相机位姿,将当前视角下的画面呈现出来。这两个过程彼此解耦、互不干扰。
Monitor 机制
关键之处在于:它为每个动态实体在固定的锚点位置部署一个“虚拟监视器”。该监视器利用 Evolution Engine 自主推进局部事件——即便相机早已不再对准它。
SLAM 空间记忆
在静态背景的累积上,LiveWorld 采用了前馈式 SLAM 框架 Stream3R。它能实时融合静态背景,支持长时间重访和任意视角变换。
状态注入生成
通过 State Adapter,将投影后的几何条件注入视频扩散模型,用以约束物体的位置、结构和运动趋势。
闭环流水线
整个流程是一个持续循环:观察新区域 → 注册动态事件 → 后台推进状态 → 用最新状态渲染画面。环环相扣,运行顺畅。

如何使用LiveWorld
当然,光有理论还不够,还需要了解实际使用步骤。
- 环境准备:先从 GitHub 克隆 LiveWorld 的代码仓库,然后安装 PyTorch、Stream3R、Qwen3-VL、SAM3 以及 Wan2.1-14B-T2V 等依赖库。
- 输入配置:准备一段前置视频帧作为初始观察,同时定义目标相机轨迹,以及描述动态实体后续行为的文本提示。
- 动态检测:系统自动调用 Qwen3-VL 和 SAM3,扫描前置帧,识别其中的活跃实体(人、动物、车辆等)。
- 监视器注册:对于每个新发现的实体,系统在其所在位置注册一个固定视角的虚拟 Monitor,作为未来视野外演化的锚点。
- 视野外演化:当相机沿轨迹移动离开后,Monitor 仍在后台利用 Evolution Engine 生成该区域后续视频,持续推进实体动作,而非冻结状态。
- 静态记忆构建:系统并行运行 Stream3R SLAM,将历史观察中的背景区域增量融合为全局静态3D点云。
- 状态渲染:相机到达目标位置后,系统取出演化后的动态4D点云和静态3D点云,投影到目标视角,再通过 State Adapter 和 Appearance LoRA 生成最终观察帧。
LiveWorld的核心优势
了解这些之后,我们再来看看它相比其他同类产品究竟强在哪里。
- 突破静态世界假设:首次从形式上定义并解决了“视野外动态”问题,打破了以往模型“只有视野内才演化”的瓶颈。
- 长时序事件一致性:在 LiveBench 基准的第二次重访测试中,VQA-Acc 达到 54.620,远超 Spatia 等竞品。
- 多事件并行推进:支持多个 Monitor 同时在视野之外演化不同事件,Full Succ. 指标可达 26%。
- 新视角几何一致:动态点云的 Chamfer Distance 被压缩至 0.135,意味着在新视角重访时能保持精准的空间位置。
- 模块化可扩展:静态记忆、动态演化、状态渲染三大模块独立运行,可单独优化或替换,灵活性极高。
LiveWorld的项目地址
- 项目官网:https://zichengduan.github.io/pages/LiveWorld/index.html
- GitHub仓库:https://github.com/ZichengDuan/LiveWorld
- HuggingFace模型库:https://huggingface.co/ZichengD/LiveWorld
- arXiv技术论文:https://arxiv.org/pdf/2603.07145
LiveWorld的同类竞品对比
下面我们拿它跟竞品 Matrix-Game-2.0 进行具体对比,差异一目了然。
视野外动态:LiveWorld 支持持续推进,实体离开视野后仍可在后台演化;而竞品不支持,实体状态会冻结在最后一次被观察到的时刻。
世界表示:LiveWorld 采用显式3D静态点云 + 4D动态实体点云;竞品采用隐式3D表示,直接从2D历史帧预测。
Same-Pose 第二次重访 VQA-Acc:LiveWorld 为 54.620,竞品仅为 5.012。
Different-Pose 第二次重访 VQA-Acc:LiveWorld 为 49.478,竞品为 4.132。
动态实体一致性 (DINO₂ₙᵈ):LiveWorld 为 0.721,竞品为 0.122。
动态点云空间一致性 (CD₂ₙᵈ):LiveWorld 仅为 0.135,竞品却高达 6.236。
技术架构:LiveWorld 演化与渲染显式解耦,形成闭环流水线;竞品将二者耦合,依赖单一视频生成器直接预测。
多事件并行处理:LiveWorld 支持多个 Monitor 同时推进,竞品缺乏独立演化机制,无法并行处理。
静态背景一致性:LiveWorld 表现优秀,依靠 SLAM 增量积累;竞品表现一般,依赖隐式记忆容易漂移。
LiveWorld的应用场景
最后谈谈实际应用。这类模型到底能在哪些领域发挥作用?
- 智能体训练:为具身智能体提供持续演化、可交互的虚拟环境,支持视野外事件推理。
- 自动驾驶仿真:模拟交通场景中不可见区域(如盲区)的动态变化,提升决策安全性。
- 交互式游戏:构建开放世界游戏,玩家离开后 NPC 和事件仍按逻辑持续推进。
- 合成数据生成:生成具有长期时序一致性和复杂事件逻辑的大规模训练数据。
- 机器人导航规划:支持机器人在探索过程中维护对未观察区域动态状态的信念。
总的来说,LiveWorld 的思路——将“世界演化”与“观察渲染”分离,并通过后台“监视器”机制管理视野外动态——为视频世界模型开辟了一条新路径。未来,这或许会成为智能仿真领域不可或缺的基础技术。