近期在探索文生视频项目时,语音合成需求成为一大挑战。恰逢 Spark-TTS 这款全新开源 TTS(文本转语音)项目发布,实测效果令人惊艳。作为后期配音工具,它已具备直接投入使用的潜力。现将项目核心特性与部署要点整理如下,供各位参考。
项目概览
Spark-TTS 是一款基于大语言模型(LLM)构建的文本转语音系统,其核心优势在于合成语音的高度自然与准确。底层架构完全采用 QWEN2.5,跳过了传统的声学特征生成流程,无需额外声码器或流匹配模型,直接从 LLM 预测的代码中重建音频。这种设计显著简化了流程、提升了效率,并降低了系统复杂度。
具体到功能层面,以下几点值得关注:
高质量的语音克隆:支持零样本(zero-shot)克隆,即便缺乏目标声音的专属训练数据,也能实现高精度音色复刻。在跨语言及语码混合场景下尤为实用,无需为每种语言单独训练模型,即可实现无缝切换。
双语支持:原生支持中文与英文,在零样本克隆模式下同样能处理跨语言和代码切换,多语言合成的自然度与准确性均表现出色。
可控的语音生成:可通过调节性别、音高、语速等参数创建虚拟说话者,灵活性极高。

安装步骤
若希望简化环境配置,可直接使用作者提供的一键包。以下仍梳理标准部署流程,供需要自行操作的同学参考:
克隆项目仓库
git clone https://github.com/SparkAudio/Spark-TTS.git cd Spark-TTS
创建 Conda 环境
conda create -n sparktts python=3.12 conda activate sparktts pip install -r requirements.txt # 国内用户可切换阿里云镜像: pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
模型下载
方式一:使用 Python 脚本下载
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
方式二:通过 Git 克隆(需预先安装 git-lfs)
mkdir -p pretrained_models git lfs install git clone https://huggingface.co/SparkAudio/Spark-TTS-0.5B pretrained_models/Spark-TTS-0.5B
启动 Web UI
python webui.py --device 0
运行后即可在浏览器中访问界面,语音克隆与语音创作两大功能均已集成。克隆功能支持上传参考音频或直接录制,操作直观便捷。
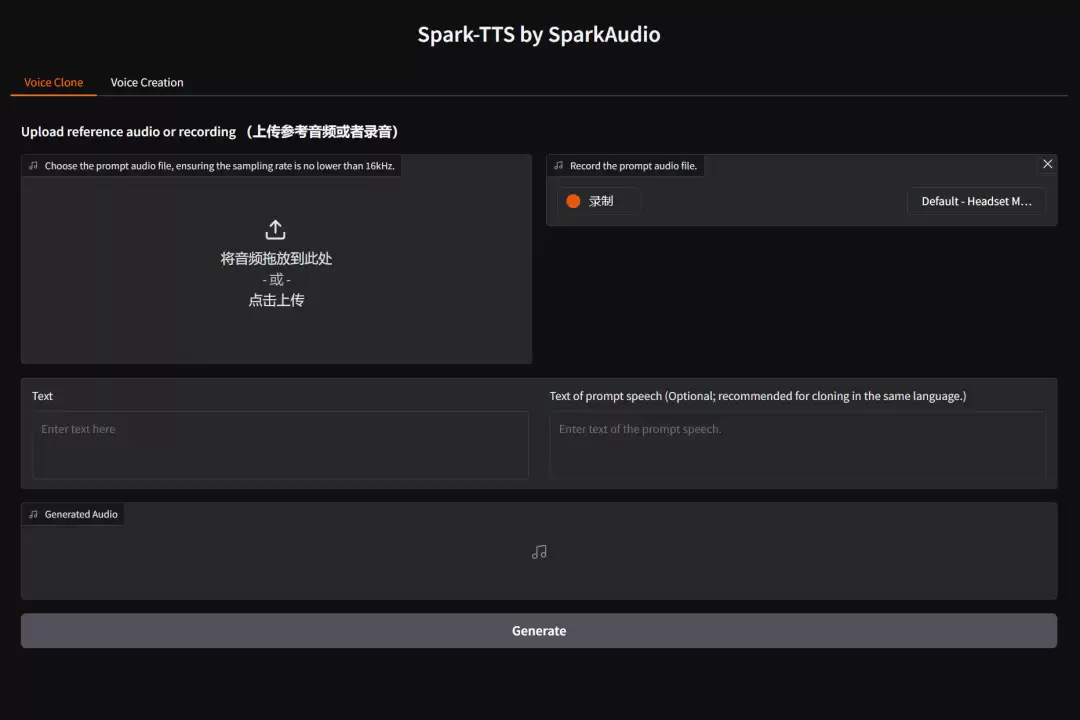
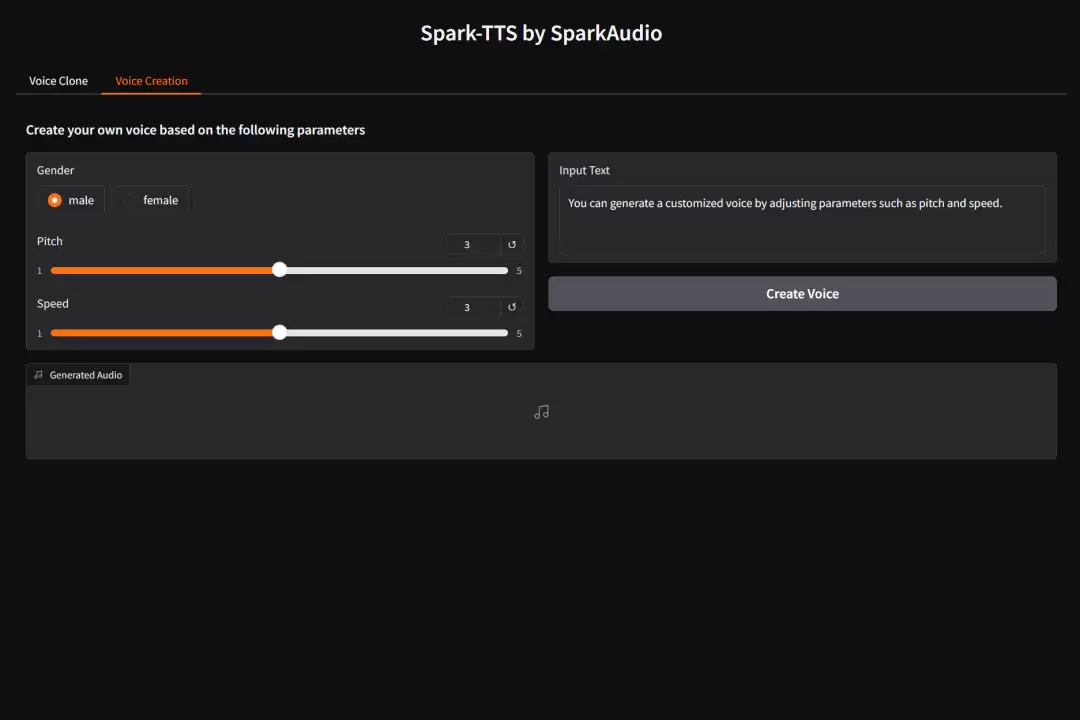
实测效果
简单测试了两组场景:
1. 步老师的声音克隆——参考音频虽短,但克隆出的音色还原度极高,语气与细节保留完整。
2. 声音创造——模拟男声——近期网上流行的奥特曼为小朋友送生日祝福的视频,于是亲自尝试。参数设置如下:
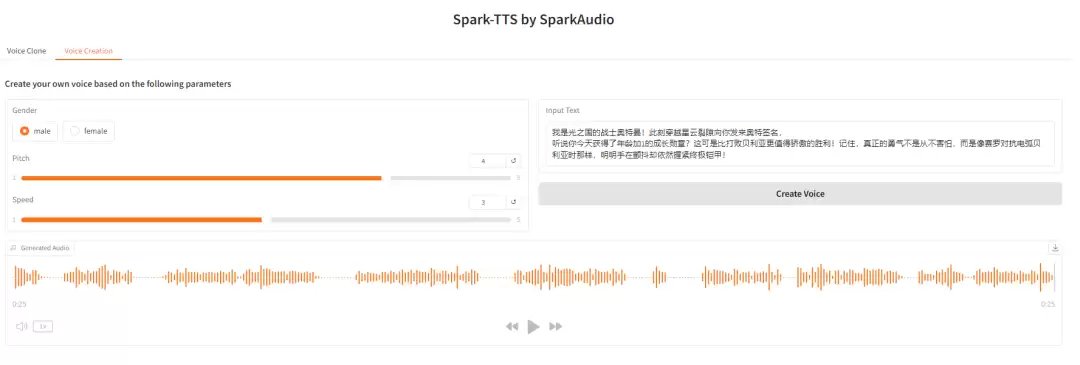
生成效果令人满意,声音的自然度与可控性均超出预期。对于需要快速合成个性化语音的场景,这款工具无疑是当前非常值得尝试的选择。