来之不易的教训:该做和不该做的事情
1. 不要用DeepSeek R1做检索
尽管DeepSeek R1的推理能力很强,但它目前并不适合用来生成嵌入——这一点需要明确。
实验数据会说话。我们对比了R1的嵌入和专用嵌入模型 Alibaba-NLP/gte-Qwen2-7B-instruct(后者在MTEB排行榜上名列前茅)的表现。具体操作是这样:分别用两个模型生成数据集的嵌入,组成各自的向量数据库,然后用同样的查询去各自库里找最相似的5个结果。
先看看“解除租约”相关的查询:
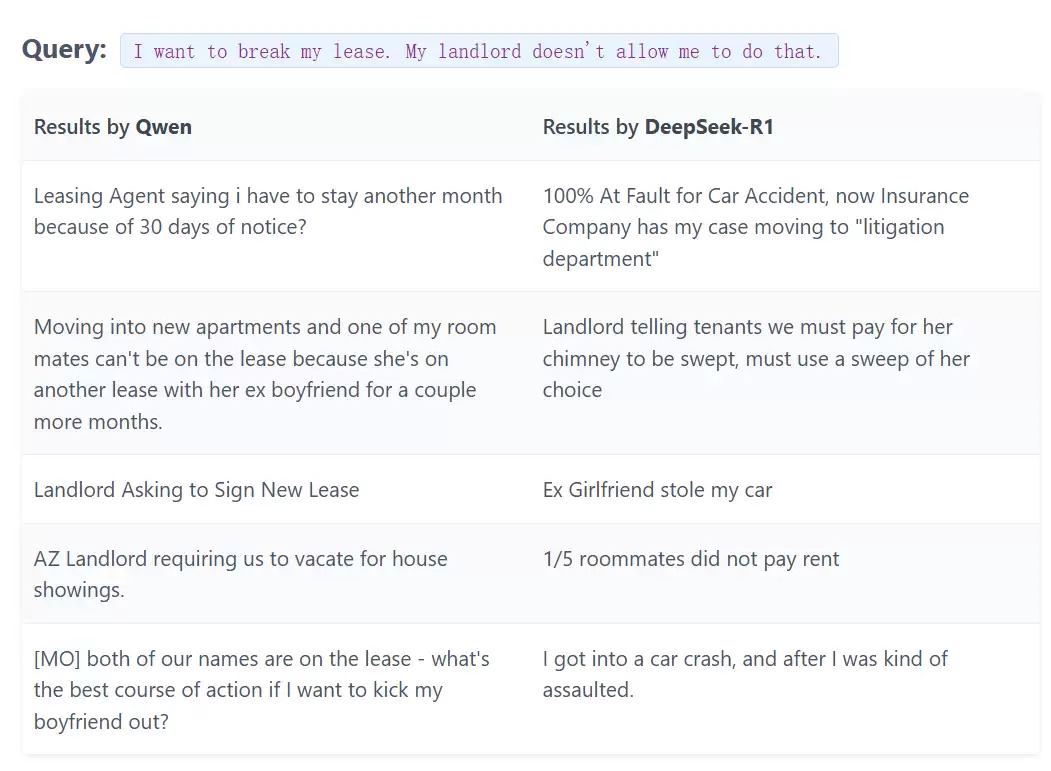
简单翻译下

再看“小额赔偿”相关的查询:
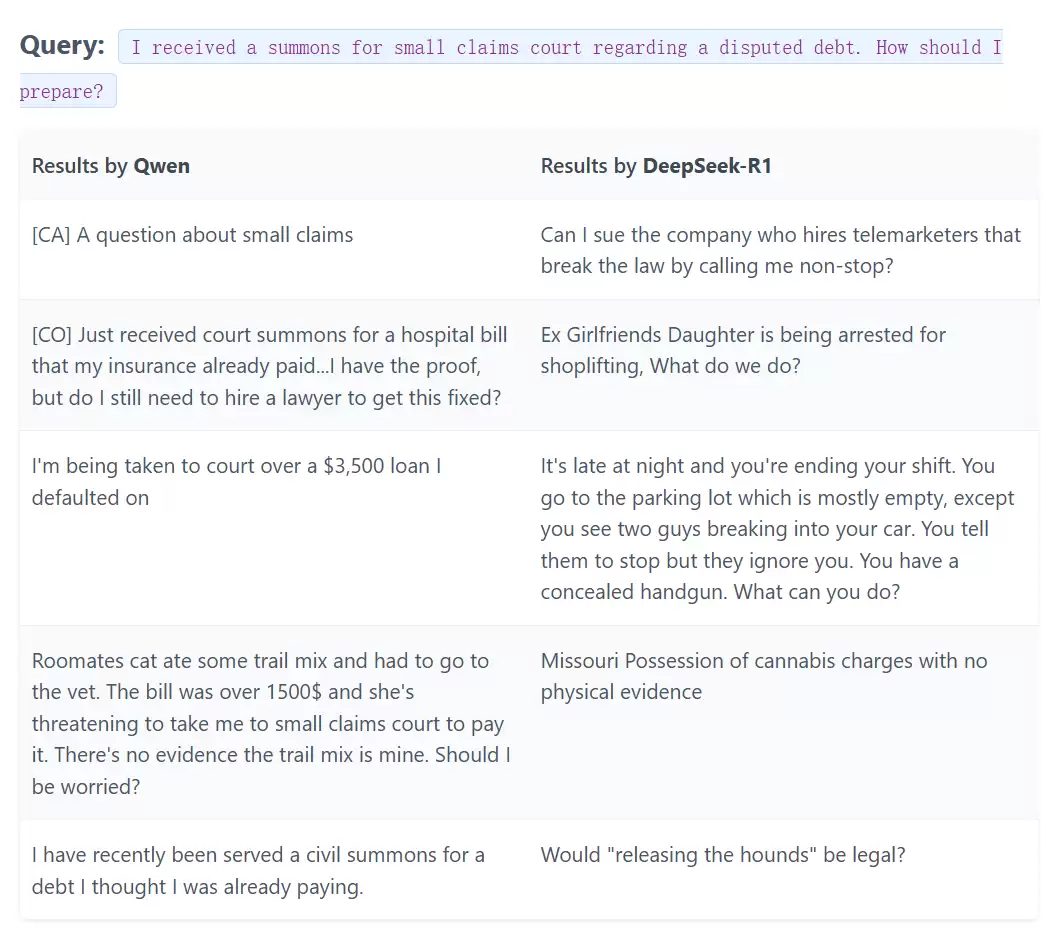
简单翻译下

从上表能清楚看到,DeepSeek R1的检索结果明显差一截。为什么?
问题的根源在于训练方式的差异。DeepSeek-R1本身就是个推理引擎,它的核心任务是顺序思考和逻辑连接,并不负责把文档映射到一个语义空间。而像Qwen2(具体来说是gte-Qwen2-7B-instruct)这类模型,专门为了语义相似性任务而生,能构建一个高维空间,让概念相近的文档无论措辞如何都彼此靠近。
这种训练上的根本差别,导致Qwen擅长捕捉查询背后的真实意图,而DeepSeek-R1有时会顺着一条推理路径走到黑,结果找回来的内容只沾个边、实际上却跑偏了。除非R1针对嵌入任务进行微调,否则不建议把它用作RAG的检索嵌入模型。
2. 务必用R1做生成:推理能力令人印象深刻
虽然R1在嵌入这块碰到了瓶颈,但它的生成能力确实出色。利用R1的思维链(CoT)方法,我们看到了几大优势:
连贯性更强:模型能综合多个文档的见解,并清晰引用相关段落。
幻觉显著减少:R1会在内部“默默推演”,通过数据的视角验证每一个结论。
来看几个实际例子:


从这些例子中可以直接感受到R1的推理能力。它的思考过程把结论如何从源文件中推导出来展现得很清楚:
R1首先会构建一个连贯的法律问题模型,这一点从它详细的思考过程就能看出来:“我记得读过关于提前终止罚款的内容……文件1提到……”这种先推理再检索的方式,让模型能有条理地将多个来源的概念联系起来。
在处理租约终止、小额索赔法庭这类复杂场景时,R1能准确理解每份文件的内容(“把这些都放在一起……”),几乎不出现幻觉。
最后,推理模型会用精确的引文来解释自己的推理链路,把结论和来源一一对应上。这就构建了一个从问题到推理再到答案的清晰链条,既保证了严谨性,也方便查阅。
我们尝试了各种法律查询,模型的表现始终如一:不只是从源文件里“提取”信息,更是在理解和“推理”。
总结:对于问答和总结这类任务,R1在处理循序渐进的法律逻辑上确实是个宝藏。就让它留在生成答案的阶段发挥作用。
3. 提示工程仍然重要
再高级的推理模型,也离不开精心设计的提示。我们的经验表明,明确的指引至关重要,尤其是在:
引导模型在生成的答案中引用文档。
采用“引用,否则就说不知道”的策略来防止幻觉。
以更用户友好的方式组织最终答案。
我们在实验过程中构建了这样一套提示:
You are a helpful AI assistant analyzing legal documents and related content. When responding, please follow these guidelines: - In the search results provided, each document is formatted as [Document X begin]...[Document X end], where X represents the numerical index of each document. - Cite your documents using [citation:X] format where X is the document number, placing citations immediately after the relevant information. - Include citations throughout your response, not just at the end. - If information comes from multiple documents, use multiple citations like [citation:1][citation:2]. - Not all search results may be relevant - evaluate and use only pertinent information. - Structure longer responses into clear paragraphs or sections for readability. - If you cannot find the answer in the provided documents, say so - do not make up information. - Some documents may be informal discussions or reddit posts - adjust your interpretation accordingly. - Put citation as much as possible in your response. First, explain your thinking process betweentags. Then provide your final answer after the thinking process.

4. 文档分块的要点
有效文档分块对提高检索准确性非常关键。合理的分块能让每个嵌入更简洁地表示特定主题,同时减少每次嵌入生成所需的Token数量。
我们采用了基于句子的拆分方法(通过NLTK库),并且在每个块的开头和结尾加入了与相邻块重叠的内容。这样有助于模型在引用某一部分时不会失去对全局的理解。以下是文档分块的代码:
def chunk_document(document, chunk_size=2048, overlap=512):
"""Split document into overlapping chunks using sentence-aware splitting."""
text = document['text']
chunks = []
# Split into sentences first
sentences = nltk.sent_tokenize(text)
current_chunk = []
current_length = 0
for sentence in sentences:
sentence_len = len(sentence)
# If adding this sentence would exceed chunk size, sa ve current chunk
if current_length + sentence_len > chunk_size and current_chunk:
chunk_text = ' '.join(current_chunk)
chunks.append({
'id': document['id'],
'name': document['name'],
'content': document['text'],
'chunk_start': len(' '.join(current_chunk[:-(2 if overlap > 0 else 0)])) if overlap > 0 else 0,
# Additional metadata fields...
})
# Keep last few sentences for overlap
overlap_text = ' '.join(current_chunk[-2:]) # Keep last 2 sentences
current_chunk = [overlap_text] if overlap > 0 else []
current_length = len(overlap_text) if overlap > 0 else 0
current_chunk.append(sentence)
current_length += sentence_len + 1 # +1 for space
要点:
用NLTK做基于句子的分词,而不是基于字符来分块。
通过块间保留重叠句子来维持文档上下文。
5. vLLM带来的效率提升
法律文件通常数据量惊人,生成嵌入可能非常耗时。一开始我们用的是HuggingFace默认的 sentence_transformer 库。在常见的Nvidia L4 GPU上,第一道坎就是经典的“CUDA内存不足”。即便换到Nvidia A100,sentence_transformer也要吃掉57GB的显存才能完整加载 Alibaba-NLP/gte-Qwen2-7B-instruct 模型。
后来我们改用了vLLM,一个高吞吐量、内存高效的LLM推理和服务引擎。在标准Nvidia L4 GPU上,vLLM只用了大约24GB显存就运行起来了,而L4的价格要比A100便宜得多——在GCP上,L4每小时只要0.7美元左右,A100至少2.9美元。
我们还在80GB显存的A100上对比了vLLM和sentence_transformer,结果vLLM生成嵌入的速度提高了5.5倍。对于一个包含1万份法律文件、共计1.5万个块的语料库,处理时间从sentence_transformer的5.5小时,直接降到了vLLM的1小时。
结论
给法律文件构建DeepSeek R1 RAG这件事,归结起来就是几点:
检索要用专业模型,比如Qwen2。
生成阶段大胆用R1的推理能力来处理复杂法律问题。
提示工程依然是控制引文和结构的关键。
vLLM能大幅提升推理效率,无论是速度还是成本。
这一点,我在实验过程中体会尤深。