当今最具热度的前沿技术非人工智能(AI)莫属,而AI的核心正是机器学习(ML)。可以说,掌握了机器学习,就等于掌握了人工智能的核心技术。
对于工业领域的用户而言,如何将机器学习成功引入自动化场景,并打破传统自动化技术的瓶颈?面对人工智能、机器学习、深度学习、神经网络等看似深奥的概念,该如何快速理解并掌握呢?
今天,只需五分钟,我们就将机器学习的概念、关键技术及其在工业自动化中的应用一一理清。让我们先从一个小案例入手,了解机器学习在运动控制中的实际作用。
首先,通过一个利用机器学习优化运动控制的案例,建立对机器学习的直观认知。
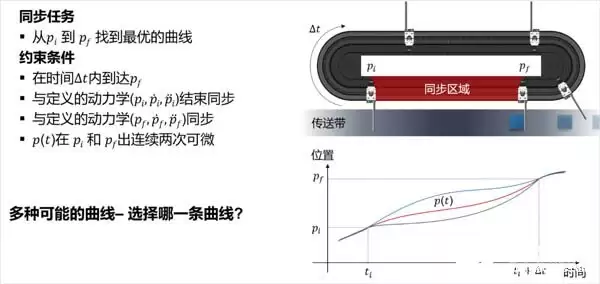
请看两条相同的直线加圆弧传输轨道:左侧轨道上的工件输送平稳流畅,而右侧轨道则加速急促,产品几近被甩出。这不仅影响工件质量,还加剧了轨道磨损。显然,右侧的运动曲线设计远不如左侧。
那么,如何设计出左侧那样的曲线?这就需要机器学习介入:通过采集工件多次运行中的速度、加速度、位置等数据,构建数据模型,并持续进行优化(训练),最终获得最优运动曲线。为何必须依赖机器学习?因为这类曲线没有现成公式(非正圆、椭圆或渐开线),也无法通过数学方程直接计算,只能借助“算法模型+训练”来求解。
通过这个案例,您应该对机器学习的作用有了初步认识。接下来,我们来理解几个常见概念。
人工智能(AI)——具备模拟人类智力的能力,分为弱AI和强AI,当前阶段仍为弱AI。
机器学习(ML)——实现弱AI的一种方式,基于可通过“训练数据”学习特定任务的数学模型进行优化。
深度学习(DL)——以深度神经网络(DNN)为核心,需要大规模数据集训练,适用于复杂的视觉应用等领域。
三者的关系是包含关系,如下图所示:
简单来说,机器学习是根据各类算法建立数学模型,利用数据反复训练模型以提升准确性,最终将训练好的模型部署到实际应用场景中进行推理计算,从而解决传统数学方法难以处理的复杂问题。
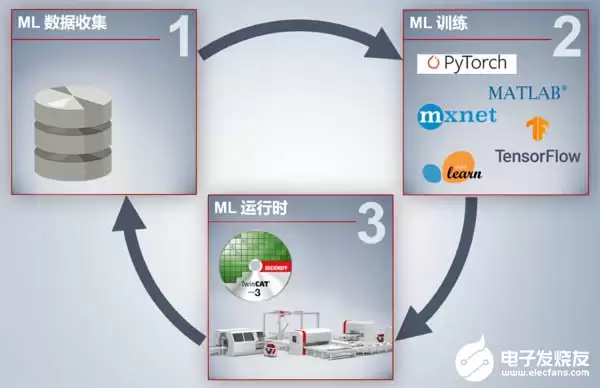
因此,将机器学习引入工业自动化可归纳为三个步骤:收集工业现场数据、构建并训练模型、将模型下载到实际应用中运行。如下图所示:
看起来是不是很简单?当然,实际应用远没这么简单——每个环节都涉及专业知识和工具。下面逐一展开,帮你不仅入门,还能成为“专家”。
第一步:收集工业现场数据
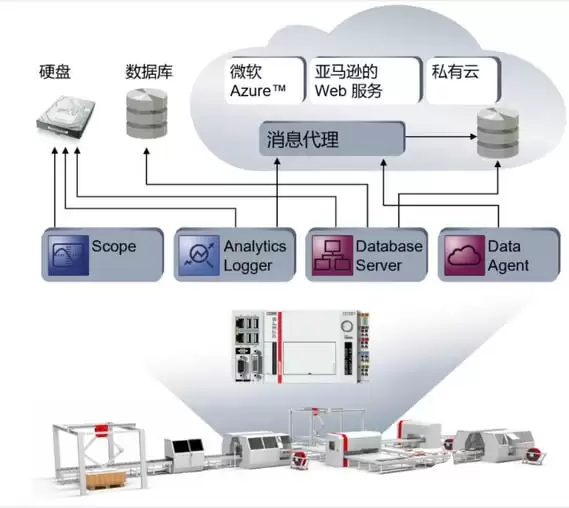
在数据采集阶段,需要通过各类传感器和测试测量工具获取现场数据。这一环节会用到自动化控制中的多种产品,例如倍福的TwinCAT3 Scope、TwinCAT3 Database Server、TwinCAT3 Data Agent和TwinCAT3 Analytics Logger等工具,利用它们将数据采集到本地数据库或云端存储、呈现,为后续建模和训练做好准备。
第二步:模型的搭建和训练
这一步至关重要,也是当前机器学习中最复杂、研究最密集的环节。首先需要对上一步采集到的数据进行预处理:数据清洗去除异常值,数据转换或数据集成等。然后选择特征数据确定数学模型,进行学习微调,并用未知数据验证模型。模型训练完成后,导出可供TwinCAT3等模型运行环境使用的描述文件:XML文件或ONNX文件。在这一步中,特征数据的挖掘——即提取哪些数据进行建模——是整个机器学习成败的关键,通常需要具备行业知识和经验的专业人士来完成。
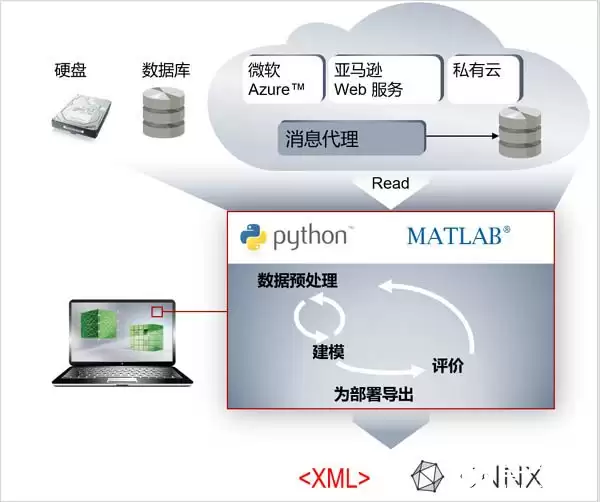
搭建模型时,往往需要借助第三方框架(平台工具),例如:Python SciKit、MATLAB Machine Learning Toolbox,以及深度学习框架TensorFlow(谷歌)、Keras(TensorFlow前端)、PyTorch(脸书)、MxNet(亚马逊)、CNTK(微软)、MATLAB Deep Learning Toolbox(MathWorks)等,其中大部分是开源且基于Python的。

除了框架,数学模型的选择与构建也非常关键。从数学角度看,可将万事万物的问题划分为两大类:回归问题和分类问题。回归问题通常用于预测一个数值,如房价预测、未来天气预测等。分类问题则用于给事物打标签,结果通常是离散值,例如判断图片中的动物是猫还是狗。解决这两类问题需要不同的数学模型,比如支持向量机(SVM)、神经网络、决策树与随机森林、线性回归、贝叶斯线性回归等,这些模型在框架中都已封装,可以直接调用。
这里还需介绍一个知识点:ONNX(开放神经网络交换文件)。这是一种专为机器学习设计的开放式文件格式,用于存储训练好的模型,使不同人工智能框架(如Pytorch、MXNet)能够采用相同格式存储模型数据并实现交互。ONNX主要由微软、亚马逊、Facebook和IBM等公司共同开发。

第三步:加载模型到控制器里运行
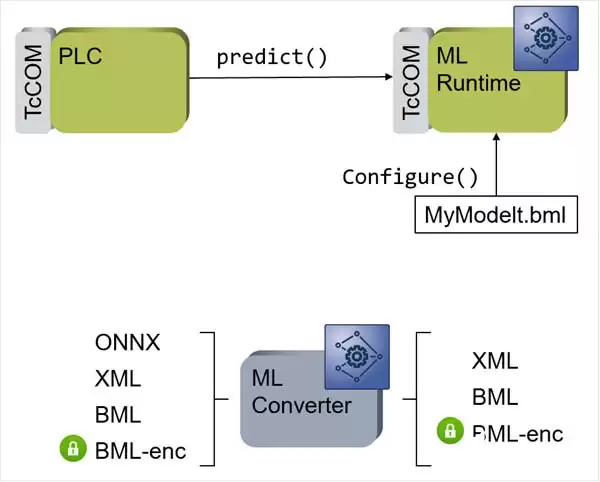
模型搭建和训练完成后,最后一步就是将模型加载到工业电脑或控制器中运行计算。模型描述文件并不能被工业控制器直接识别,因此需要借助倍福TwinCAT 3这类自动化控制软件平台作为引擎,将训练好的模型文件加载到控制器中,从而在自动化场景中应用机器学习。
目前,TwinCAT 3已无缝集成机器学习引擎接口。通过机器学习文件转换器(ML Converter)可将训练生成的XML或ONNX文件转换为BML(倍福机器学习文件)进行加密保护,经TwinCAT 3的ML Runtime加载后,训练好的模型即可被TwinCAT TcCOM对象实时调用执行,同时也能被PLC、C/C++封装的TcCOM接口调用。如果神经网络规模较小,例如权值大小为10K的多层感知器(MLP),可在亚毫秒级任务周期内多次调用,保障实时性。
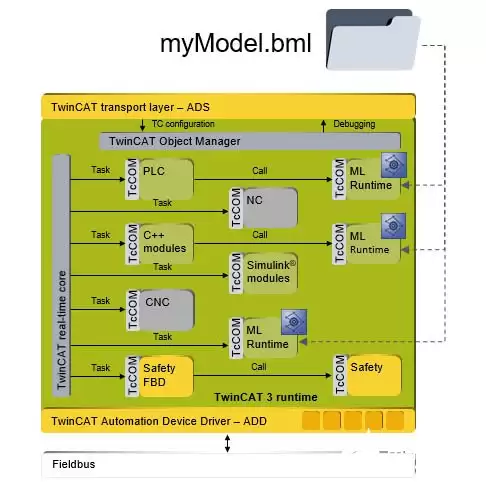
TwinCAT 3本身提供的多核技术支持同样适用于机器学习应用——不同任务程序可访问同一个特定的TwinCAT 3推理引擎而互不干扰。机器学习应用完全能够访问TwinCAT中所有可用的现场总线接口和数据,从而可利用大量数据进行推理计算。
TwinCAT 3目前提供两个机器学习推理引擎:TF380x TC3(经典机器学习模型推理引擎,包括支持向量机SVM、主成分分析PCA、k均值k-means等)和TF381x TC3(神经网络NN推理引擎,包括多层感知器MLP、卷积神经网络CNN、长短期记忆模型LSTM等)。
举个例子:最优运动曲线是如何“机器学习”出来的
回到文章开头那个传输轨道最优运动曲线的问题,看看具体如何通过机器学习进行优化。
首先,将运动曲线优化问题转化为数学问题:在给定时间内,从pi顺时针运动到pf,找到最优(最平滑)的运动曲线,并尽量使加速度最小。
第一步:采集数据,包括工件的位置、速度、加速度、时间等信息,将这些数据收集并存储起来,为后续优化提供基础。

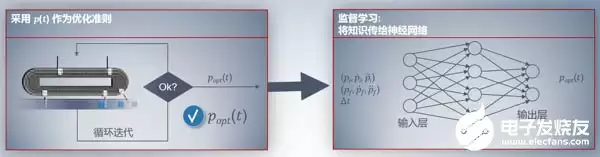
第二步:提取步骤一中的特征数据建立模型,以某个优化准则(如最小化加加速度)为目标,通过神经网络算法循环迭代,采用监督学习方式训练模型。
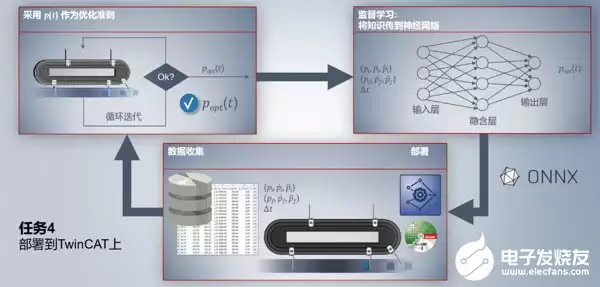
第三步:将训练好的模型通过ONNX文件部署到TwinCAT 3中,从而通过控制器实现最优运动曲线的实时控制。
另一个例子:一个不需要故障数据的风扇异常检测
通常,通过大数据分析进行预测性维护,需要大量故障数据。然而在工业实际场景中,故障数据往往稀缺——例如一台风机在初期几年很少出现故障,只有在后期才会产生故障数据。利用机器学习,可以解决这一难题:在无需故障数据的情况下实现异常检测。
例如,要检测下图中服务器工作站上的风扇是否存在异常,可以通过机器学习来完成。
首先,通过TwinCAT 3 Scope采集大量风扇正常运行时的压力、转速、振动等数据。然后使用MATLAB读取这些数据,并采用one-class SVM(一类支持向量机)模型进行训练。当模型学习了大量正常数据后,会自动生成一个正常数据的边界。最后将模型从MATLAB导出为ONNX文件,转换后加载到控制器的TwinCAT 3中。这样一来,当实时采集的数据超出该边界时,控制器即可判定风扇出现了异常状况。
这个应用看似简单,但其最困难的部分在于特征数据的挖掘与提取——即常说的特征工程。至于数据采集、模型创建与训练,以及最终在控制器上的运行,已有许多成熟的工具和平台可供使用,例如MATLAB和倍福的TwinCAT 3。站在这些“巨人”的肩膀上,您只需聚焦于工业现场知识与经验,便能轻松将机器学习这一前沿技术引入工业自动化领域。